
Special Articles on the Potential of LLM Technologies to Support Business
LLM Utilization—Centered on “tsuzumi”—for Creating Next-generation Machine Translation Experiences
Machine Translation LLM Natural Language Processing
Kenichi Iwatsuki, Kotaro Kitagawa and Daisuke Torii
Engineering Department, Mirai Translate, Inc.
Abstract
Next-generation machine translation experiences created by using LLMs are described in this article. First, it is shown that an LLM developed by NTT—called “tsuzumi”—has two key features, namely, outputting natural and fluent Japanese and preserving paragraph structure. Next, functions of LLMs that support the entire translation workflow, including pre- and post-translation correction of text, summarization, and style conversion, are described.
01. Introduction
-
Until now, research and development on machine translation*1 has focused ...
Open

Until now, research and development on machine translation*1 has focused on how to translate from one language into another while accurately preserving the meaning of the original text. However, when machine-translation services are used for business, translation is only one part of the workflow. If machine translation services could be used to encompass the workflow before and after translation, they could contribute to further reform of business operations and the associated improvement in productivity.
As for natural language processing, classification tasks have traditionally been solved with a relatively high degree of accuracy, but generative tasks have not always been at a practical level. However, Large Language Models (LLMs)*2 have made it possible to obtain satisfactory results even when they handle generative tasks. This possibility is laying the groundwork for creating the next generation of machine translation experiences, which include pre- and post-translation correction of texts, summarization, and conversion of style (Figure 1).
Several LLMs that have been trained using data primarily in English are publicly available. However, translation services deal with multiple languages, including English and Japanese, so these LLMs are not necessarily suitable for translation. On the contrary, the LLM developed by NTT Laboratories—called “tsuzumi”—was trained using a large amount of Japanese documents, and it is expected to be applicable to Japanese documents.
Moreover, while the performance of an LLM improves as parameter size*3 increases, its operating cost generally increases. However, tsuzumi is a relatively lightweight model, and it has been shown to be capable of handling many next-generation machine translation experiences.
In this article, first, the features of translation using tsuzumi are described. Our efforts to create next-generation machine translation experiences using LLMs, including larger-scale translations, are then explained.
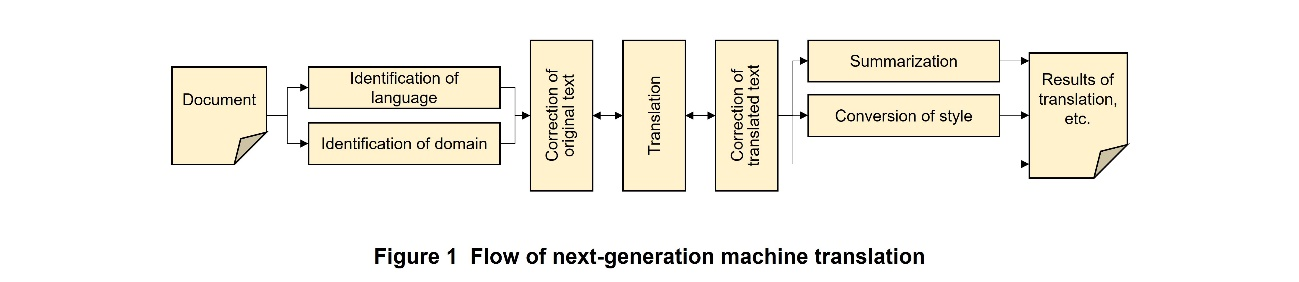
- Machine translation: Automatically translating a document in one language to a document in another language by computer.
- LLM: A natural-language-processing model built by using large amounts of text data. It can be used for more advanced natural-language-processing tasks than conventional language models.
- Parameter size: Total number of matrix elements that make up a neural network.
-
2.1 Features of tsuzumi (Natural, Fluent Japanese)
Open
When translating English to Japanese, it is important that the content of the original English text is accurately reflected; in addition, if the Japanese is easy to read and understand, users who are engaged in obtaining information from English texts can achieve their goals more quickly and thereby improve productivity. tsuzumi is said to be highly capable of Japanese-language processing, and it is expected that when translating, it will output more natural, fluent Japanese sentences.
Example translations by tsuzumi and Neural Machine Translation (NMT)*4 are shown in Figure 2. Unlike English, Japanese has a wide variety of counters, which are difficult to translate properly. As shown in the figure, NMT translates “tents” without a counter, but tsuzumi uses the counter “chō.” In this way, tsuzumi is able to output Japanese that sounds more Japanese.
