
Special Articles on the Potential of LLM Technologies to Support Business
Personalized Dialogue Technology toward Human-centered AI
Personal Knowledge Graph LLM Episodic Memory
Satsuki Shimada, Keisuke Fujimoto and Norihiro Katsumaru
Service Innovation Department
Abstract
Thanks to the appearance of LLMs, dialogue systems have improved significantly in performance, and today, they are being used in a wide variety of fields including customer support. There are also great expectations for personal assistants that use dialogue systems. Against this background, we have developed technology for optimizing dialogue oriented to the individual with the aim of constructing a long-term relationship between the user and dialogue system. With this technology, the system appropriately extracts relevant locations from past, remembered dialogues and obtains embedded expressions from dialogue history and knowledge graphs to follow user interests and concerns.
01. Introduction
-
The evolution of modern Artificial Intelligence (AI) is having a huge ...
Open

The evolution of modern Artificial Intelligence (AI) is having a huge impact on our daily lives and way of working. As part of this development, generative AI*1 is rapidly attracting attention in the field of natural language processing*2 as it comes to play a major role particularly in the expansion of interactive systems. While conventional interactive systems issue formulaic responses based on previously defined scenarios, interactive systems based on a Large Language Model (LLM)*3 have the ability of generating natural responses to user utterances in a flexible manner.
Dialogue produced by generative AI is not limited to the simple exchange of information. It also enables emotional and sympathetic responses and complex forms of communication that make it applicable to many fields such as customer service, education, medical care, and entertainment. Additionally, with improved language abilities, such interactive systems are taking on the role of a personal assistant*4 tailored to user needs.
However, these systems still have some aspects that are incomplete. For example, while progress is being made in achieving natural dialogue and generating responses to complex questions, there are still limits to understanding context and obtaining a fine understanding of user emotions as well as maintaining consistency in dialogues over the long term. Moreover, in current AI systems, the problem remains of how to appropriately respond to diverse user intentions and emotions.
At NTT DOCOMO, with the aim of achieving human-centered AI, we have developed technologies for obtaining important portions of past exchanges with the user, understanding user interests and concerns using an episodic memory mechanism and past utterances, and making a transition from one topic to another in reflection of the current dialogue (hereinafter referred to as “personalized dialogue”). This article describes these technologies.
- Generative AI: A field in AI; a technology or model that aims to generate new content or information based on data.
- Natural language processing: Technology to process the language ordinarily used by humans (natural language) on a computer.
- LLM: A language model trained using a large volume of text data; it excels in understanding language and generating text and documents.
- Personal assistant: The role of providing support for individuals and organizations to enable them to efficiently perform specific tasks or work.
-
2.1 RAG
Open
1) Overview
Although an LLM is capable of answering a variety of questions based on previously learned knowledge, it is limited with respect to questions stemming from recent news or specialized information. To deal with this issue, Retrieval-Augmented Generation (RAG) [1] appeared as a technology for generating answers after integrating external knowledge in an LLM. The RAG process is broadly divided into three phases: indexing, retrieval and generation.
To begin with, the indexing phase divides the source documents targeted for use into easy-to-use chunks*5 for use by generative AI to generate answers. It then turns these chunks into vectors using an embedding model*6 that converts natural sentences into feature quantities and stores those vectors in a vector database.
Next, the retrieval phase uses the same embedding model used in indexing to turn input from the user (query*7) into a vector. It then calculates the similarity between that vector expression and the chunks in the vector database and extracts the top K chunks in terms of similarity. These extracted chunks are then added to the prompt*8 extended context*9.
Finally, the generation phase synthesizes the chunks extracted from the query and the retrieval phase, inputs them into the LLM, and generates an answer. The above steps constitute the RAG mechanism.
2) Issues
There are a number of issues with RAG. Since RAG is designed with the aim of obtaining information from specific text segments, it cannot sufficiently deal with queries spanning the entirety of an expansive corpus*10. In addition, an LLM used with RAG has a limited context window*11 and information may be lost in the middle of a long context window. It is also difficult to extract with high accuracy information from multiple documents related to a query, so the accuracy of the generated answer is limited. These issues therefore become constraints when RAG attempts to deal with questions against an entire large-scale dataset*12.
