
Special Articles on Private Cross-aggregation Technology—Solving Social Problems through Cross-company Statistical Data Usage—
Technique for Achieving Privacy and Security in Cross-company Statistical Data Usage
Privacy Protection Security Differential Privacy
Kazuma Nozawa, Keita Hasegawa, Keiichi Ochiai, Tomohiro Nakagawa, Kazuya Sasaki and Masayuki Terada
X-Tech Development Department
Masanobu Kii, Atsunori Ichikawa and Toshiyuki Miyazawa
NTT Social Informatics Laboratories
Abstract
The use of statistical data across companies is a method of obtaining new perspectives that could not be obtained by a single company. Using the knowledge gained in this way can help find solutions to social problems. However, preventing the disclosure of one’s own company data to another company in the process of creating output data and guaranteeing privacy in the output data are issues of concern. NTT DOCOMO has developed private cross-aggregation technology to resolve these issues. This article summarizes the privacy and security requirements that must be satisfied in cross-company statistical data usage and describes a technique for satisfying those requirements through the combined application of secure matching protocol, noise-addition technology to achieve differential privacy, and a trusted execution environment used in private cross-aggregation technology.
01. Introduction
-
Using data held by multiple companies in a cross-company manner is ...
Open

Using data held by multiple companies in a cross-company manner is expected to achieve data analysis from perspectives not obtainable by a single company and create value that can help solve social problems. One method that can be considered for using data across companies is to create and use statistics from the data of multiple companies while protecting the privacy of individuals (hereinafter referred to as “cross-company statistical data usage”). There are two major privacy and security requirements in cross-company statistical data usage. First, before data linking, the data must be processed so that no individuals can be re-identified, and during data linking, one’s own company data must not be disclosed to the other company. Second, private information must be protected in output data after data linking [1].
These requirements must be satisfied to perform cross-company statistical data usage while protecting private information. To technically satisfy these requirements and safely create statistics, NTT DOCOMO developed private cross-aggregation technology that guarantees that no data will be mutually disclosed, or in other words, that only a machine will perform the associated series of operations away from the human eye by applying homomorphic encryption technology, noise addition*1 based on differential privacy*2, and a Trusted Execution Environment (TEE)*3. Based on the issues and requirements in cross-company statistical data usage described in the opening article of this issue [1], this article describes the privacy and security requirements that must be satisfied by private cross-aggregation technology and its data processing methods.
In addition, the correctness of the processing performed by private cross-aggregation technology is guaranteed through the use of technology called a TEE. This technology is described in another special article in this issue [2].
- Noise addition: The process of adding random numbers to aggregate tables to protect private information in output data.
- Differential privacy: An index that quantitatively measures the strength of privacy protection. It was created with the aim of guaranteeing safety even against attackers having specific background knowledge and attacking ability. A protection technique using differential privacy has been adopted in the U.S. national census.
- TEE: A safe execution environment logically isolated from the host OS. Resources like memory and CPUs cannot be accessed from the host OS.
-
We here summarize the privacy and security requirements that must be ...
Open
We here summarize the privacy and security requirements that must be satisfied by private cross-aggregation technology based on the issues and requirements associated with cross-company statistical data usage as described in the opening article of this issue [1].
