
Special Articles on Private Cross-aggregation Technology—Solving Social Problems through Cross-company Statistical Data Usage—
Guaranteeing Integrity in Private Cross-aggregation Technology
Security Privacy Protection TEE
Keita Hasegawa, Takuya Chida, Keiichi Ochiai and Tomohiro Nakagawa
X-Tech Development Department
Tetsuya Okuda
NTT Social Informatics Laboratories
Abstract
When using private cross-aggregation technology to utilize statistics that spans multiple companies, it is necessary to verify that the technology is executed correctly for each of the companies. We have proposed a method for guaranteeing the integrity of processing in a private cross-aggregation technology using a trusted execution environment, and we have shown that the method can be implemented on a public cloud environment. We have also confirmed that the implemented system satisfies a practical level of performance for large-scale data.
01. Introduction
-
There is a need to enable utilization of statistics across data ...
Open

There is a need to enable utilization of statistics across data held by multiple companies. However, the risk of data leaks or invasion of privacy when a company allows another company to use its data obstructs active data utilization between companies [1].
Private cross-aggregation technology enables statistics to be generated safely, without mutually disclosing data among the parties involved, using technology that guarantees that the sequence of processing is performed technically, without revealing data to human observation. It consists of (1) de-identification process, (2) secure aggregation process, and (3) disclosure limitation process [2]. For the aggregation process, a homomorphic encryption scheme called secure matching protocol [3] is used, which performs aggregation after the de-identification process, with data still in an encrypted state. In the disclosure limitation process, noise is added while still in the encrypted state, to achieve differential privacy [4]. These processes are performed cooperatively at the companies, and data processing must be performed correctly at each of them.
In this article, we describe a method for technically guaranteeing that data is processed correctly in the private cross-aggregation technology at each company. We have also implemented this method on a public cloud*1 and shown that it achieves a practical level of performance for large-scale input data.
- Public cloud: A cloud computing service that can be used by many non-specific users such as companies and individuals.
-
For the private cross-aggregation technology, data ...
Open
For the private cross-aggregation technology, data processing must be performed correctly at each of the companies participating in utilization of the statistics. The potential threats that could result if processing is not correctly executed are explained in another article in this special issue [2]. As an example, if the disclosure limitation process of the private cross-aggregation (which prevents disclosure of the output data by adding noise to aggregation results in the encrypted state) is not performed correctly, there will be a risk of privacy infringement from the output data.
Generally, we assume that companies participating in utilization of the statistics will behave properly, so can expect each of the data processing steps in the private cross-aggregation technology to be performed correctly. However, the possibility of data processing errors due to worker or operator error cannot be ruled out. As such, we consider it necessary to guarantee the correctness of data processing technologically.
To achieve this, a method must be established by which we can use technology to guarantee that data processing for the private cross-aggregation technology was performed correctly, satisfying the privacy and security requirements, even if a company participating in utilization of the statistics makes an error in operation. The privacy and security requirements include two points as follows, assuming the companies themselves behave correctly.
- Before data aggregation, the data must be processed so that no individuals can be identified, and during data aggregation, one's own company data must not be disclosed to another company.
- Private information in output data after data processing must be protected.
Each data processing step in the private cross-aggregation technology is implemented as a program, not requiring human intervention in the process of producing the output data from the input data. As such, processing will be executed correctly, as long as the program has not been tampered with. This property of a program not having been tampered with is called “integrity,” and the integrity of programs used to implement the private cross-aggregation technology must be guaranteed technologically. By guaranteeing the integrity of programs, we can guarantee that the processes of the private cross-aggregation technology are performed correctly at each company. This then satisfies the privacy and security requirements needed to create statistics across companies.
-
We describe a method for verifying integrity, as required to ...
