
Special Articles on AI Services—Document and Image Processing Technologies—
Speech DX Platform Pioneers Speech Data Usage
Speech Data Utilization Speech Recognition Emotion Recognition
Mariko Chiba, Yuuki Saito, Taku Kato, Aogu Yamada and Masaki Yamagata
Service Innovation Department
Abstract
With the rise of LLMs, the use of AI in business is accelerating. Although further utilization of various data in business scenes is desired to promote data-driven management, the use of speech data, which records voice communication among humans, is still limited. NTT DOCOMO is working on the development of a “Speech DX Platform” that can analyze speech data from multiple perspectives, with the aim of contributing to improved work efficiency and productivity in all situations involving speech communication, including face-to-face and online meetings. This article provides an overview of the technology incorporated in the Speech DX Platform and examples of its use.
01. Introduction
-
Voice communication is one of the most basic ways for humans to ...
Open

Voice communication is one of the most basic ways for humans to convey information. Even in this age of widespread use of e-mail and text chat, communication is often still done through the voice. Voice communication allows for immediate exchange of information and can also convey emotions and nuances through non-verbal information such as tone of speech and rhythm of dialogue, thereby deepening empathy and understanding with others. Such non-verbal information plays an important role in interpersonal communication, therefore, to promote Digital Transformation (DX)*1 in business, it is important to accumulate and accurately analyze speech data that contains a variety of information that cannot be expressed in text transcriptions of conversations.
While speech recognition technology, which transcribes utterances into text, is widely used through speech agents in smartphones and text transcription functions in Web conferencing systems, the technology for extracting various types of information, including non-verbal information, from speech data is still in the process of being studied to utilize.
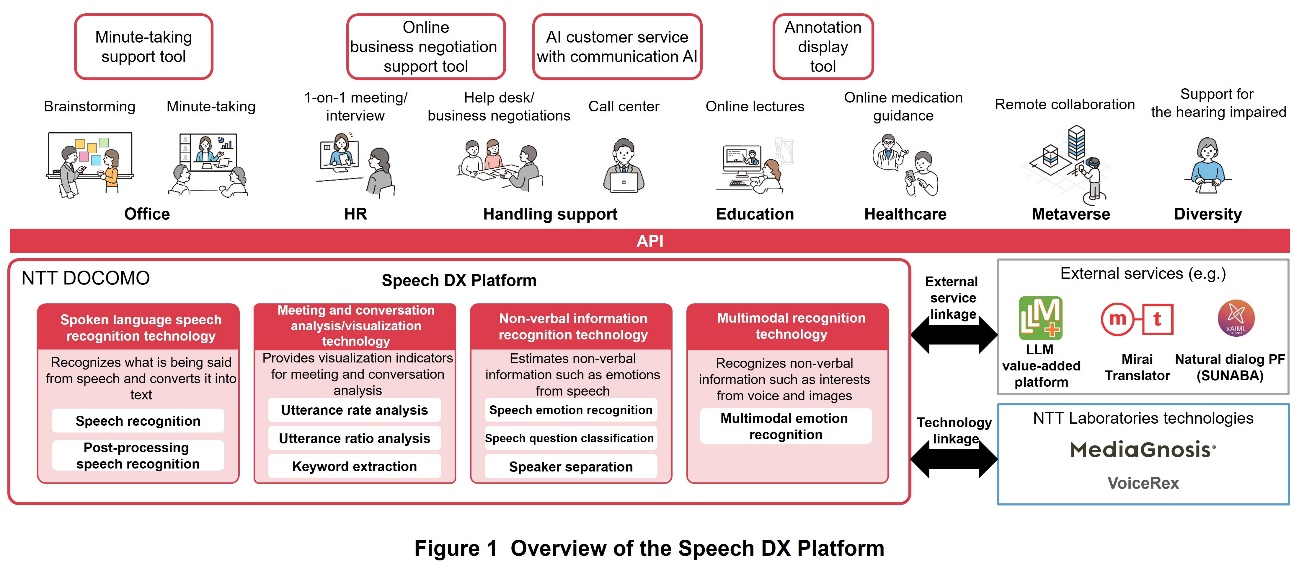
To promote the use of speech data in business, NTT DOCOMO is working on the development of a “Speech DX Platform” that can analyze speech data from multiple angles, including text, emotions, and speech characteristics (Figure 1). The Speech DX Platform is a platform that aggregates speech analysis AI assets*2 for efficient verification of the practicality of speech analysis technologies that extract text and emotion of utterances from speech data for analysis. It has two main features.