2.1 Cross-company Statistical Data Usage
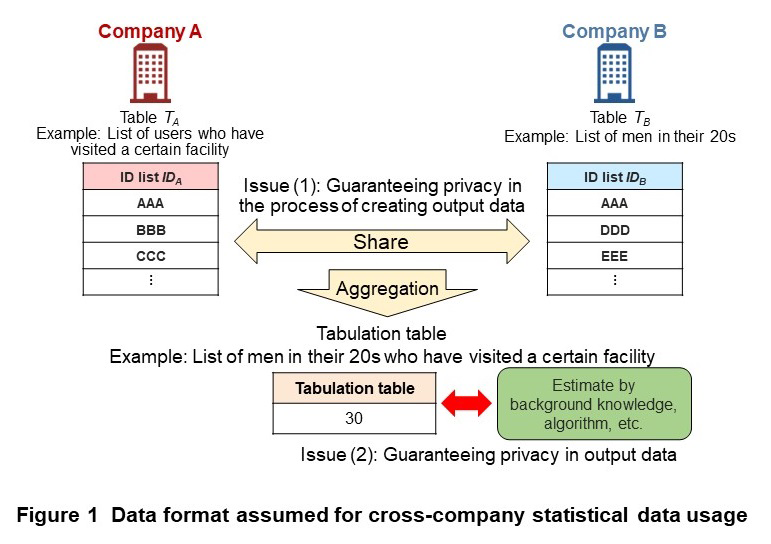
The data format assumed for cross-company statistical data usage is shown in Figure 1. Here, company A and company B hold table TA (e.g., list of users who have visited a certain facility obtained from location information held by company A) and table TB (e.g., list of men in their 20s held by company B), respectively, where table TA and table TB store ID lists IDA and IDB (e.g., telephone numbers) in a data format common to the two companies. Note that additional information in these ID lists (i.e., information on users who have visited a certain facility, men in their 20s) is sufficiently rounded to prevent an ID list from becoming too small. In this example, cross-company statistical data usage seeks to determine the number of men in their 20s who have visited a certain facility on the basis of tables TA and TB of company A and company B by creating a tabulation table that shows the number of matches between ID lists IDA and IDB. This table can then be applied to the measures or policies of company A or company B. As the number of common elements between the data sets in tables TA and TB, either company could not create this tabulation table on its own. In terms of statistical data, various types of values such as the mean and median of cross-company data could be considered, but this article assumes an aggregated value (number of common set elements).
2.2 Issues in Cross-company Statistical Data Usage
Here, we take up the issues of guaranteeing privacy in the process of creating output data and guaranteeing privacy in output data that arise in cross-company statistical data usage (Fig. 1).
1) Guaranteeing Privacy in the Process of Creating Output Data
The issue of guaranteeing privacy in the process of creating output data concerns the disclosure of private information*4 to the data-linking destination or a third party when creating cross-company statistics. To obtain statistics using cross-company data usually requires at the least that either company A or company B discloses table TA or table TB to the other company. For example, company B can use the information disclosed by company A (list of users who have visited a certain facility) to determine that certain users have visited a certain facility.
Consequently, the privacy and security requirement that must be satisfied here (referred to below as “privacy and security requirement (1)”) is that tables TA and TB must be converted to data in which no individuals can be re-identified before data linking and that no personal information related to tables TA and TB may be disclosed to the other party during data linking other than the data in the tabulation table.
2) Guaranteeing Privacy in Output Data
The issue of guaranteeing privacy in output data concerns an invasion of privacy from the tabulation table consisting of output data. Even if data processing that satisfies privacy and security requirement (1) has been achieved, it is still possible for private information to be disclosed from the output tabulation table [3][4]. For example, company B knows the number of people in its own input list, so in the event that that value matches the value in the tabulation table, it would know that all the users in its input list visited a certain facility. The possibility also exists that user information comes to be disclosed from the tabulation table not only at company B but also at company A or a third party.
In other words, the second privacy and security requirement that must be satisfied here (hereinafter referred to below as “privacy and security requirement (2)”) is that private information related to tables TA and TB must be appropriately protected in the tabulation table.
The privacy and security requirements that must be satisfied by private cross-aggregation technology can be summarized as follows.
- Privacy and security requirement (1): Before data linking, tables TA and TB must be converted into data in which no individuals can be re-identified, and during data linking, no personal information in tables TA and TB may be disclosed to another company other than the output tabulation table.
- Privacy and security requirement (2): Private information in tables TA and TB must be protected in the tabulation table.
- Disclosure of private information: The ability to estimate private information related to individuals included in tables.
-
The following explains private cross-aggregation technology for satisfying ...
Open
The following explains private cross-aggregation technology for satisfying the privacy and security requirements described above and resolving the issues in creating cross-company statistics.
