
Special Articles on AI Services—Document and Image Processing Technologies—
LLM Platform Technologies for On-site Business Use
Natural Language Processing Generative AI DX
Takuya Komada, Keisuke Oka, Shusuke Tatsumi and Yutaro Shiramizu
Service Innovation Department
Abstract
The appearance of ChatGPT marked the beginning of a new era in which document generative AI based on an LLM is coming to be used in a wide variety of fields. However, problems exist in the use of LLMs in business such as “no support for specialized business knowledge,” “ethical concerns with output,” and “risk of information leaks.” NTT DOCOMO has developed an LLM value-added platform having a variety of value-added functions for solving these problems and has begun to provide it to the NTT DOCOMO Group. This article describes the functions of this LLM value-added platform and their enabling technologies for driving the business use of LLMs.
01. Introduction
-
Since the appearance of ChatGPT [1], a new era has begun ...
Open

Since the appearance of ChatGPT [1], a new era has begun in which document generative AI based on a Large Language Model (LLM)*1 is coming to be used in a wide variety of fields. Document generative AI has a broad range of use covering abundant business applications such as the creation of email content, document summarization, bouncing of ideas*2, and creation of sample code for a program. The business use of document generative AI has attracted much attention, and various companies have recently come to introduce document generative AI and to use it independently in-house.
On the other hand, the following problems exist in using document generative AI for business operations within a company. The first problem is that it provides no support for specialized business knowledge. This is because non-public information such as a company’s internal documents cannot be included in training data when pre-training document generative AI preventing correct responses from being generated. The second problem is that there are ethical concerns about the content output by document generative AI. Since AI itself generates documents from scratch based on an LLM, it is difficult to control output content beforehand raising the possibility of generating documents with ethical issues. In actuality, there have already been many examples of social media backlash due to the generation of antagonistic documents by document generative AI and their release in society. The third problem is risk of information leakage. The input of non-public internal documents into a document-generative-AI system provided in a Software as a Service (SaaS)*3 format by another company is considered to be one type of risk of confidential information leakage.
NTT DOCOMO has developed an LLM value-added platform that has a variety of value-added functions to solve these problems and that enables generative AI to be used easily and securely even in business. This LLM value-added platform is based on a Graphical User Interface (GUI)*4 and provided as a Web application*5 equipped with a chat function. The user can easily use a variety of generative AI functions by simply accessing the platform from a browser. Value-added functions include an external-file reference function that can be used, for example, to input a file for use as a reference so that generative AI can respond with good accuracy to questions that require specialized knowledge. They also include an ethical filter function that can be used to automatically evaluate whether problematic expressions exist in generative AI output. The operation system, meanwhile, is always monitoring the input of personal information through a mechanical/visual hybrid approach so that the external leakage of information can be immediately detected.
This article describes the functions provided by the LLM value-added platform and their enabling technologies to support the business use of LLM.
- LLM: A model of natural language processing trained with extensive datasets of text.
- Bouncing of ideas: Organizing your thoughts by talking to another person about your hazy ideas. In particular, since the recent appearance of chat AI systems including LLMs, it has become possible to bounce one’s ideas off of AI instead of a human being.
- SaaS: Software that is used remotely via the Internet or other networks.
- GUI: An interface that consists of a combination of buttons and icons that are clearly visible and can be operated intuitively.
- Web application: Software that can be used on an Internet browser. As a key feature, it can be executed without having to install it beforehand on a PC.
-
2.1 Overview
Open
“LLM value-added platform” is the name of the platform system developed to support the business use of LLMs via a Web application. Its functions are being developed from the four viewpoints of enhancing convenience, ensuring security, securing reliability and safety, and linking with LLMs. At NTT DOCOMO, this platform is being applied to drive the use of LLMs in the NTT DOCOMO Group (Figure 1). Platform functions can be broadly divided into general-purpose basic functions for deploying and operating the platform and value-added functions that add NTT DOCOMO original elemental technologies. The following describes these basic functions and value-added functions in detail.