The first is standardization of interfaces by aggregating speech analysis AI assets. By consolidating various AI assets related to speech analysis onto a single platform and making them available through a common interface, the cost of deploying new speech analysis technologies in technology validation and service development can be reduced.
The second is a rich lineup of speech analysis AI assets for a wide range of speech data applications. In addition to various speech analysis technologies such as speech recognition, speech emotion recognition, multimodal*3 emotion recognition (a combination of speech emotion recognition and facial emotion recognition), and speaker separation, the Speech DX Platform includes post-processing to improve readability of speech recognition results, keyword extraction from speech recognition results, and functions associated with speech analysis using speech analysis results such as utterance ratio analysis for individual meetings. While these functions are based on technologies from NTT Laboratories, NTT DOCOMO has implemented them on its own to improve their practicality.
This article provides an overview of the technology incorporated in the Speech DX Platform and examples of its use.
- DX: The use of IT technology to revolutionize services and business models, promote business, and change the lives of people for the better in diverse ways.
- Assets: Specifically, technology assets.
- Multimodal: Multiple types of information. In this article, this refers to the handling of multiple media data, such as speech and image data, as input information.
-
An overview of the configuration of the Speech DX Platform is shown ...
Open
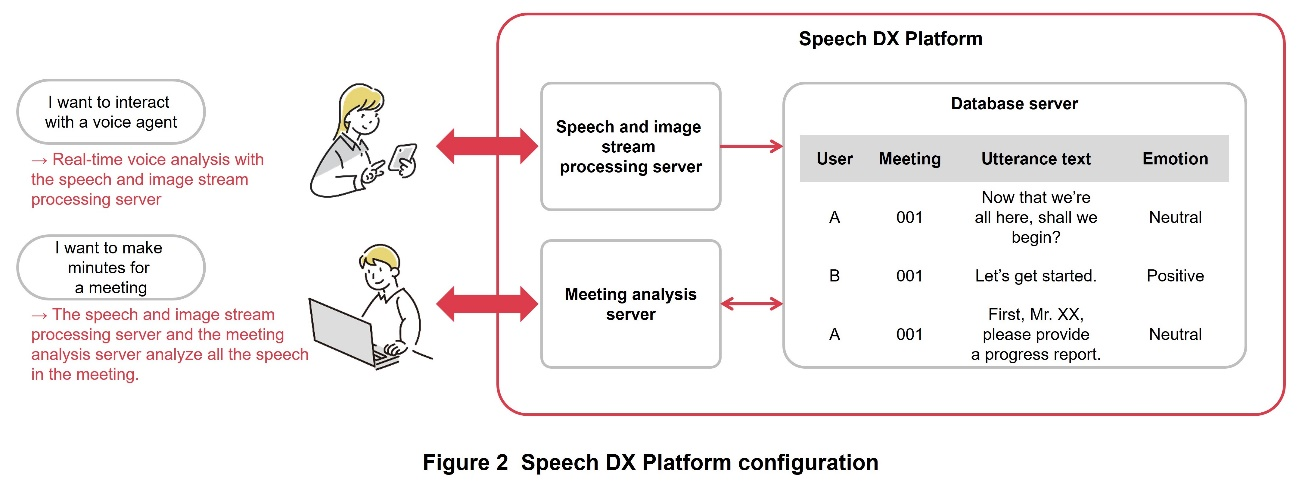
An overview of the configuration of the Speech DX Platform is shown in Figure 2. The Speech DX Platform consists of a speech and image stream processing server for real-time analysis of speech and image streams, a meeting analysis server that analyzes multiple utterances together, and a database server.