3.1 Overall Configuration of Private Cross-aggregation Technology
The issue of guaranteeing privacy in the process of creating output data arises because of the possibility of accessing the information stored in tables TA and TB. As a countermeasure to this problem, it is necessary to guarantee confidentiality, which is the property of being able to access only approved material. Confidentiality in private cross-aggregation technology means that another company or third-party cannot ascertain one’s own company data to be meaningful information (data in an unencrypted, plain-text state) from data input to the point of obtaining output data. Furthermore, since the restoration of information stored in tables TA and TB from intermediate data during processing can also be considered, a technique is needed that prevents either company A or company B from determining the contents of the process. In addition, the issue of guaranteeing privacy in output data arises because data that can potentially re-identify individuals may remain and be disclosed in the tabulation table. A countermeasure to this problem would be to process the output data before release by some technique such as deleting data or adding noise to eliminate any such effects.
An outline of the processes in private cross-aggregation technology is shown in Figure 2. Private cross-aggregation technology consists of (1) a de-identification process (2) a secure aggregation process and (3) a disclosure limitation process, which together can create statistics without mutually disclosing data among the parties involved. This technology also uses secure matching protocol*5 [5]–[8], differential privacy [9], and a TEE as constituent technologies for satisfying the privacy and security requirements described above.
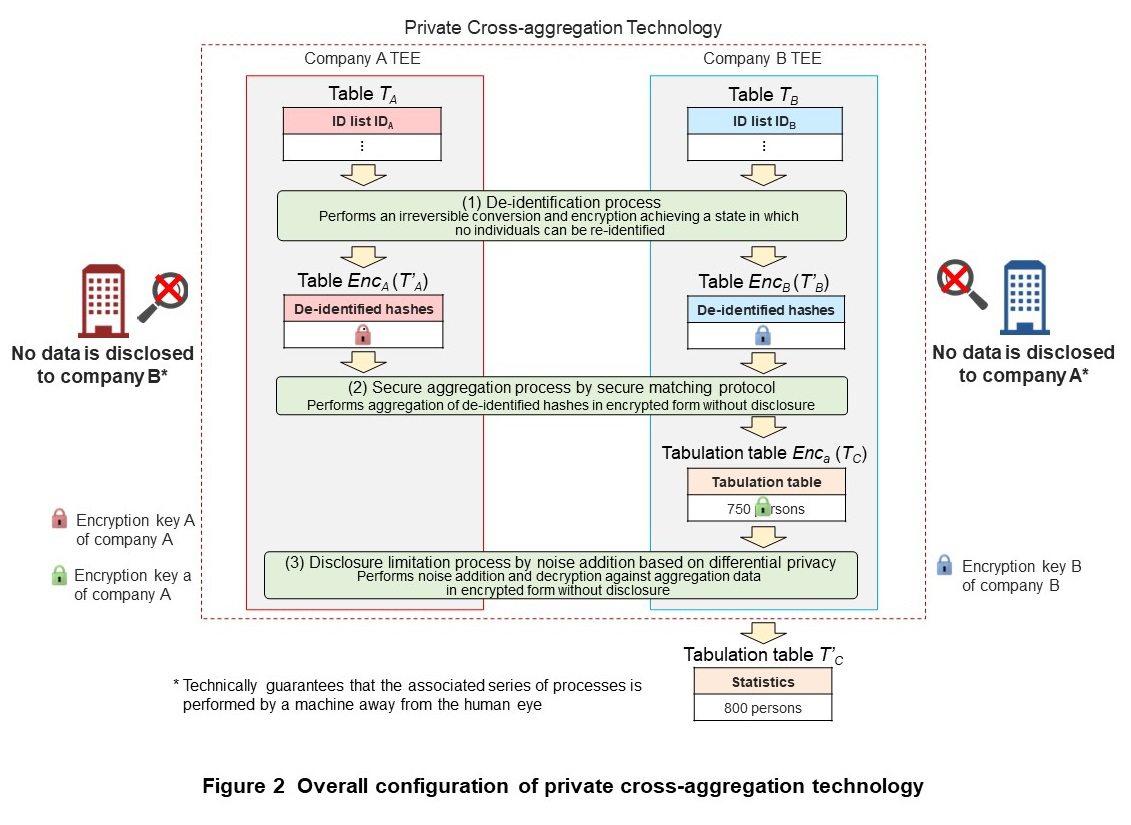
(1) De-identification process
This process adds salt*6 (a random character sting) common to company A and company B to the respective ID groups of tables TA and TB, performs hashing*7 of those IDs, and converts each to a hash value (hereinafter referred to as a “de-identified hash”). Here, destroying the salt after hashing irreversibly converts the ID.