Open
We describe a method for verifying integrity, as required to satisfy the privacy and security requirements of the private cross-aggregation technology described above. It is possible to verify that a program being run by a company has not been tampered with after a given point in the past by applying a hashing function*2 to the programs themselves and comparing the hash values obtained. A hash value is a value created using a hashing function, which is a one-way function that converts the input data to a fixed-length output value that is unique for the input data. A hashing function has the property that if the input data changes even by a small amount, a totally different hash value is produced. Thus, it is difficult to create a tampered program that will produce the same hash value as the program that is being verified for integrity. Using this property, by checking that the hash value for a program has not changed, we can verify its integrity. Note that the de-identification process that is part of the private cross-aggregation technology also uses hashing functions to irreversibly transform the input data, but this is a different application than the integrity verification described here.
In fact, it is difficult for a company to verify that programs run by other companies are operating correctly. As an example, it would be possible to receive the hash value of a program being run at another company and to compare it with another hash value received earlier, but it is difficult for the verifier (in the company) to verify whether the hash value received from the other company was correct (i.e.: from the program that was actually run at the other company). To resolve this situation, we decided to use two technologies called a Trusted Execution Environment (TEE)*3[5] and remote attestation*4. The method for verifying integrity using TEE in our private cross-aggregation technology is shown in Figure 1.
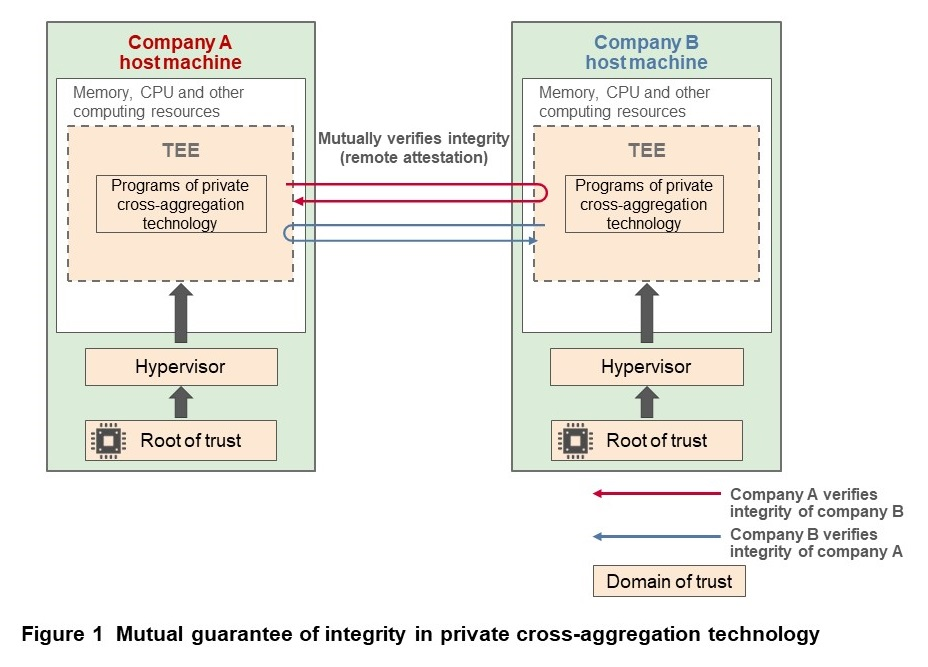
A TEE is a program execution environment*5 that is isolated from the host machine. In most cases, hardware such as the CPU or a security chip acts as the root of trust and computing resources such as physical memory and the CPU provide isolated computation areas. Such areas are called enclaves, and these computing resources are isolated even from the administrator of the host machine.
By also using a function called attestation, it is possible to verify that the hardware that is the root of trust of the TEE was properly manufactured and that the integrity of the program running in the computation area within the TEE is ensured. The attestation function verifies that in the TEE context, a particular program is running in an execution environment based on hardware that can be trusted.
In particular, attestation performed from outside of the host machine where the TEE is operating is called remote attestation, which uses information about the hardware operating the TEE and hash values of the program running within the TEE to verify the integrity of the program. With remote attestation, it is possible to verify the trustworthiness of a TEE, since it is operating based on hardware that is the root of trust, and also the integrity of the program running within the TEE, without depending on the trustworthiness of the environment where the TEE is operating (i.e., host machine managed by other company).