The speech and image stream processing server divides speech data into utterances based on voice activity detection and performs parallel processing to extract linguistic information such as utterance content text and non-verbal information such as emotion. This allows the user to obtain the results of analysis (extraction processing) by multiple speech analysis AIs in a single communication session*4. The speech and image stream processing server was developed using the same speech stream processing technology used in my daiz*5 [1] and the DOCOMO AI Agent API® (Application Programming Interface)*6 [2]. It can also be used in cases that require real-time performance, such as speech dialogue agents.
The speech analysis results for each user and each speech segment analyzed by the speech and image stream processing server are stored in the database server. The meeting analysis server analyzes the speech analysis results of an individual meeting together in the database. By analyzing multiple speakers and multiple utterances together, it is possible to extract information related to the overall state of a meeting, such as who among meeting participants spoke a lot and what keywords were spoken during the meeting.
Combining the speech and image stream processing server with the meeting analysis server makes it possible to obtain the results of speech analysis for each user in real time, or to perform analysis on all the utterances spoken in an entire meeting. In addition, the Speech DX Platform can be used in a variety of cases because the various speech analysis technologies and functions associated with speech analysis on the platform are selectable.
- Communication session: A series of communications exchanged between a client and server.
- my daiz: A speech dialogue agent that runs on smartphones and tablets, providing a wide range of information tailored to user needs. “my daiz” and the my daiz logo are trademarks of NTT DOCOMO, INC. registered in Japan.
- DOCOMO AI Agent API: As part of NTT Group’s AI technologies under the “corevo®” brand name, this is an interactive AI-based Application Service Provider (ASP) service that provides a packaged voice-based user interface. It can be used to achieve complex interactive scenarios by creating simple dialogue on a GUI and using Artificial Intelligence Markup Language (AIML). It can also be used to respond to common inquiries as a chatbot for FAQ use that automatically generates interactive scenarios from question Q&A lists. “corevo” is a trademark of Nippon Telegraph and Telephone Corporation registered in Japan and other countries. “DOCOMO AI Agent API” is a trademark of NTT DOCOMO, INC. registered in Japan.
-
The functions of the Speech DX Platform are realized by combining technologies ...
Open
The functions of the Speech DX Platform are realized by combining technologies researched and developed at NTT Laboratories and NTT DOCOMO’s proprietary technologies. As speech analysis AI assets, functions such as speech recognition, speech emotion recognition, facial emotion recognition, speaker separation, utterance rate analysis to analyze the user’s speaking speed, and keyword extraction to detect the utterance of pre-registered words are available for the speech and image stream processing server. For the meeting analysis server, functions such as word bubble analysis and utterance ratio analysis, which calculates the ratio of speaking time for each user in a meeting, are available. Advanced text processing through external API linking*7 such as summary processing using a Large Language Model (LLM)*8. This article describes five technologies: speech recognition, speech emotion recognition, facial emotion recognition, speaker separation, and word bubble analysis.