(2) Secure aggregation process
This process uses a secure matching protocol based on homomorphic encryption technology to create a tabulation table in encrypted form. Using the secure matching protocol in this way makes it possible to obtain the number of matching de-identified hashes as a tabulation table in encrypted form without mutually disclosing the de-identified hashes held by company A and company B. The de-identification process and secure aggregation process based on secure matching protocol prevents the disclosing of one’s own company data to another company during data linking as brought up in the issue of guaranteeing privacy in the process of creating output data. Privacy and security requirement (1) is therefore satisfied as long as the de-identification process and secure aggregation process based on secure matching protocol are correctly performed.
(3) Disclosure limitation process
The disclosure limitation process adds noise based on differential privacy to the tabulation table in encrypted form output by the secure matching protocol. This process prevents the disclosing of private information from the output of data linking as brought up in the issue of guaranteeing privacy in output data. Privacy and security requirement (2) is therefore satisfied as long as the disclosure limitation process is correctly performed.
Additionally, private cross-aggregation technology must guarantee that the series of data processing throughout the de-identification process, secure aggregation process, and disclosure limitation process must be done correctly. For this reason, private cross-aggregation technology takes on a configuration that guarantees that data processing is done correctly through the use of a TEE. This approach is described in another special article in this issue [2].
3.2 De-identification Process
The de-identification process irreversibly converts an ID so that re-identification*8 cannot be performed and puts it into a state in which the individual cannot be re-identified. The de-identification process is outlined in Figure 3. The following summarizes the processing implemented to satisfy privacy and security requirements.
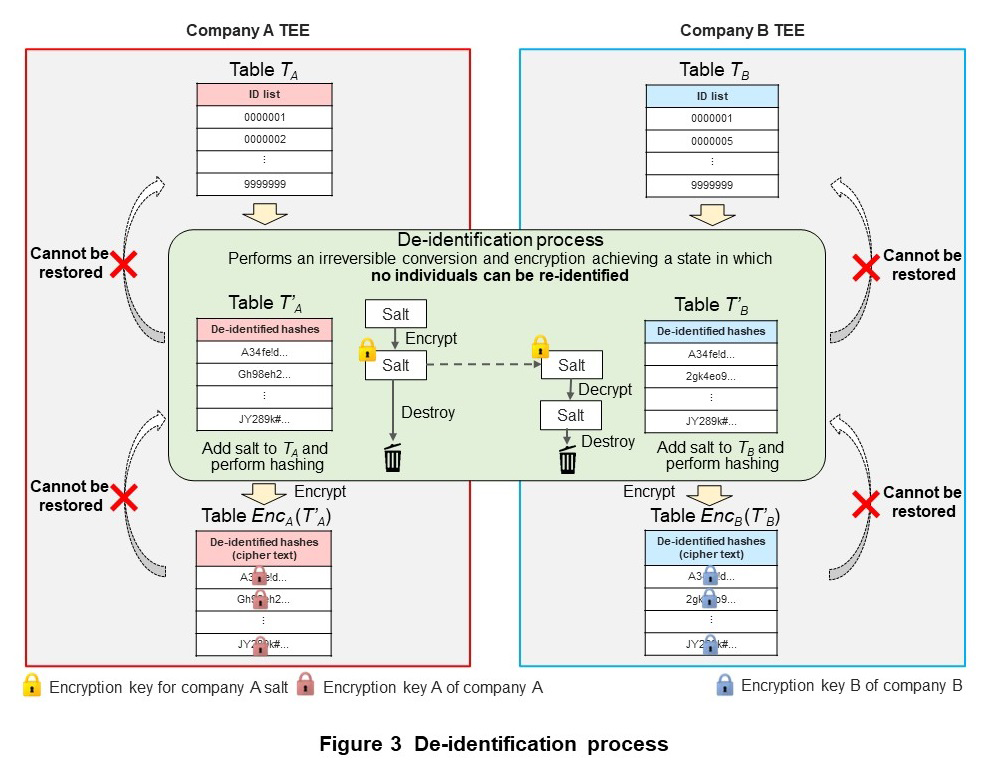
- Company A generates the salt needed for hashing tables TA and TB within the TEE of company A and encrypts that salt. The process of encrypting/decrypting the salt uses a technique that can only be executed within the pre-determined TEEs of company A and company B.