2.2 Graph RAG
1) Overview
A technique that has been attracting attention in recent years to deal with these RAG issues is Graph-based RAG (Graph RAG) [2]. Graph RAG uses a knowledge graph and an LLM to overcome the problems faced by RAG in the past and achieve high-accuracy information retrieval and generation.
A knowledge graph is a knowledge network that systematically connects various types of knowledge and represents that knowledge in a graph structure. Here, any association between different items of information is shown by representing the relationship that exists between individual things, phenomena, etc. by a node*13 (point) pair and an edge*14 (line). This structure enables flexible extraction of information, and as such, it is expected to solve the above RAG issue stated as the “difficulty of extracting related information with high accuracy.”
2) Mechanism
The following describes the Graph RAG mechanism.
First, Graph RAG divides the source documents to be used by generative AI for generating answers into chunks. The LLM then identifies individual things and phenomena from each chunk and the relationships between them and extracts graph data representing those relationships as nodes and edges. After that, the LLM is used to generate explanatory text and embedded expressions from the chunks corresponding to graph elements (nodes and edges).
Next, a community detection algorithm (such as the Leiden algorithm*15) is used to divide the extracted graph data into node groups (communities) each having nodes that are closely related to each other. A summary is also generated for each community (community report) based on explanatory text generated for each community. A community report is useful for understanding the overall meaning of a specific topic.
Finally, given the input of a query, Graph RAG generates an answer using a vector similarity search based on embedded expressions and a graph search based on community reports.
The above constitutes the Graph RAG mechanism. A key feature of Graph RAG is that it can explicitly determine complex relationships between different items of information by using a knowledge graph. This feature enables multi-step reasoning and generation of highly accurate answers to complex questions.
2.3 Application of RAG to Personalized Dialogue
To achieve human-centered AI, technology for transitioning to topics of interest to the user according to the content of the dialogue is important. In this regard, Graph RAG as such cannot optimize the provision of a knowledge graph as external knowledge for each user, and as a result, the information that it outputs takes on a standardized form. We here describe HippoRAG [3] that incorporates knowledge graphs and the mechanisms of human memory as research related to the optimization of dialogue for the individual.
Inspired by the human memory system, HippoRAG is a RAG method that combines knowledge graphs and the Personalized PageRank algorithm*16. It is divided into two main phases: offline indexing and online retrieval.
First, similar to Graph RAG, the offline indexing phase uses an LLM to construct a knowledge graph to be used by the online retrieval phase.
Next, the online retrieval phase extracts key words from the query and specifies nodes similar to meaning from the knowledge graph constructed in the offline indexing phase as query nodes based on cosine similarity*17. It then searches the knowledge graph using the specified query nodes as starting points. At this time, the Personalized PageRank algorithm is applied to calculate the importance of related nodes in the periphery of the query nodes. The final response is generated using the LLM based on the source documents for which the importance of the obtained nodes is high. In this way, a response that includes information most relevant to the query is generated.
The above constitutes the mechanism of HippoRAG.
The most outstanding feature of HippoRAG is calculation of the importance of knowledge-graph nodes using the Personalized PageRank algorithm. This algorithm consists of a mechanism for tracing relevance using specific items of information (nodes) as starting points so as to prioritize the evaluation of information that is highly relevant to the query. As a result, HippoRAG can efficiently find information relevant to the query from source documents and reflect that information in the dialogue. In addition, while constructing a knowledge graph for each user and giving it to an LLM is difficult from the viewpoint of computational cost, HippoRAG technology can change weights inside a single graph thereby lowering the computational cost while serving as a reference for personalized dialogue. On the other hand, it is still difficult even with this technology to make a transition in topics of interest to the user according to the content of the dialogue. This is because the mechanism for searching the knowledge graph using query nodes as starting points is the same for any user and that the weighting of the entire graph does not change for each user. As a consequence, personal interests and context are not fully reflected.