Private cross-aggregation technology performs cooperative data processing by the companies utilizing the statistics. As such, to satisfy the privacy and security requirements from the perspective of both companies, integrity must be verified in both directions rather than only one direction. To achieve this with the private cross-aggregation technology, each company must maintain a system with a TEE, and the programs of private cross-aggregation technology must be running in the TEE.
The possibility of invasion of privacy, as mentioned earlier, arises because intermediate data shared by one company with another company could be processed by a program that cannot be trusted by the company. With the private cross-aggregation technology, when encrypted intermediate data is shared between companies, the companies each use remote attestation to verify the integrity of programs run at the other company. Processing only proceeds if integrity verification is successful and the system is designed not to allow processing to proceed if it fails. This prevents invasion of privacy from the output data, even if a program has been tampered with.
- Hashing function: A function that generates a specific and unique bit string of a fixed length from arbitrary input data.
- TEE: An execution environment in which computing resources are isolated from the host machine using the CPU or a security chip as a root of trust.
- Remote attestation: A method for verifying the trustworthiness of the TEE and the integrity of a program running in the TEE from outside of the host machine or device where the TEE is operating.
- Execution environment: A system environment that is able to process execution of programs and software.
-
To confirm that integrity verification with the private ...
Open
To confirm that integrity verification with the private cross-aggregation technology can be implemented in an actual system, we implemented it using the Amazon Web Services (AWS)*6 public cloud environment.
4.1 System Configuration
The system implementing the private cross-aggregation technology described in this article consists of a pair of servers which exchange intermediate data between TEEs, to process the data cooperatively. The details of data processing are given in another of these special articles [2]. The private cross-aggregation technology processes the data in encrypted form using secure computation*7 based on homomorphic encryption, so the computational cost is higher than processing plain-text data. For this reason, we designed the system so that the servers and TEEs performing the aggregation are scalable*8 based on the amount of data being processed, in order to achieve a practical level of performance when processing large-scale data.
4.2 AWS Service Used to Implement the Private Cross-aggregation Technology
Below we describe the AWS service used to implement the private cross-aggregation system, focusing on the key services to verify integrity. We used Elastic Compute Cloud (EC2) instances (virtual servers provided by AWS) to process data for the private cross-aggregation technology. EC2 instances support AWS Nitro Enclaves [6], which are the AWS TEE. A Nitro Enclave runs isolated computing resources (CPU and memory) of the EC2 instance, which is the host machine. Other users or applications on the same instance cannot access these isolated areas. Isolation of an Enclave from the host machine is managed by the hypervisor*9 and its trustworthiness is guaranteed using a chain of trust based on hardware as the root of trust.
A Docker*10 container-based machine image called an Enclave Image File (EIF) runs in the enclave. When building*11 an EIF, a Platform Configuration Register (PCR)*12 is generated, which includes the hash value for the program that will run in the EIF. This PCR value is linked to the AWS Key Management Service (KMS) [7], described below, and used to implement integrity verification in the AWS cloud environment.
The AWS KMS makes it easy to create and manage keys used for encrypting data and for digital signatures. The private cross-aggregation technology uses data keys managed by KMS when encrypting and decrypting intermediate data.
4.3 Method for Verifying Integrity in the Private Cross-aggregation Technology on AWS
The methods for mutually verifying integrity and processing data collaboratively in the private cross-aggregation technology system implemented using AWS services are described below. Integrity is verified when encrypting and decrypting data, making it possible to guarantee that programs were not tampered with and processing was performed correctly. The method for verifying integrity when encrypting and decrypting the data is shown in Figure 2. Programs implemented for the private cross-aggregation technology run in a Nitro Enclave as an EIF. During the processing for the private cross-aggregation technology, encrypted intermediate data is sent in both directions, but Fig. 2 only shows operations when company A sends encrypted intermediate data to company B.