- Company A sends the encrypted salt to company B, which decrypts the received salt in the TEE of company B.
- Company A and company B adds the salt to tables TA and TB, respectively, performs hashing using the hash function*9, and obtains tables T’A and T’B consisting of de-identified hashes.
- Company A and company B both destroy the salt.
- Company A encrypts table T’A using its own encryption key A to obtain EncA(T’A). Likewise, company B encrypts table T’B using its own encryption key B to obtain EncB(T’B). Here, the notation EncX(T) means the encryption of table T using encryption key X.
With regard to the destroying of salt in step (4), if the salt and hash function used for hashing by company A or company B is reusable, the possibility holds that a correspondence between a de-identified hash and ID will be re-identified. For example, if the ID format (11 numerals in the case of telephone numbers) is known, a brute-force attack*10 that calculates all ID hash values using the reused salt can be successfully executed. To therefore make the conversion of IDs to de-identified hashes an irreversible process, it is necessary to destroy the salt so that it cannot be reused.
In private cross-aggregation technology, implementing all processes including the de-identification process in a TEE to guarantee process integrity*11 prevents any altering of the process in step (4). For example, preventing the process from being altered to one that does not destroy the salt can prevent the salt from being reused.
Step (5), as well, is performed within a TEE thereby preventing that process from being altered. For example, this can prevent unanticipated processes such as the restoration of table T’A from table EncA(T’A) by company A using encryption key A (the same for company B).
3.3 Secure Aggregation Process by Secure Matching Protocol
The secure aggregation process tabulates the number of de-identified hashes that match up between table EncA(T’A) and table EncB(T’B) in encrypted form. Private cross-aggregation technology uses a technique called secure matching protocol in the secure aggregation process. Secure matching protocol is based on homomorphic encryption technology that can process data in encrypted form. It can perform the secure aggregation process without mutually disclosing the de-identified hashes held by multiple parties.
An outline of the secure aggregation process based on secure matching protocol is shown in Figure 4. The following summarizes the processing implemented to satisfy privacy and security requirements. Details can be found in Ref. [6].