- Chunks: Refers to the dividing of text into meaningful units. Generally indicates specific structures or segments having meaning within a sentence.
- Embedding model: A model for converting text, images, etc. into real-number vectors to make them easy to use by computers. BERT is a well-known embedding model.
- Query: A database query (processing request).
- Prompt: A command given to a computer or program. In the context of an LLM, it refers to an instruction or an input statement in a natural language format for controlling LLM output.
- Context: Peripheral information given to an LLM according to the content of the dialogue.
- Corpus: A language resource consisting of a large volume of text, utterances, etc. collected and stored in a database.
- Context window: The length of text (number of tokens) that a model can process at one time.
- Dataset: A group of data collected for a specific objective or analysis.
- Node: One element making up a graph. A vertex.
- Edge: One element making up a graph. A link connecting a pair of nodes.
- Leiden algorithm: An algorithm for network clustering and community detection.
- Personalized PageRank algorithm: A method for evaluating the importance of a node with respect to a specific node (page).
- Cosine similarity: A numerical measure of how close the directions of two vectors are.
-
3.1 Overview
Open
NTT DOCOMO has developed technology for estimating interests and concerns from user dialogue history and making transitions in topics. System configuration is shown in Figure 1. This system is broadly divided into an (1) episodic memory section and (2) graph processing section. In (1), the system receives user utterances and obtains related episodic information from dialogue history, and in (2), it obtains a knowledge graph individualized by embedded expressions (personal knowledge graph) based on user utterance information and knowledge graphs reflecting general knowledge.
The foundation for the method that we propose here is the knowledge gained from related research in the development of Graph RAG and HippoRAG. Referring to the Graph RAG approach, we adopted the framework for explicitly determining complex relationships between different items of information by using a knowledge graph. Additionally, inspired by the use of the Personalized PageRank algorithm in HippoRAG, we adopted the mechanism of tracing relevance using specific nodes as starting points. In this way, we made it possible to prioritize the extraction of information that is highly relevant to the query and to achieve efficient and flexible use of information.
The following describes each of the above processes.
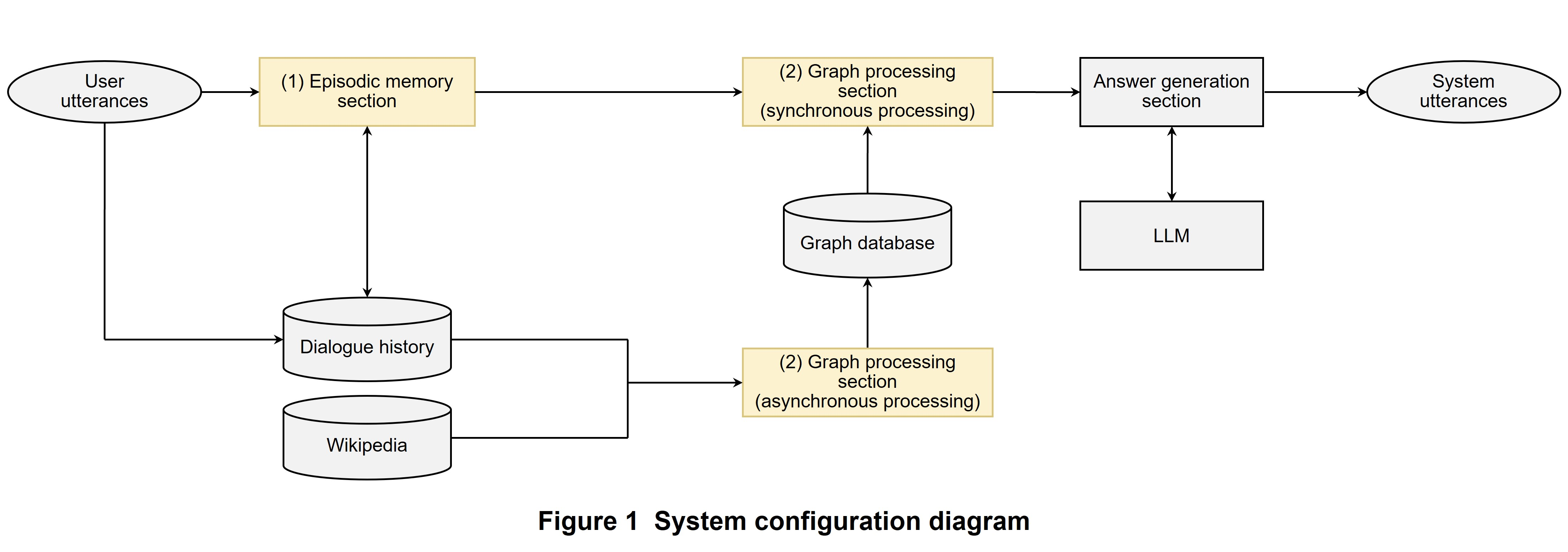
3.2 Episodic Memory Section
The episodic memory section was developed as a system for obtaining episodic information related to user utterances with reference to memory processing in Generative Agents (Interactive Simulacra of Human Behavior) [4].