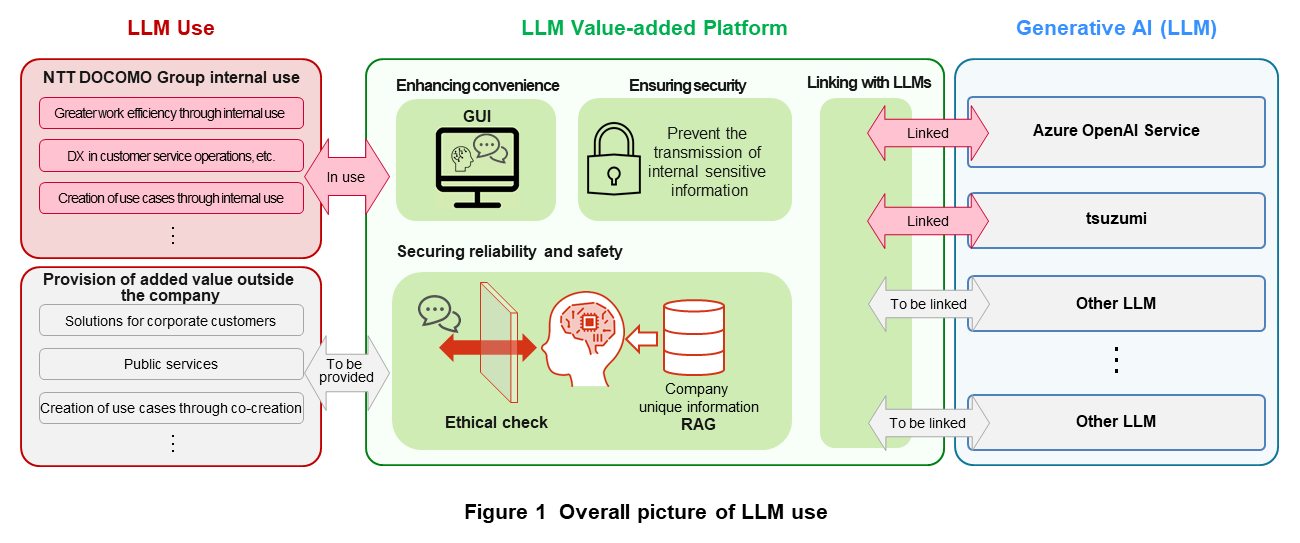
2.2 Basic Functions
1) Function Configuration and Function Overview
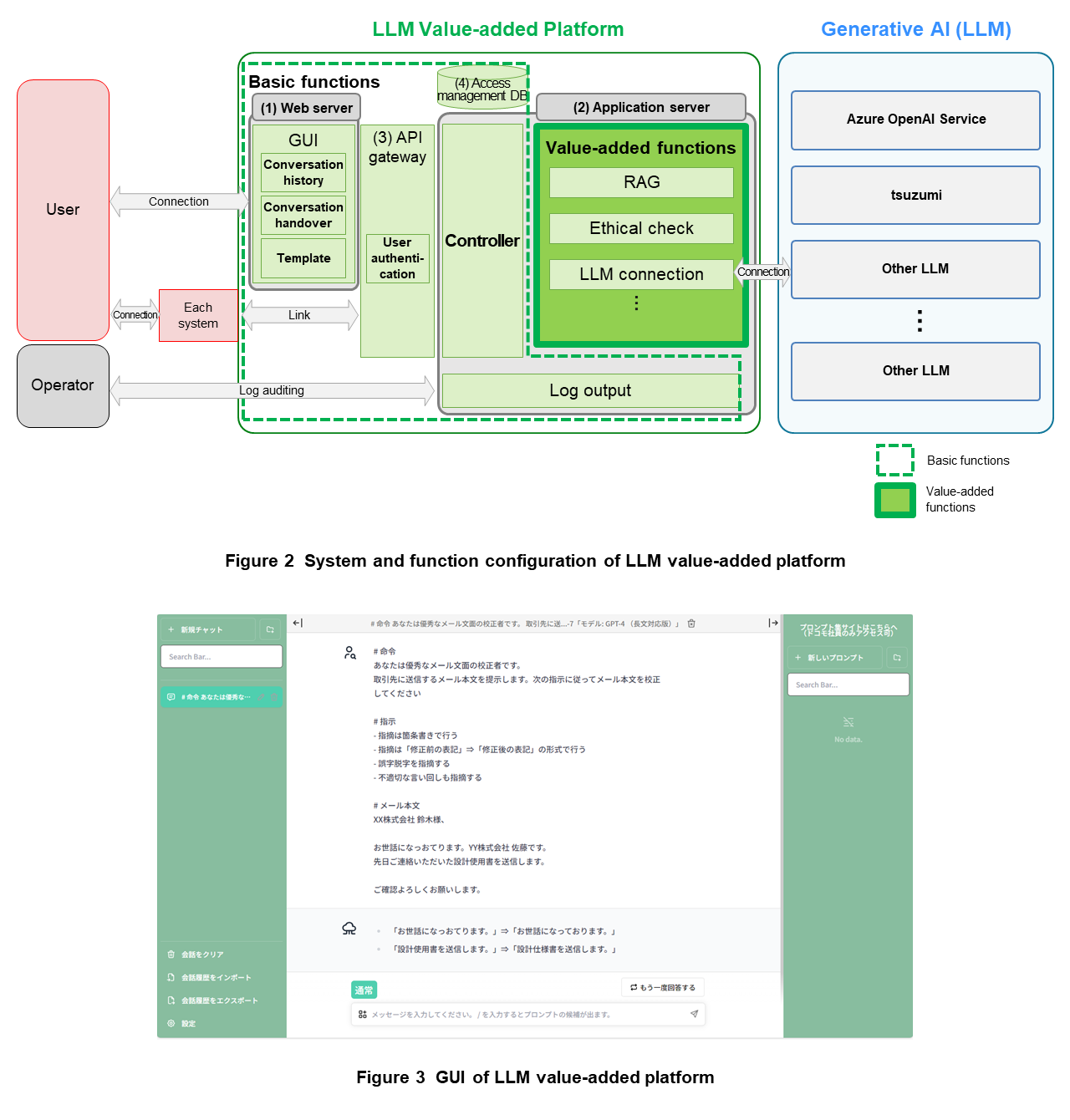
The LLM value-added platform is equipped with a GUI, Application Programming Interface (API)*6, user authentication, log monitoring, and security as basic functions. The GUI and log monitoring function, in particular, are essential to the intuitive and secure use of generative AI by the end user and constitute the core of the value-added platform.
The functions of the LLM value-added platform and system configuration are shown in Figure 2. The LLM value-added platform system consists of a (1) Web server, (2) application server, (3) API gateway*7, and (4) access management DataBase (DB). This system can use various generative AI models hosted inside and outside NTT DOCOMO.
- The Web server provides a GUI that enables the user to easily operate generative AI and the value-added functions described below without having to input complex commands.
- The application server is constructed with microservice architecture*8 consisting of value-added-function APIs and a controller for linking those APIs and generative AI.
- The API gateway consists of user-management functions enabling the issuing of an API key*9 and user authentication based on the issued API key. Each API is provided in a format that links value-added functions and generative AI via the API gateway.
- The access management DB takes the user authentication information sent by the API gateway and compares that information with user affiliation information to perform functional restrictions and access management for each affiliated organization.
The construction of this series of systems is performed by the Infrastructure as Code (IaC)*10 process as a scheme that enables secure and rapid support for system updates.
2) GUI
The LLM value-added platform provides a GUI that enables generative AI to be used via a chat-based interface. Additionally, with a view to enhancing user convenience, this GUI implements a (a) conversation history function, (b) conversation handover function, and (c) template function. The LLM value-added platform GUI is shown in Figure 3.
(a) Conversation history function
This function saves the input/output of generative AI used in the past as history. It enables the user to reference past chats and to continue an interrupted chat.
(b) Conversation handover function
This function issues a request to generative AI that includes the input/output history within a single chat in the user’s current input. It enables a multi-turn conversation*11 to be performed based on exchanges in a chat.
(c) Template function
This function saves an original prompt*12 created beforehand by the user. It can improve work efficiency by saving formulaic tasks like preparing emails as prompts.