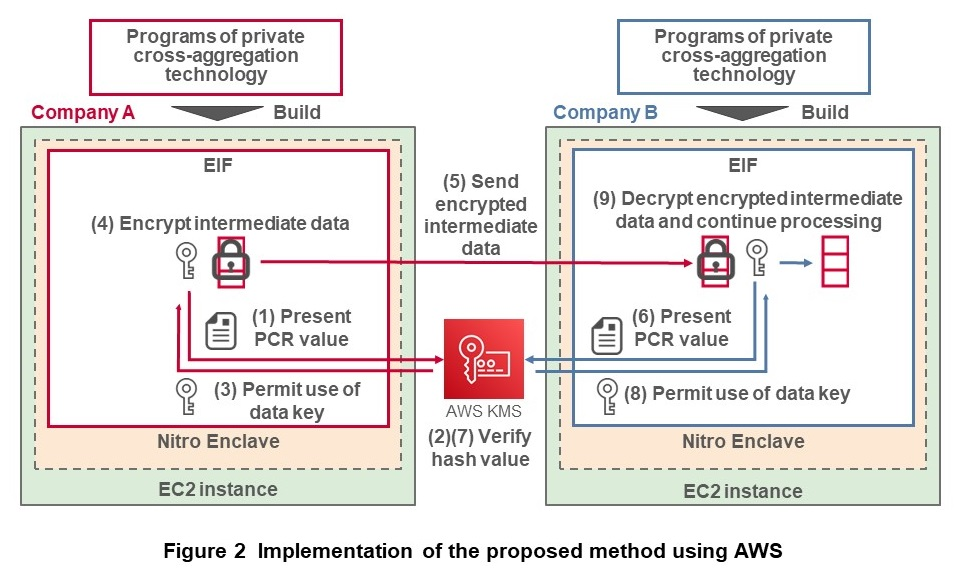
When company A's enclave sends private cross-aggregation technology intermediate data, it encrypts the data using a KMS data key. For it to use the data key, it must successfully verify integrity of the EIF PCR value (a hash value) with the KMS. After successfully verifying integrity (Fig. 2(1)(2)), it encrypts the intermediate data using the data key (Fig. 2(3)(4)), and sends the encrypted intermediate data to the enclave managed by company B (Fig. 2(5)). The data key is required to decrypt the encrypted intermediate data, so the receiving side (company B) must also verify the EIF integrity in the same way as was done by the sending side (company A) (Fig. 2(6)(7)). If company B is able to verify integrity of its own EIF, it can proceed with decrypting the encrypted intermediate data and processing the data for the private cross-aggregation technology (Fig. 2(8)(9)). Thus, exchanging intermediate data is controlled by only encrypting and decrypting data with EIF whose integrity has been verified. This makes it possible to guarantee that data processing for the private cross-aggregation technology is executed correctly.
- AWS: A cloud computing service provided by Amazon Web Services, Inc.
- Secure computation: A technology that enables processing of data while still encrypted rather than as clear text (i.e., not encrypted). Methods for implementing it include secure distributed methods that fragment data before computation, and homomorphic encryption, which enables computations on the data in encrypted form.
- Scaling: Optimization of processing performance by changing, increasing or decreasing the servers (especially for virtual servers) when there is insufficient or excess capacity for load conditions on the system.
- Hypervisor: Technology or software for running virtual servers on a single physical server. AWS Nitro Enclaves uses a hypervisor to isolate computing resources from an EC2 instance and run them.
- Docker: Container-based virtualization software. A registered trademark of Docker Inc.
- Building: The process or operations of creating an executable file or a distribution package for a particular device based on source code.
- PCR value: A hash value covering the sequence of processes from hardware startup to launch of a particular program, used to verify the integrity of the program running within a TEE.
-
This chapter gives an analysis of the security of the system ...
Open
This chapter gives an analysis of the security of the system described above and results of evaluating data processing performance.
5.1 Analyzing Security
When creating statistics using the private cross-aggregation technology, it is conceivable that data or programs in the system implementing the technology could be altered or falsified through erroneous operation by any of the participating companies. For example, if the disclosure limitation process is not executed correctly due to falsifying a program, the system could output data for which appropriate noise based on differential privacy was not added. However, if a program operating within a Nitro Enclave is falsified, the EIF PCR value will change. This would prevent use of the KMS data key, and the encrypted intermediate data used in the private cross-aggregation technology could not be decrypted thus no output data could be produced.