This episodic memory section is divided into a memory generation section and memory extraction section as described below.
1) Memory Generation Section
The memory generation section generates and manages information needed by the memory extraction section. It stores dialogue history, embedded vectors, persona information*18, and importance scores in a database. For importance scores, a prompt is defined for calculating importance with respect to utterances and importance is evaluated using an LLM.
2) Memory Extraction Section
The memory extraction section obtains relevant memory according to user utterances based on the database constructed by the memory generation section. We here consider (1) importance score, (2) embedded similarity, and (3) currency. Specifically, the following logic is applied.
(1) Importance score
Importance evaluated by the memory generation section is given to each utterance and which memory to consider is prioritized the higher is this score.
(2) Embedded similarity
Similarity is calculated using embedded vectors between the query and past utterances. Memories with higher similarities are considered to be highly relevant.
(3) Currency
Priority is given to those memories that are more current. As a result, recent events are treated as information that is more relevant.
As a result of this approach, the above system achieves a dynamic and interactive user experience by efficiently managing dialogue history and persona information with the user and extracting meaningful information based on user utterances. In this way, the agent*19 of this system is able not only to accumulate information but also to obtain new insights using information.
3.3 Graph Processing Section
The graph processing section is divided into asynchronous (non-real-time) processing and synchronous (real-time) processing.
In asynchronous processing, graph (a) created on the basis of general-knowledge summary information and graph (b) created based on past behavior are summed up as graph (ab), which is then used for training in solving the link prediction problem*20. After training, vector information is given to each node included in graph (ab).
In synchronous processing, (1) topics are obtained from the query and (2) related topics are obtained by distance calculations based on those topic words and vector information obtained in (1). Then by inputting the topic words and related topics into an LLM prompt, (3) an answer is generated by the LLM. The following describes each of these mechanisms.
1) Asynchronous Processing
A knowledge graph basically consists of two nodes (head node and tail node) and an edge. Here, the relationship between these nodes is expressed by the edge (head entity – (relation) → tail entity).
Graph (a) corresponds to a knowledge graph created using an LLM based on general-knowledge summary information (e.g., FM Hokkaido – (broadcasting) → radio program).
Graph (b), meanwhile, corresponds to a graph created on the basis of focus words that express words or concepts that attract attention from past behavior.
Now, graph (ab) created by summing up the above two graphs is converted into vectors by the TransE [5] method and the link prediction problem is solved. In this way, vector information for each node and edge of the graph is obtained.
2) Synchronous Processing
If the topic words extracted from the query are included in nodes of graph (ab), the system obtains related topics (related nodes) through graph calculations and includes them in a prompt given to the LLM to generate an answer. Furthermore, if multiple target topics happen to be extracted, one is randomly selected.
(1) Get topics
The system extracts topic words from the query based on the named entity recognition model*21.