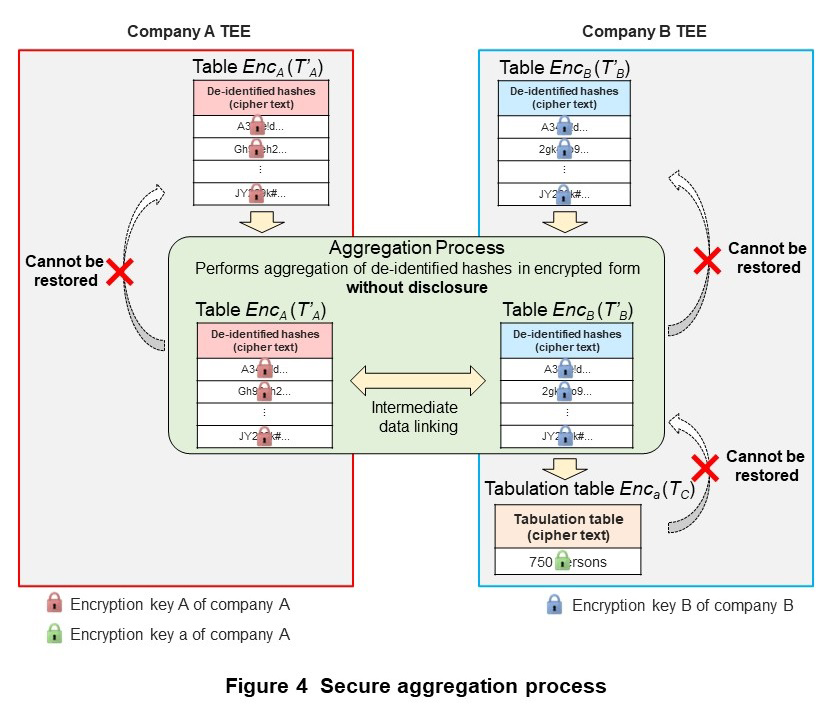
Company A sends table EncA(T’A) obtained by the de-identification process to company B. Company B likewise sends table EncB(T’B) to company A. Here, EncA(T’A) sent from company A to company B includes dummy de-identified hashes to prevent the number of records in table TA from being disclosed to company B.
Company A creates EncAEncB(T’B) by encrypting EncB(T’B) with its own encryption key A and sends EncAEncB(T’B) to company B. In the same way, company B creates EncBEncA(T’A) by encrypting EncA(T’A) with its own encryption key B and sends EncBEncA(T’A) to company A.
Company A creates EncBEncA(T’A|D) that links encrypted 1, which is generated by using company A’s encryption key a, to the de-identified hashes of EncBEncA(T’A), and that links encrypted 0, which is generated by using encryption key a, to the dummy de-identified hashes. Company A then sends EncBEncA(T’A|D) to company B.
Company B now tabulates the cipher text linked to the de-identified hashes of EncAEncB(T’B) from table EncBEncA(T’A|D) to obtain EncA(TC) encrypted using company A’s encryption key a.
Here, T’A is encrypted in the order of company A’s encryption key A and company B’s encryption key B and T’B is encrypted in the order of company B’s encryption key B and company A’s encryption key A. In secure matching protocol, however, matches can be determined even for different orders of encryption. Additionally, since encryption key a is the key used in homomorphic encryption, EncA(TC) can be obtained without disclosing the data itself.
3.4 Disclosure Limitation Process by Noise Addition Based on Differential Privacy
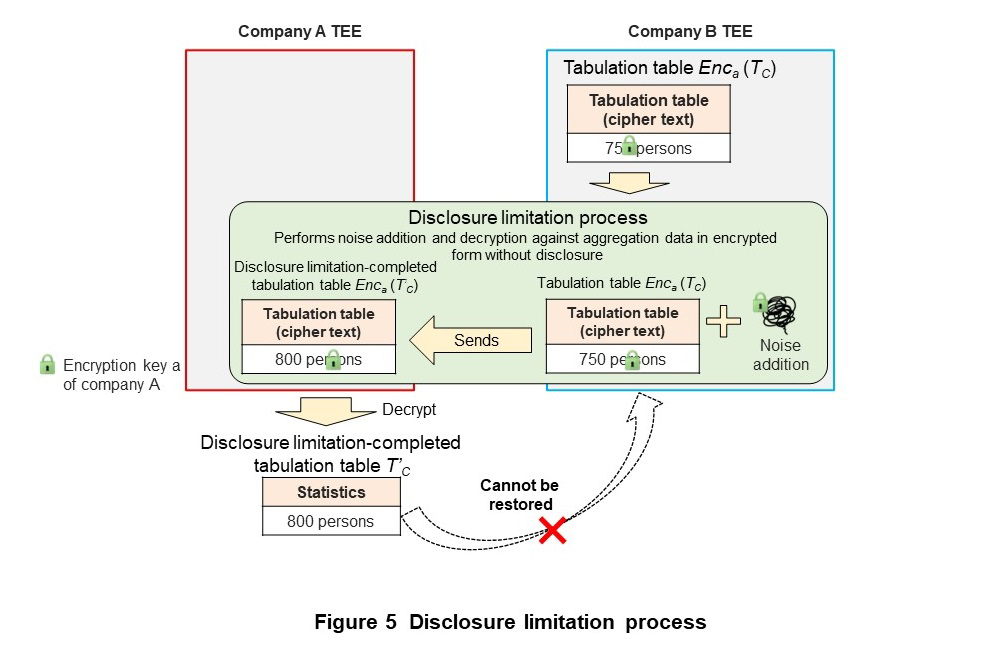
The disclosure limitation process guarantees that private information will not be disclosed in output results. Guaranteeing safety in the output results of private cross-aggregation technology is accomplished by adding noise based on differential privacy to tabulation table EncA(TC) obtained by aggregation using secure matching protocol. Differential privacy is an index that quantitatively measures the strength of privacy protection, created with the aim of guaranteeing safety even against attackers having specific background knowledge and attacking ability [10]. To therefore guarantee privacy in output data, it is necessary to add noise to tabulation table EncA(TC) in encrypted form before it is released. Several techniques for achieving differential privacy in this state have been researched [11]–[13], and from among these, it was decided to use Kii’s protocol in our private cross-aggregation technology [12]. An outline of the disclosure limitation process is shown in Figure 5. After company B performs the disclosure limitation process against tabulation table EncA(TC) by adding noise based on differential privacy, company A decrypts the result to obtain disclosure limitation-completed table T’C. Details of these processes are given in Ref. [12].