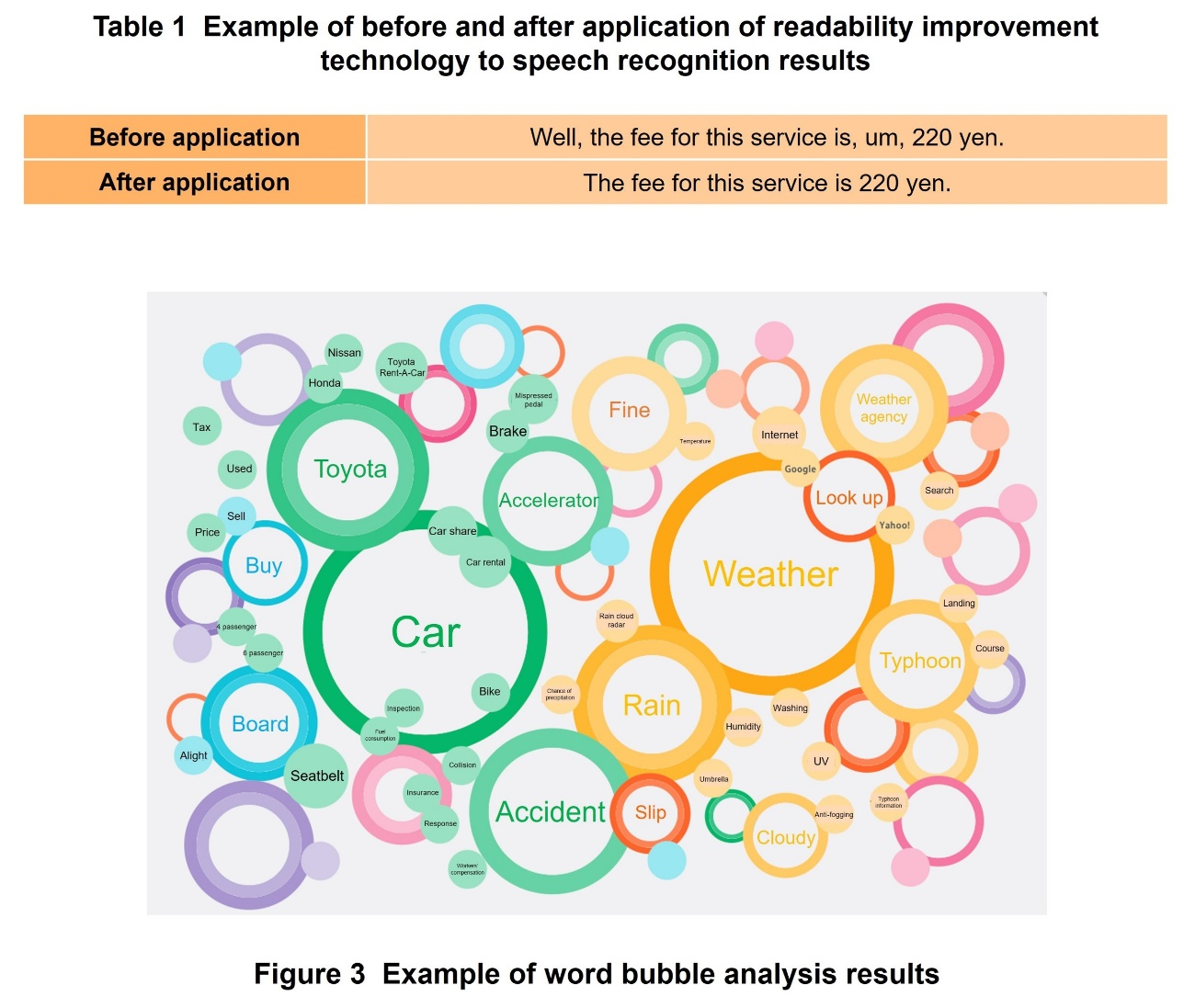
In the speech recognition technology, which converts speech into text, the AI learns speech data collected by NTT DOCOMO using technology developed in the research and development of speech information processing at NTT Laboratories [3]–[7] to achieve more accurate text conversion in real usage environments. By also combining the technologies developed by NTT DOCOMO to improve readability, it is possible to provide text that is more readable to the user, as shown in Table 1, for example.
The speech emotion recognition and facial emotion recognition technologies use MediaGnosis® [5][6][8], a next-generation media processing AI developed by NTT Laboratories, to estimate non-verbal information such as emotions from speech and images. The AI learns from speech and image data collected by NTT DOCOMO, which is close to the actual usage environment, and builds an estimation model for each speech and image. As well as analysis of speech or images, multimodal processing that combines the results of both types of analysis is also available.
The speaker separation technology uses speaker features*9 that can be output by MediaGnosis to separate speech of each speaker when multiple people are speaking. This technology makes it possible to classify input speech while automatically estimating the number of speakers in real time. Even in situations where multiple people are speaking into a single microphone, it is possible to separate and analyze each speaker.