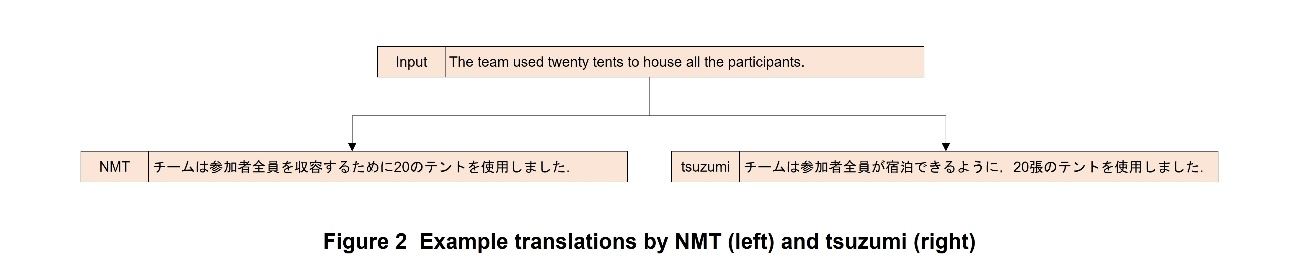
2.2 Improvements to tsuzumi (Maintaining Paragraph Structure)
In most business situations, it is necessary to translate an entire document rather than a single sentence. It is therefore not enough to judge translation accuracy from a single sentence. Since an LLM is said to be able to handle longer contexts than conventional NMT, it is expected to be applied to the translation of entire documents. However, translation using an LLM is problematic because it does not maintain the paragraph structure of a document. For example, when a document consisting of ten paragraphs is translated using an LLM, some parts of the document may be summarized, thereby reducing the document to eight paragraphs; conversely, additional explanations may be added, increasing the number of paragraphs.
To address this problem, we constructed a training dataset for maintaining the number of paragraphs and fine-tuned*5 tsuzumi with the dataset. As a result of this fine-tuning, the rate of maintaining the number of paragraphs was improved from 60% to 90%.
- NMT: In contrast to traditional statistical machine translation, machine translation using neural networks. Although LLMs are also based on neural networks, NMT is conventionally distinguished from LLMs.
- Fine-tuning: Training a base model to specialize in one or more tasks by giving it examples of prompt-completion pairs of those tasks.
-
The efforts of Mirai Translate—who are working to create ...
Open
The efforts of Mirai Translate—who are working to create next-generation machine translation experiences with LLMs—are described hereafter.
3.1 Identifying the Nature of a Document
1) Language Identification
Language identification is the task of identifying the language in which the document to be translated is written. As part of a translation service, either a translation model*6 is prepared for each language or a model that supports multiple languages is prepared; in either case, when machine translation is attempted, it is better to identify the source language. Traditionally, the user selects the source language; however, it is not guaranteed that only one language will appear in the document to be translated, and it may be necessary for the translation model to identify the language at a finer level.
Classification models are commonly used to solve classification problems*7 such as language identification. In that usage case, data from a variety of languages must be prepared, and the model must be trained with that data in advance. However, in the case of LLMs, training is sometimes unnecessary. We experimentally investigated the ability of tsuzumi to identify languages, and the investigation results revealed that tsuzumi can identify English and Chinese, and various other languages such as Catalan and Estonian, even in the case of zero-shot learning*8.
2) Domain*9 Identification
Mirai Translate offers models specifically for patents and legal and financial matters. It is effective to prepare multiple models to handle domain-specific expressions; however, as the number of domains increases to hundreds or thousands, the effort required to select the right model becomes significant, and the cost of training a classifier*10 also increases. These issues can be avoided by using tsuzumi. We experimentally showed that tsuzumi can identify document type (such as news and patents) without having to be trained separately.
3.2 Pre- and Post-translation Correction
In many cases, a document cannot be accurately translated from the input text alone. In the case of Japanese-to-English translation, the input Japanese text may contain vagueness, namely, sentences in which the subject is unclear or the subject and predicate do not match each other, resulting in an incorrect English sentence. Moreover, in English-to-Japanese translation, when translating polysemes (words or phrases with different, but related senses), it is sometimes difficult to determine the appropriate translation from the provided context alone.
Considering the above-described issues, we are working on two tasks: (i) revising Japanese sentences before translating them into English so that they are more suitable for translation and (ii) revising Japanese sentences after they have been translated by using the knowledge accumulated by an LLM. An example of post-translation correction (ii) is shown in Figure 3. From the top to bottom shows the input English sentence, the sentence translated by NMT, and the result of correcting the NMT-translated sentence by GPT-4o. The key word to pay attention to is “the marbles” (underlined in bold). Since “marble” can refer to either a glass bead or the rock called marble (as in reference [2]), it seems difficult to conclude immediately that the translation “marbles” is a mistranslation. Actually, “the marbles” refers to the Elgin Marbles, namely, marble sculptures taken from the Parthenon in Greece, and if that point is not made clear in the translation, the main point of the sentence will be lost. The input English text neither contains the phrase “Elgin Marbles” nor states that the sculptures are from the Parthenon. Nevertheless, the knowledge accumulated by the LLM (GPT-4o) allows it to correct such mistranslations.