(2) Get related topics
The goal here is to obtain related topics that the user will likely be interested in by performing distance calculations using vector information against the query. Referencing both the topic words obtained in step (1) and graph (ab), this operation extracts nodes in graph (ab) within N hops*22 from those topic words and with a degree*23 of M or greater (where N and M are each a hyperparameter*24) and treats those nodes as candidates of related topics. The system then obtains those candidates of related topics and the vector information tied to the user, performs distance calculations using the vector information of both, and obtains a list of related topics whose distance is close to the user.
(3) Answer generation by LLM
The system includes the topic words obtained in step (1) and the related topics obtained in step (2) in a prompt as shown in Figure 2.
prompt (conventional method (Conv.)) used for making a comparison with our proposed system is shown in Figure 3.

- Persona information: Refers to a fictitious and symbolic user image with respect to a provided product or service.
- Agent: In this article, software that acts on behalf of a user or other system and functions as an intermediary between multiple elements.
- Link prediction problem: Prediction of whether there is a specific relationship between a certain node and another node.
- Named entity recognition model: A model using natural language processing technology for extracting specific “proper nouns” from text data.
- Hops: A term that expresses the number of steps taken when tracing the relationship between nodes in a graph. Specifically, it is the number of edges passed through to get from a certain node to another node (relevance).
- Degree: A term from graph theory that indicates the number of edges connected to one vertex (node).
- Hyperparameter: A value set at the time of training. Since performance will vary depending on the value set, it must be optimized to obtain the best performance.
-
4.1 Comparison of Existing Method and Proposed Method
Open
1) Experiment Overview
Using an example of a simple user prompt, we evaluated the output results of the existing method and the proposed method using RAG with a personal knowledge graph. Specifically, the user utterance was “I'm thinking of going to Hokkaido. Can you recommend any tourist spots?” Here, with respect to graph (a) in asynchronous processing, the system obtains general-knowledge summary information with category = “Hokkaido” and creates graph (b) from the subject's dialogue data. The number of triplets*25 in graph (ab) was approximately 190,000. Together, hyperparameters related to the topics were set as N = 1, M = 2, and K = 9 and the LLM was GPT4*26.