3) Log Monitoring and Security
Since multiple users can use the LLM value-added platform without any restrictions on input, terms of service that prohibit the input of confidential information have been established and an operation monitoring system that reduces the risk of information leakage has been constructed. Specifically, the platform logs and saves input to and output from generative AI and regularly audits that log. Then, if confidential information such as a customer’s personal information should be discovered during an audit, the log data in question will be deleted from the platform and the user advised of that action.
Log auditing is performed in a hybrid manner that combines automatic checking of input by a personal-information detector and monitoring by visual means. This approach provides a system that can make the work of monitoring large amounts of log data more efficient and that can quickly detect the leakage of confidential information.
2.3 Value-added Functions
1) LLM Linking
The LLM value-added platform implements an LLM connection function that enables the user to select and use an LLM model optimal for the application. To give an example, in a use case that assumes the input of text with relatively many characters as when preparing the minutes of a meeting, the user would be able to choose a model with large context size.
In this way, we are working to expand the number of models that can be selected according to the application. These include, for example, NTT’s original LLM model tsuzumi [2] that is relatively lightweight and easy to use in the workplace.
Furthermore, as many generative AI systems require a huge amount of machine resources, limitations have been established on the number of requests or number of tokens*13 input/output per unit time. The LLM value-added platform relaxes these limitations by enabling multiple models to be selected.
2) External Knowledge Referencing
Generative AI provided as SaaS or Open Source Software (OSS)*14 is trained only with general knowledge. As a result, it cannot return answers based on specialized knowledge making it difficult to use for work inside a company. An approach that acquires specialized knowledge such as fine-tuning*15 has been considered to address this problem, but it is not easy for individual organizations that wish to do so to prepare large amounts of training data and to secure the necessary computational resources.
Therefore, the LLM value-added platform implements a file reference function and document retrieval function as functions that incorporate external knowledge in input so that responses based on specialized knowledge can be made.
The following provides details on technical initiatives related to the implementation of external knowledge referencing.
(a) File reference function
This function acts as an interface for inputting files such an internal company documents into generative AI in addition to usual user input in chat format. It automatically extracts documents related to user input from uploaded user files and inputs them into generative AI so that responses that include information from those files can be made. Additionally, since files used by the file reference function are not saved on the LLM value-added platform, they can be used securely while maintaining confidentiality.
(b) Document retrieval function
This function acts as an interface for referencing a group of files saved beforehand in data storage and inputting those files into generative AI in addition to usual user input in chat format.
In contrast to the file reference function, the document retrieval function enables multiple files stored in a folder to be referenced by using data storage. It also enables the range of disclosure to be specified for each folder based on each user’s affiliation information. This makes it possible to control the range of disclosure for multiple users and to support the searching for content that needs to be accessed by only specific users.
Additionally, while automatically extracting from files those documents related to user input as input to generative AI the same as the file reference function, the document retrieval function presents those extracted documents as grounds for output so that results can be judged correct or not even by users who don’t have those files at hand.
3) Ethical Check Function
This function checks for any ethical issues in LLM output. Creating emails and refining correspondence to outside parties can be considered typical use cases of using LLM. However, there is always the possibility that an LLM will generate unethical text, which means that showing LLM output as-is to other people involves a certain amount of risk. The ethical check function judges whether the content of LLM output is unethical. If it judges the content to be unethical, it warns the user accordingly and advises that such output not be used in a document to be shown to other people.
Details on technical initiatives related to the implementation of the ethical check function are described later.
- API: Interfaces specified for communications between different software.
- API gateway: An API management mechanism placed between the client and backend services in the system. A developer can use this gateway to intensively manage service security and functions.
- Microservice architecture: A technique for implementing the elements making up a system as small independent components.
- API key: Authentication information required for API use.
- IaC: The process of describing and managing the configuration of infrastructure such as servers, networks, and storage by means of code statements. It can be used to automate configuration and provisioning tasks.
- Multi-turn conversation: An interactive format consisting of multiple exchanges of conversation in line with the flow of past conversation.
- Prompt: A command given to a computer or program. In the context of LLMs, it refers to statements in a natural language format that are input to control LLM output.