Encrypted intermediate data could also be falsified when being transmitted between enclaves. If this were the case, the enclave receiving the intermediate data would not be able to decrypt it correctly, so the private cross-aggregation technology processing would not be able to proceed. Thus, no output data could be produced in this case either. We conducted experiments falsifying programs and data in these ways. We confirmed that the EIF PCR value changed due to the falsification, the KMS data key could not be used, and the private cross-aggregation processing terminated when attempting encryption or decryption.
5.2 Evaluating Performance
Noise based on differential privacy is added to the aggregated results of the private cross-aggregation technology in the disclosure limitation process. Thus, to obtain useful statistical information even when considering the effects of the noise, it is desirable to be able to aggregate large amounts of input data efficiently. Thus, we created various dummy data sets of from ten million to 100 million records as realistic large-scale data sets, and used them to evaluate performance of the implemented system. Our experiments confirmed that aggregation of large-scale input data is possible within a practical processing time, of about ten minutes to several hours. We also confirmed that the processing time tends to be inversely proportional to the number of instances used to perform the aggregation. Thus, we can expect it will be possible to create statistics within a practical timeframe for larger input data by using parallel distributed processing according to the data size.
-
This article has described a technical method for guaranteeing ...
Open
This article has described a technical method for guaranteeing integrity, that the processing of the private cross-aggregation technology has not been tampered with. The method ensures that each data processing step in the technology is executed correctly, thus satisfying the privacy and security requirements for utilization of statistics across multiple companies. We also implemented the proposed method in a cloud environment, analyzed its security and evaluated its performance, showing that it is possible to implement a practical system for realistic large-scale data sets. Going forward, we plan to demonstrate the usefulness of the private cross-aggregation technology using actual data toward deployment of the technology in society.
-
REFERENCES
Open
- [1] Ministry of Internal Affairs and Communications: “Present Status and Challenges for Digital Transformation in Corporate Activities,” 2021 Information and Communications White Paper, 2021.
 https://www.soumu.go.jp/main_sosiki/joho_tsusin/eng/whitepaper/2021/pdf/chapter-1.pdf#page=7
https://www.soumu.go.jp/main_sosiki/joho_tsusin/eng/whitepaper/2021/pdf/chapter-1.pdf#page=7 - [2] K. Nozawa et al.: “Technique for Achieving Privacy and Security in Cross-company Statistical Data Usage,” NTT DOCOMO Technical Journal, Vol. 25, No. 1, Jul. 2023.
https://www.docomo.ne.jp/english/corporate/technology/rd/technical_journal/bn/vol25_1/002.html - [3] K. Chida, M. Terada, T. Yamaguchi, D. Ikarashi, K. Hamada and K. Takahashi: “A Secure Matching Protocol with Statistical Disclosure Control,” IPSJ SIG Technical Report, Vol. 2011- CSEC-52, No. 12, pp. 1-6, Mar. 2011 (in Japanese).
- [4] M. Kii: “A Secure Sampling Method with a Smaller Table for Differential Privacy,” Proc. of CSS2022, pp. 137-144, Oct. 2022 (in Japanese).
- [5] S. Kuniyasu: “Implementation of Trusted Execution Environment and Its Supporting Technologies,” IEICE Fundamentals Review, Vol. 14, No. 2, pp. 107-117, 2020 (in Japanese).
- [6] AWS: “AWS Nitro Enclaves,” Dec. 2022.
 https://aws.amazon.com/ec2/nitro/nitro-enclaves/?nc1=h_ls
https://aws.amazon.com/ec2/nitro/nitro-enclaves/?nc1=h_ls - [7] AWS: “AWS Key Management Service,” Dec. 2022.
https://aws.amazon.com/kms/?nc1=h_ls
- [1] Ministry of Internal Affairs and Communications: “Present Status and Challenges for Digital Transformation in Corporate Activities,” 2021 Information and Communications White Paper, 2021.