3.5 Guaranteeing the Integrity of Each Process in Private Cross-aggregation Technology
Cross-aggregation technology consists of the technologies and data processes described above, which satisfy privacy and security requirements (1) and (2) as long as those series of processes are executed correctly. There is therefore a need to technically guarantee protocol integrity, that is, the correct execution of those series of processes.
Two examples can be given of possible threats that can occur when a series of processes are not correctly executed. In the first one, a user exists who alters the de-identification process and obtains the salt, which holds the possibility of re-identifying IDs and hash values through a brute-force attack. In the second one, the disclosure limitation process is altered and no appropriate noise is added, which generates concern that private information will be disclosed from the output tabulation table.
Guaranteeing program integrity using a TEE can provide a countermeasure to such attacks. This technique is described in another special article in this issue [2].
- Secure matching protocol: A technology that applies an encryption system (homomorphic encryption) capable of processing data in its encrypted form and that performs data coupling and the creation of statistics without mutually disclosing the data of multiple entities.
- Salt: Random data added to the input of the hash function when hashing (see *7) data.
- Hashing: The process of computing a hash value from the original data using a hash function. Since the salt used for hashing is destroyed after the hashing process, it is impossible to compute the original data from the hash value.
- Re-identification: The matching of processed data with original data (personal information, etc.).
- Hash function: A type of one-way function in which obtaining the input character string from the output character string is impossible. It is a function that converts a character string of arbitrary length into a fixed-length character string (hash value). A property of the hash function is that the same character string is output for identical inputs.
- Brute-force attack: A technique used to break a code or deduce passwords by inputting all patterns that deciphered confidential information can possibly take.
- Integrity: The property by which software or data has not been altered.
-
In this article, we presented the issues involved in achieving cross-company ...
Open
In this article, we presented the issues involved in achieving cross-company statistical data usage and summarized the privacy and security requirements that must be satisfied. We also described private cross-aggregation technology developed by NTT DOCOMO and showed how this technology satisfies those privacy and security requirements.