- Token: A character or character string treated as the smallest unit of text. In the field of natural language processing, a byte unit smaller than a character is often treated as a token.
- OSS: Software whose source code is released free of charge for anyone to reuse or modify. However, the original author’s copyright itself is not discarded—when creating a derivative work or redistributing, the original copyright notice must be preserved.
- Fine-tuning: The process of taking a model pre-trained using a certain dataset and retraining part or all of that model using another dataset to finely tune the parameters of the machine learning model for a new task.
-
3.1 Overview
Open
An LLM pre-trained on a large-scale corpus*16 can output text in free form and perform tasks like bouncing around ideas with the user and doing a Q&A or chatting on general matters even without training or tuning. However, when using such an untrained and untuned LLM for work, two problems arise: its ability to respond to questions involving specialized knowledge is low and the possibility exists that its response will contain unethical content. The LLM value-added platform aims to provide technical solutions to these two problems in the form of external knowledge referencing and an ethical check function, respectively.
3.2 External Knowledge Referencing
1) Need for Internal Information Linking and Problem with LLM
In a company, having an LLM reference internal information such as internal regulations and customer information held by each organization and having it generate responses based on that information is a business need. Such information held by a company is non-public information that cannot be found on the Web and is consequently not included in LLM pre-training data. This creates a problem in that LLM cannot generate appropriate answers to questions that require the knowledge contained in that information.
2) RAG Provided by the Value-added Platform
Attention is being focused on a technology called Retrieval Augmented Generation (RAG) [3] that has an LLM reference internal information stored in company DBs to enable it to generate answers to questions related to that information. In RAG, the process begins by having a search engine search internal DBs based on the prompt input by the user. It then adds the obtained information to that prompt input by the user. Finally, the LLM generates a response based on that prompt and presents it to the user.
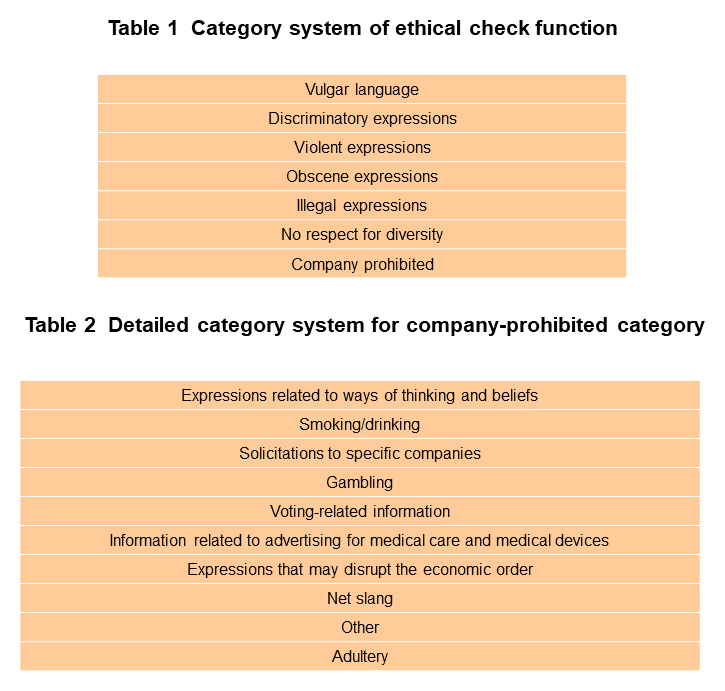
The LLM value-added platform provides two types of functions based on RAG according to use case, namely, the file reference function and document retrieval function described earlier. The technology used by either is RAG, but the upload timing of the file referenced by the LLM when generating a response and the holder of that file differ. In the file reference function, the search engine retrieves and references the content of the file uploaded by the user from that user’s own PC and the LLM then generates a response. As shown in Figure 4, the file is uploaded when the user inputs a question. In the document retrieval function, on the other hand, the search engine retrieves and references a file and its content from a large group of files uploaded beforehand onto the value-added platform by the administration department so that the LLM can generate a response (Figure 5). The document retrieval function also incorporates an access control function so that file referencing can be performed in compliance with user file access privileges.