Word bubble analysis technology is used to visualize what is said in a meeting. The content of the conference participants’ speech is analyzed, and each word is mapped onto a two-dimensional plane as shown in Figure 3, based on the frequency of utterance of the word, the degree of similarity between words, and the degree of co-occurrence*10, which indicates which words are likely to be uttered in the same sentence. The frequency is expressed by the size of the circle containing the word, and the similarity between words is expressed by the distance between words. Categorization of each word by cluster*11 analysis is also performed, and words in the same category are drawn in the same color. This function can also display words that are similar or related to words that were said during the meeting. We believe this function can be used not only for reviewing the content of meetings, but also for assisting the generation of ideas in brainstorming, for example.
- External API linking: Linking of different programs or software from different systems or services via a predefined interface.
- LLM: A model of natural language processing built using a large amount of text data. Can be used for more advanced natural language processing tasks than conventional language models.
- Speaker features: Speaker-specific information extracted from speech waveforms. Used in speaker identification and speaker matching.
- Co-occurrence: Frequency of simultaneous occurrence of certain words in the same sentence.
- Cluster: A set of data with similar properties or characteristics grouped together.
-
4.1 Minute-taking Support Tools
Open
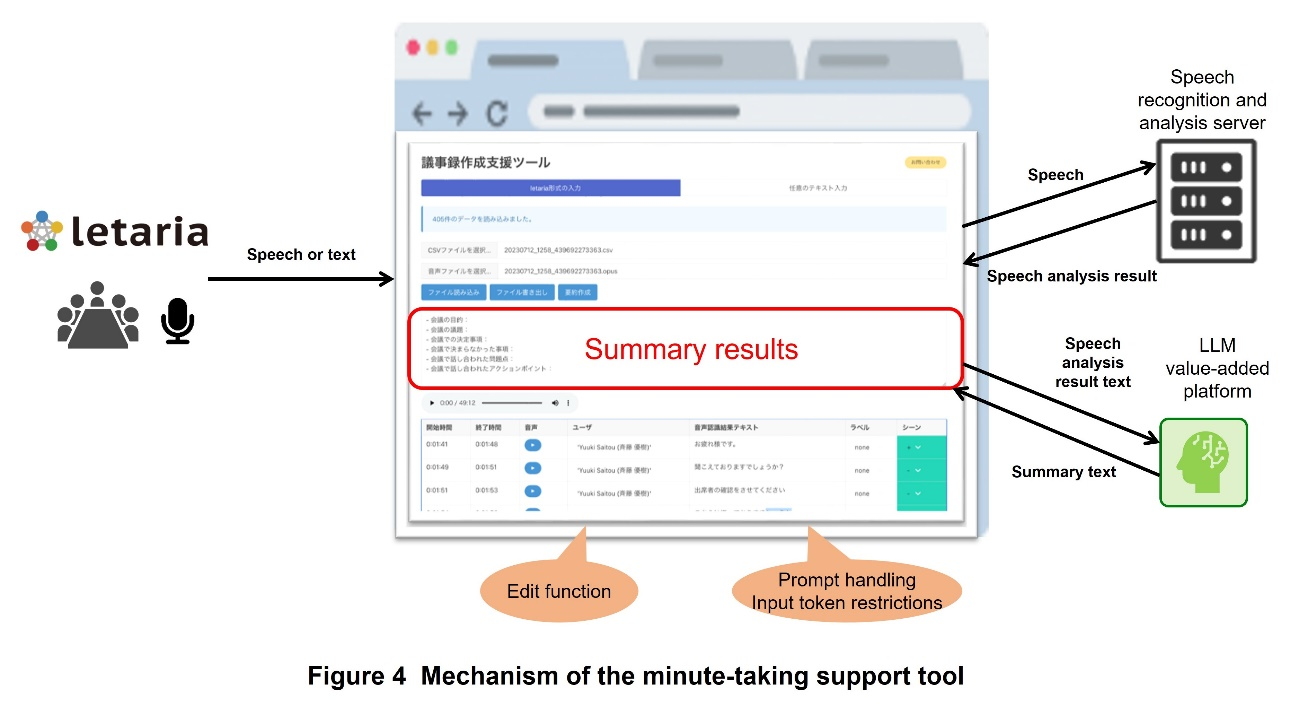
The time and effort required to take meeting minutes continues to be a major burden. To solve this problem, NTT DOCOMO has developed a new minute-taking support tool that summarizes the speech and text content of meetings and other events (Figure 4). This tool converts speech from meetings and other events into text by analyzing it on a speech recognition and analysis server and summarizes the text content on an LLM value-added platform. This will improve the efficiency of minute-taking and enable a significant reduction in the time for writing minutes.