Specifically, we described how the issue of guaranteeing privacy in the process of creating output data could be solved by first irreversibly converting IDs and then executing a series of processes all in an encrypted state thereby satisfying privacy and security requirement (1). We also described how the issue of guaranteeing privacy in output data could be solved by performing the disclosure limitation process through noise addition based on differential privacy in the tabulation table in encrypted state thereby satisfying privacy and security requirement (2). Private cross-aggregation technology achieves cross-company statistical data usage satisfying these privacy and security requirements by appropriately combining the de-identification process, secure aggregation process through secure matching protocol, and disclosure limitation process through noise addition based on differential privacy all in a TEE. Going forward, we aim to use real-world data in collaboration with partner companies to demonstrate the usefulness of private cross-aggregation technology and put it to practical use.
-
REFERENCES
Open
- [1] K. Nozawa et al.: “Solving Social Problems through Cross-company Statistical Data Usage—Overview of Private Cross-aggregation Technology—,” NTT DOCOMO Technical Journal, Vol. 25, No. 1, Jul. 2023.
https://www.docomo.ne.jp/english/corporate/technology/rd/technical_journal/bn/vol25_1/001.html - [2] K. Hasegawa et al.: “Guaranteeing Integrity in Private Cross-aggregation Technology,” NTT DOCOMO Technical Journal, Vol. 25, No. 1, Jul. 2023.
https://www.docomo.ne.jp/english/corporate/technology/rd/technical_journal/bn/vol25_1/003.html - [3] K. Chida, M. Kii, A. Ichikawa, K. Nozawa, K. Hasegawa, T. Domen, T. Nakagawa, H. Aono and M. Terada: “On Anonymization for Equi-Join of Personal Data,” 2022-SCIS, 2022.
- [4] M. Terada: “What is Differential Privacy?”, Systems, Control and Information, Vol. 63, No. 2, pp. 58–63, 2019 (in Japanese).
- [5] R. Agrawal, A. Evfimievski and R. Srikant: “Information sharing across private databases,” SIG- MOD 2003, ACM, pp. 86–97, 2003.
- [6] P. Buddhavarapu, A. Knox, P. Mohassel, S. Sengupta, E. Taubeneck and V. Vlaskin: “Private matching for compute,” Cryptology ePrint Archive, Paper 2020/599, 2020.
- [7] K. Chida, M. Terada, T. Yamaguchi, D. Ikarashi, K. Hamada and K. Takahashi: “A Secure Matching Protocol with Statistical Disclosure Control,” IPSJ SIG Technical Report, Vol. 2011- CSEC-52, No. 12, pp. 1–6, Mar. 2011 (in Japanese).
- [8] K. Chida, K. Hamada, A. Ichikawa, M. Kii and J. Tomida: “Private Intersection-Weighted-Sum,” Cryptology ePrint Archive, Paper 2022/338, 2022.
- [9] C. Dwork: “Differential Privacy,” Proc. of 33rd Intl. Conf. Automata, Languages and Programming-Part II, Vol. 4052, pp. 1–12, 2016.
- [10] M. Terada: “What is Differential Privacy?” Systems, Control and Information, Vol. 63, No. 2, pp. 58–63, 2019 (in Japanese).
- [11] M. Kii, A. Ichikawa, K. Chida and K. Hamada: “A Non-Interactive Two-Party Protocol that Generate Encrypted Discrete Random Numbers for Differential Private Secure Computation,” IPSJ SIG Technical Reports, Vol. 2021-CSEC-92, No. 5, Mar. 2021 (in Japanese).
- [12] M. Kii: “A Secure Sampling Method with a Smaller Table for Differential Privacy,” Proc. of CSS2022, pp. 137–144, Oct. 2022 (in Japanese).
- [13] S. Ushiyama, T. Takahashi, M. Kudo, K. Inoue, T. Suzuki and H. Yamana: “Application of Differential Privacy under Fully Homomorphic Encryption—As an Object of Range Queries—,” DEIM Forum 2021, G25-4z, 2021 (in Japanese).
- [1] K. Nozawa et al.: “Solving Social Problems through Cross-company Statistical Data Usage—Overview of Private Cross-aggregation Technology—,” NTT DOCOMO Technical Journal, Vol. 25, No. 1, Jul. 2023.