3) Current Problems and Improvement Measures
Theoretically speaking, RAG is a groundbreaking technology that can generate responses to even questions related to a company’s internal information that includes no pre-trained data. In actual use, however, the function that has the LLM reference that internal information often becomes a bottleneck that prevents an appropriate response from being generated. NTT DOCOMO is working to improve operations in the referencing of internal information by the LLM aiming, in particular, to improve the accuracy of reading charts and graphs and retrieving files.
(a) Measures to improve the accuracy of reading graphical information
Since the LLM input/output format is text data, the information that can be referenced is basically only text data. A company’s internal information, however, includes a large amount of graphical information and not just text. Although information can be extracted from simple charts or graphs as a cohesive group of text data, information cannot be extracted from complex charts or graphs as meaningful and cohesive text data thereby preventing the LLM from referencing needed information.
In the face of this problem, NTT DOCOMO is currently testing AI + Optical Character Recognition (OCR)*17 technologies that use coordinate information and a technique that inputs the text data extracted from a chart or graph using those technologies into an LLM in markdown format*18. Through this testing, we have learned that this technique enables an LLM to reference the positional relationships of text based on the structural information of charts and graphs without missing any text as much as possible.
(b) Improving retrieval accuracy by converting referenced files to a Q&A format
It is known that retrieval accuracy drops if the user’s question and the LLM-referenced file differ in terms of writing style. With this in mind, NTT DOCOMO is currently testing a technique that converts stored files to a Q&A format under the assumption that retrieval accuracy can be improved if the writing style of files is closer to that of questions. Specifically, instead of storing a file directly in its original form, it is stored only after converting its content to a Q&A format. This conversion to a Q&A format is done automatically using an LLM. That is to say, the LLM is asked to automatically generate a Q&A by inputting both the text of the file and a prompt consisting of the instruction “Please generate a Q&A related to the file.” We have found through testing that the addition of this preprocessing does indeed improve retrieval accuracy.
3.3 Ethical Check Function
1) Necessity of Ethical Checking
A key characteristic of LLMs is the ability to freely generate text without the use of a template. This, however, leaves open the possibility of outputting text with inappropriate content. Inappropriate text output by an LLM can be broadly divided into two types: (1) the output of ethically inappropriate text and (2) the output of content that is factually incorrect (called a “hallucination”). In particular, from the viewpoint of type (1), there have been many examples in the past in which a business operator providing a document generation service using an LLM incurred a backlash on social media due to inappropriate content output by that LLM [4].
Unethical content is toxic, and its release either inside or outside the company runs the risk of creating a backlash on social media and harming company reputation and credibility. To reduce this risk, we are developing an ethical check function on the LLM value-added platform to check for any ethical issues in LLM output with respect to problems of type (1) among the above two types of inappropriate output.
2) Overview of Ethical Check Function
The ethical check function is a system centered about a document classifier*19 that determines whether input text has an ethical issue. This document classifier evaluates and checks text generated by the LLM from an ethical perspective. Specifically, it determines whether the text includes a specific ethical issue based on a predefined ethics category system.
This category system used by the ethical check function consists of eight originally defined categories. The classifier actually consists of seven classifiers based on binary classification*20 each of which determines whether certain text is applicable to the corresponding category. Each classifier stochastically outputs the possibility that the text is applicable to that category.
The ethical check function makes it possible to objectively evaluate whether text is applicable to a specific category. In this way, users can be alerted about the ethicality of generated content in the event that the LLM outputs an ethically inappropriate document.
3) Category System and Classifier
Services of ethical check functions currently provided around the world include OpenAI’s Moderation API and Perspective API, but these services are premised on U.S. English expressions and cultural background. They also differ from the NTT DOCOMO ethical check function in terms of flexibility and diversity. In particular, the category system of those services cannot be freely rewritten and such services are simply not oriented to business. The ethical check function of the LLM value-added platform can flexibly deal with this problem by independently constructing the category system and classifier.