This tool has the following features.
- 1) Web Application for Users
The minute-taking support tool is published as a Web application built in NTT DOCOMO’s internal network and is easily accessible to all employees who are permitted to connect to the internal system. This allows users to smoothly take and check minutes. - 2) Various Input Formats
The tool supports several input formats. Any text containing notes of proceedings made at meetings can be used. Audio files and text files of speech recognition results using the letaria [9] conferencing tool can also be used. This allows users to enter information in any way they wish. - 3) Use of LLM Value-added Platform [10]
The system uses the powerful capabilities of an LLM to assist in summarizing the minutes. Without being aware of the prompts*12 that need to be input to use an LLM, users can receive a summary by having the summary run on the UI, utilizing the prompts built into the system. This eliminates the need to create new prompts and makes the use of an LLM easy. - 4) Efficient Summary Processing
The tool supports the LLM input token*13 restriction and is equipped with a mechanism that divides the input text into multiple pieces of a certain text length, summarizes them, and finally combines the results into a single summary. This makes efficient use of LLM resources and produces high-quality summaries.
4.2 Online Business Negotiation Support Tool
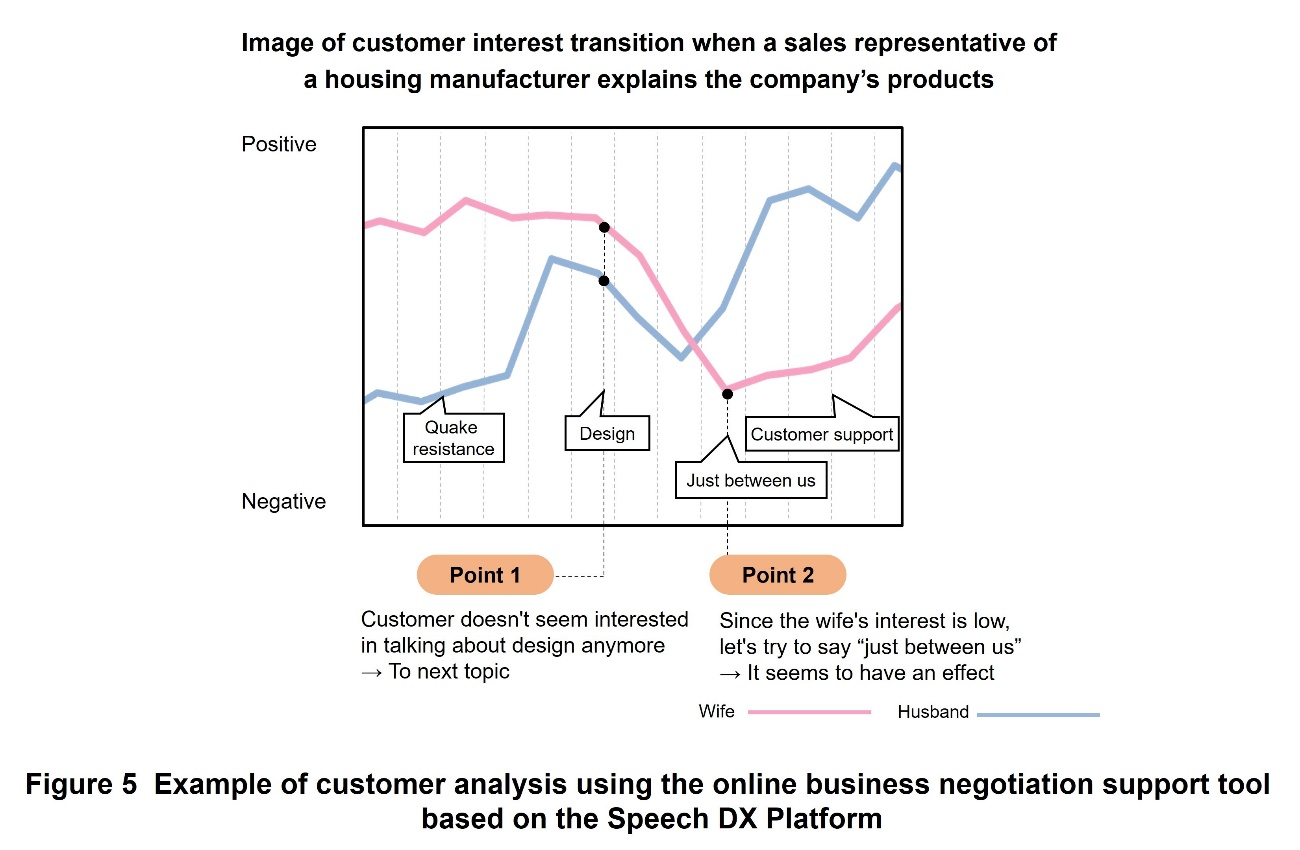
One example of the use of the Speech DX Platform is online business negotiation support. With the spread of telework triggered by the COVID-19 pandemic, the introduction of online business negotiations has increased rapidly in many companies. Compared to conventional face-to-face business meetings, however, online business meetings have the problem of difficulty in capturing the other party’s response. Specifically, it is difficult to grasp the customer’s reaction because the customer’s face on the screen is small even if the camera is on, and the sales representative is occupied with explaining the materials projected on the screen during the presentation.
NTT DOCOMO aims to support online business negotiations by detecting and visualizing the customer’s reactions of interest in real time, utilizing the speech recognition and facial emotion recognition of the Speech DX Platform. Figure 5 shows an example of customer analysis using the online business negotiation support tool based on the Speech DX Platform. In this example, we assume a scene in which a sales representative of a housing manufacturer is explaining the company’s products to customers (a wife and husband) in an online business negotiation. This online business negotiation support tool has the following two functions to support sales representatives.