![Figure 3 Example of post-translation correction (input sentence is taken from reference [1])](images/image_004_03.png)
3.3 Adjustment of Final Output
1) Summary
In real-world translation situations, it is rare that just a few sentences of a document are translated; more often than not, the entire document must be translated. When it is necessary to get the gist of a large amount of English-written material in a short period of time, it is useful to be provided with not only the full translation results but also a summary of the translation.
The lightweight version of tsuzumi has a parameter size of 7 billion (7B). Even so, we confirmed that it outperforms 13B-sized LLMs when performing zero-shot summarization. What's more, its summarization performance can be significantly improved by fine-tuning.
A general-purpose summarization model does not necessarily meet the needs of users because the information that a summary should include depends on the type of document being translated. For example, the points that need to be summarized differ in the cases of minutes of a meeting and investor-relations materials.
In the case of most academic papers, abstracts are already provided (and can be translated as is), and the content of the summary should be more substantial than that of the abstract. In some fields, mainly the medical sciences, “structured abstracts” have become the mainstream. Structured abstracts consist of multiple sections such as “methods” and “results.” Following this trend, it is conceivable to summarize the content of each chapter of the main text and provide a structured summary. We have confirmed that when tsuzumi is used to summarize a document, it can provide a more accurate summary through fine-tuning.
2) Style Conversion
The same content of a document can be translated using many different styles of expression, and the choice of expression depends on the situation. For example, in English-to-Japanese translation, the choice of using plain style or polite style depends on the document type, and that style cannot always be determined from the original English. In Japanese-to-English translation too, it is sometimes desirable to use more-polite expressions or write more concisely. Style conversion meets such needs.
Style conversion can be considered a kind of translation. However, to apply the same technical framework to style conversion as applied to translation, a considerable amount of training data must be prepared. Moreover, it is only possible to convert text to a predefined style.
Given that condition, we are working on style conversion using an LLM. When GPT-4o is used, a large amount of training data is unnecessary, and it is possible to convert to various styles by adjusting the instructions. For example, the Japanese “Kono tabi wa heisha ibento e sanka shite itadaki arigatou gozaimashita” is translated by NMT as “Thank you for participating in our event this time.” However, when GPT-4o is used to make the style politer, it becomes “I would like to extend my most sincere and heartfelt gratitude to you for taking the time out of your undoubtedly busy schedule to graciously participate in and contribute to the success of our event on this particular occasion.” Alternatively, as a shorter, social-media friendly style, “Thank you for joining our event!” is given by GPT-4o. Such fine-tuning is an LLM's forte, and it can significantly reduce the effort required to manually adjust translation results to suit specific purposes.
- Translation model: A statistical model used for calculating the extent to which words in a pair of sentences—one sentence in the pre-translation language and another sentence in the post-translation language—semantically correspond with each other.
- Classification problem: Assigning an input sentence to one or more of several pre-prepared categories.
- Zero-shot learning: A setting that allows the LLM to perform the task without being given any examples of prompt-completion pairs of the task.
- Domain: A usage scenario in machine translation.
- Classifier: A device that classifies inputs into a number of predetermined classes according to their feature values.
-
The features of tsuzumi-based translation and next-generation ...
Open
The features of tsuzumi-based translation and next-generation machine translation experiences created by using LLMs were described in this article. It was shown that tsuzumi-based translation outputs more Japanese-like Japanese and maintains paragraph structure. As for next-generation machine translation experiences, each function of a framework that uses an LLM to support the entire translation workflow was described. Some functions are based on LLMs with extremely large parameter sizes, such as GPT-4o; accordingly, in the future, we plan to continue developing technology using the next version of tsuzumi to create next-generation machine translation experiences at lower cost.
-
REFERENCES
Open
- [1] C. Mason: “Sunak cancels Greek PM meeting in Parthenon Sculptures row,” BBC, Nov. 2023.
 https://www.bbc.com/news/uk-politics-67549044
https://www.bbc.com/news/uk-politics-67549044 - [2] T. Konishi and K. Minamide: “Genius English-Japanese Dictionary,” Taishukan Publishing, Apr. 2001.
- [1] C. Mason: “Sunak cancels Greek PM meeting in Parthenon Sculptures row,” BBC, Nov. 2023.