The category system of the ethical check function is shown in Table 1. This system consists of seven categories—vulgar language, discriminatory expressions, violent expressions, obscene expressions, illegal expressions, no respect for diversity, and company prohibited—prepared by referencing prior research [5], category systems of similar services, and internal standards for checking documents intended for outside parties. In the first six categories above, basic inappropriate expressions are classified, and if text or a document having the risk of a backlash based on those categories should be output, that can be detected before such a backlash occurs.
Detailed categories of the company-prohibited category are listed in Table 2. As a countermeasure to risk when using the LLM value-added platform for work inside the company, expressions related to competitive solicitations, the Act against Unjustifiable Premiums and Misleading Representations, and the Pharmaceuticals and Medical Devices Act as well as expressions related to drinking and gambling, for example, that, while not illegal behavior, are difficult to deal with are classified and checked. These detailed categories go beyond the standard framework of unethical activities in society and make it possible to deal with even text that runs the risk of a backlash within a company.
The advantage of this ethical check function is that it can customize and tune this category system as needed, which means that it can provide detailed support for corporate business needs and Japanese language users.
Classification AI that performs ethical checking places importance on operation speed and accuracy. Instead of an LLM, it uses the Bidirectional Encoder Representations from Transformers (BERT)*21 model fine-tuned by a binary classification dataset for each category. In particular, for the BERT pre-trained model*22, we are using NTT BERT*23 created by NTT Laboratories and developing an ethical check function with a classifier that exploits the high Japanese language performance of NTT BERT.
- Corpus: A language resource consisting of a large volume of text and utterances, etc. collected and stored in a DB.
- OCR: Technology that recognizes printed or handwritten characters within an image and converts those characters to text data that can be processed by a computer.
- Markdown format: A type of notation for describing and embellishing text and tables. It is described in plain text, which makes it easy to handle and suitable for use in a variety of services.
- Classifier: A device that sorts inputs into predetermined groupings based on their feature values.
- Binary classification: A form of classification that determines whether or not an input document corresponds to a certain category.
- BERT: A natural language processing model developed by Google that can perform a variety of natural language processing tasks with high accuracy by fine-tuning.
- Pre-trained model: A model that has been trained unsupervised on a large corpus before supervised learning of the target task.
- NTT BERT: A BERT model that was pre-trained using data collected by NTT Human Informatics Laboratories.
-
In this article, we presented an overview of an LLM value-added ...
Open
In this article, we presented an overview of an LLM value-added platform that is being internally deployed toward the business use of LLMs and described its basic functions. Additionally, as value-added functions, we described RAG for making responses using a file reference function for questions requiring specialized knowledge and an ethical check function for ensuring ethical output.
By accessing the provided GUI via a Web browser, a user can interact with AI equipped with basic conversation functions such as a conversation history function, conversation handover function, and template function. The user can also make use of an LLM value-added platform that drives generative AI to make responses through document retrieval using RAG even for internal specialized knowledge. An ethical check function for checking whether output contains any ethical issues is also provided.
Going forward, we plan to perform actual usage trials within the company while adding and implementing internally desired functions to add even more value, improving the accuracy of RAG, and enabling the ethical check function to be customized as needed, all with the aim of making the LLM value-added platform even more convenient for users.
-
REFERENCES
Open
- [1] OpenAI: “ChatGPT.”
 https://chat.openai.com/
https://chat.openai.com/ - [2] NTT Human Informatics Laboratories: “NTT’s Large Language Models ‘tsuzumi’.”
https://www.rd.ntt/e/research/LLM_tsuzumi.html - [3] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. T. Yih, T. Rocktäschel, S. Riedel and D. Kiela: “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Proc. of NeurIPS 2020, Apr. 2021.
- [4] BBC NEWS: “Tay: Microsoft issues apology over racist chatbot fiasco.”
https://www.bbc.com/news/technology-35902104 - [5] K. Kobayashi, T. Yamazaki, K. Yoshikawa, M. Makita, A. Nakamachi, K. Sato, M. Asahara and T. Sato: “Proposal and Evaluation of Japanese Toxic Expressions Schema,” Proc. of the 29th Annual Conference of the Association for Natural Language Processing (NLP2023), pp. 933–938, Mar. 2023 (in Japanese).
- [1] OpenAI: “ChatGPT.”