- Camera images acquired from the customer’s PC are analyzed using the Speech DX Platform’s facial emotion recognition, and the results (positive/negative probability) are displayed as a time-series graph.
- Microphone audio acquired from the sales representative’s PC is analyzed by the Speech DX Platform, and the extracted keywords are displayed.
For example, when the sales representative begins to explain “design,” if the customer’s response seems to shift from positive to negative, as shown in point 1 of Fig. 5, the sales representative can decide to switch to the next topic. When the customers do not respond well, as in point 2 of Fig. 5, the sales representative tries saying the keyword “just between us,” and if the customer’s response turns positive, it can be judged that the “just between us” approach is effective in developing this business negotiation. As described above, the speech recognition and facial emotion recognition of the Speech DX Platform can be used to support sales representatives in selecting the optimal sales scenario.
4.3 Annotation Display Tool
An example of an application that supports understanding of content in situations where technical terms or jargon are frequently used is an annotation display tool that utilizes the speech recognition and keyword extraction functions of the Speech DX Platform.
In university lectures that deal with specialized content or in company meetings where lots of jargon are used, differences in background knowledge of the words used can make the content difficult to understand. The psychological hurdle to asking questions about the meaning of words is also high in lectures and meetings with large numbers of participants, and it is also difficult for the speaker to accurately assess the audience’s understanding.
When keywords registered in advance are spoken, an application called annotation display tool displays the keywords and their explanations as annotations. Using the annotation display tool should enable the listener to use the displayed annotations to supplement their basic knowledge of unfamiliar words and help them understand the content, while the speaker is speaking as usual. It is also possible to display annotations according to the listener’s level of understanding by setting levels and categories.
- Prompt: Instructions or input text that the user inputs when operating generative AI.
- Token: A character or character string treated as the smallest unit of text.
- 1) Web Application for Users
-
This article has described the features of the Speech DX Platform, which aggregates ...
Open
This article has described the features of the Speech DX Platform, which aggregates NTT DOCOMO’s speech analysis AI assets, and examples of its use. Making various speech analysis AI assets such as speech recognition, speech emotion recognition, and multimodal emotion recognition available through a common interface enables them to be used in a wide range of scenarios.
The development of services utilizing the Speech DX Platform is also progressing, with MetaMe [11] exhibited at docomo Open House’24 [12] and an AI customer service system with communication AI*14 implementing speech dialogue based not only on the user’s speech text but also on non-verbal information such as emotion and speech speed.
In the future, in addition to further expanding speech analysis AI assets, we will continue to verify the effectiveness of these technologies through internal and external demonstration experiments and thereby contribute to the promotion of speech data-driven DX.
- AI customer service system with communication AI: A speech dialogue avatar system that responds to customers based on their emotional and behavioral characteristics. Unlike conventional speech dialogue systems, the AI customer service system uses not only the user’s speech text, but also non-verbal information such as the user’s utterance rate and the user’s emotions, which can be obtained from the user’s speech and facial images, as cues for generating system responses.
-
REFERENCES
Open
- [1] NTT DOCOMO: “my daiz” (in Japanese).
https://www.docomo.ne.jp/service/mydaiz/ - [2] NTT Communications: “DOCOMO AI Agent API®” (in Japanese).
 https://www.ntt.com/business/services/ai_agent_api.html
https://www.ntt.com/business/services/ai_agent_api.html - [3] NTT: “Speech information processing”
https://www.rd.ntt/e/hil/category/voice - [4] NTT: “VoiceRex®,” an ever-evolving speech recognition engine” (in Japanese).
https://www.rd.ntt/research/JN20190709_h.html - [5] NTT: “Multimodal Web Application Based on Next-generation Media Processing AI “MediaGnosis®” Now Available to the Public” (in Japanese).
https://group.ntt/jp/topics/2022/11/16/rd_mediagnosis_demo.html - [6] NTT: “MediaGnosis® Next Generation Media Processing AI” (in Japanese).
https://www.rd.ntt/mediagnosis/ - [7] R. Masumura, Y. Yamazaki, S. Mizuno, N. Makishima, M. Ihori, M. Uchida, H. Sato, T. Tanaka, A. Takashima, S. Suzuki, S. Orihashi, T. Moriya, N. Hojo and A. Ando: “End-to-End Joint Modeling of Conversation History-Dependent and Independent ASR Systems with Multi-History Training,” Proc. of Annual Conference of the International Speech Communication Association (INTERSPEECH), pp. 3218–3222, 2022.
- [8] A. Takashima, R. Masumura, A. Ando, Y. Yamazaki, M. Uchida and S. Orihashi: “Interactive Co-Learning with Cross-Modal Transformer for Audio-Visual Emotion Recognition,” Proc. of Annual Conference of the International Speech Communication Association (INTERSPEECH), pp. 4740–4744, 2022.
- [9] NTT COMWARE: “letaria” (in Japanese).
https://www.nttcom.co.jp/dscb/letaria/index.html - [10] NTT DOCOMO press release: “Launch of Demonstration Experiment for DX Promotion of Business and Provision of Value-added Services Using Generative AI - Development of ‘LLM Value-added Platform’ to Improve Safety and Convenience of Generative AI -,” Aug. 2023 (in Japanese).
 https://www.docomo.ne.jp/binary/pdf/corporate/technology/rd/topics/2023/topics_230821_00.pdf (PDF format:0)
https://www.docomo.ne.jp/binary/pdf/corporate/technology/rd/topics/2023/topics_230821_00.pdf (PDF format:0) - [11] NTT DOCOMO: “MetaMe” (in Japanese).
https://lp.metame.ne.jp/ - [12] NTT DOCOMO: “docomo Open House’24 Co-creation starts here.,” Jan. 2024.
https://www.docomo.ne.jp/english/corporate/technology/rd/openhouse/openhouse2024/
- [1] NTT DOCOMO: “my daiz” (in Japanese).