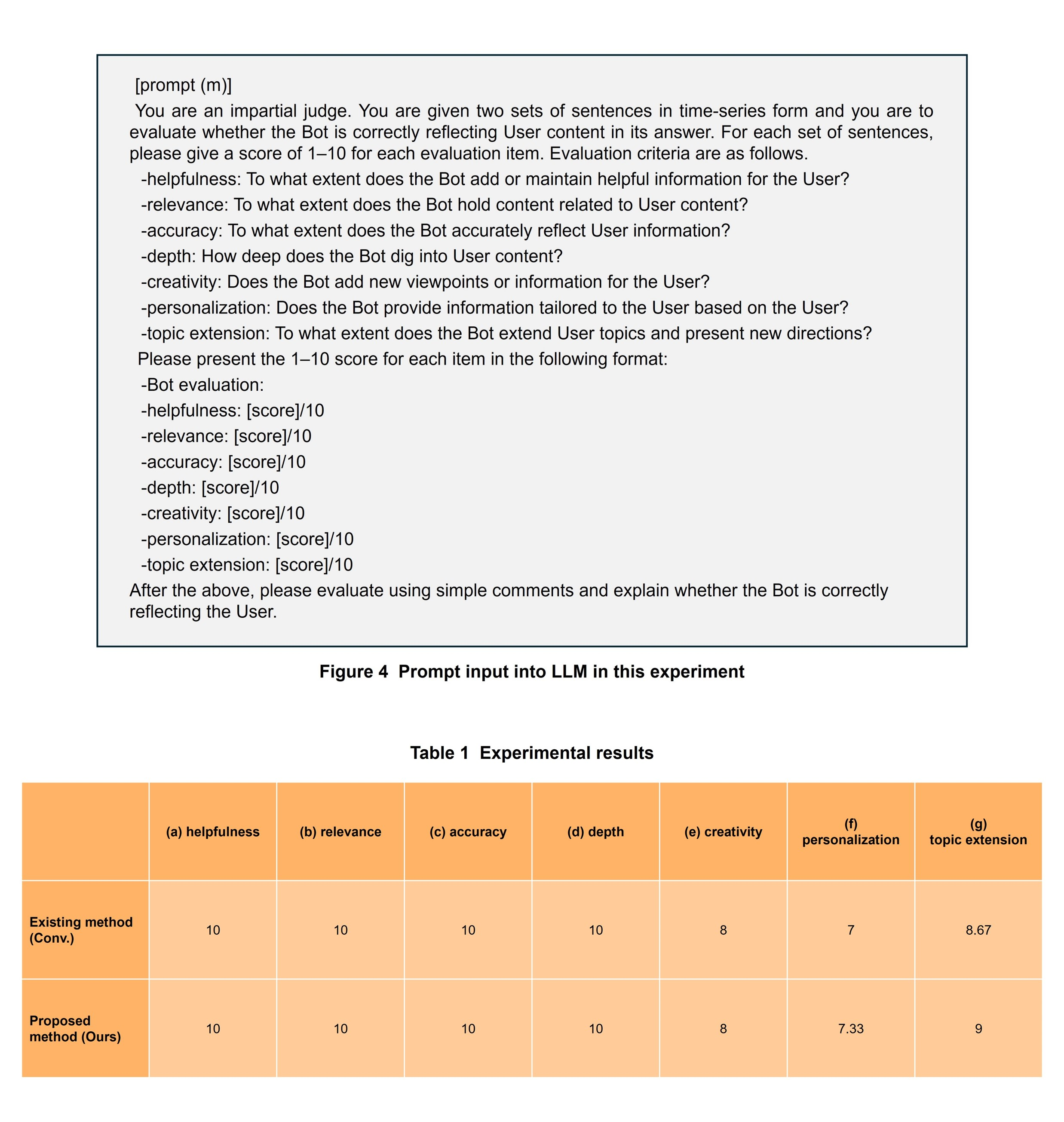
In the evaluation of this experiment, we used the LLM-as-a-judge [6] approach to evaluate answer generation by an LLM for evaluation use. Here, we used GPT4 as the LLM for evaluation use and input the prompt shown in Figure 4.
In this experiment, verification was performed in Japanese and the prompts were given in Japanese as well.
2) Experimental Results
We evaluated the answers generated by the existing method (Conv.) and proposed method (Ours) by the LLM-as-a-judge approach. The values for each item averaged over the results of multiple users are listed in Table 1 and the results of answer generation are listed in Table 2.
From Table 1, it can be seen that there is no difference between the existing method and proposed method from the viewpoints of (a) helpfulness, (b) relevance, (c) accuracy, (d) depth, and (e) creativity but that the proposed method is slightly better than the existing method from the viewpoints of (f) personalization and (g) topic extension. Personalization, however, received a lower score than the other evaluation viewpoints all around, so we raise it as a future issue for improvement.
Next, on comparing the existing method and proposed method, Table 2 shows that, while the existing method proposes typical tourist spots, the proposed method proposes more detailed tourist spots. In particular, “Kamiyubetsu Onsen” is a related topic obtained by synchronous processing (2) in the graph processing section.

4.2 Verification of Personalized Dialogue Using the Episodic Memory Section and Graph Processing Section
1) Experiment Overview
We verified whether topics of interest could be presented based on the content of the dialogue with the user by combining the episodic memory section that extracts important content from dialogue history and the graph processing section that generates answers according to a personal knowledge graph and LLM. We performed this experiment in the following two steps.
- Prior conversation: The user chats with an agent 30 times and user interests and concerns are extracted from those chats.
- Verification conversation: Using a trip to Hokkaido as a theme, the agent recommends tourist spots to the user.
In addition, we performed the verification conversation under three different conditions as follows and compared output results.
- Existing method
- Proposed method (1) (RAG using a personal knowledge graph)
- Proposed method (2) (RAG using a personal knowledge graph and episodic memory)
2) Experimental Results
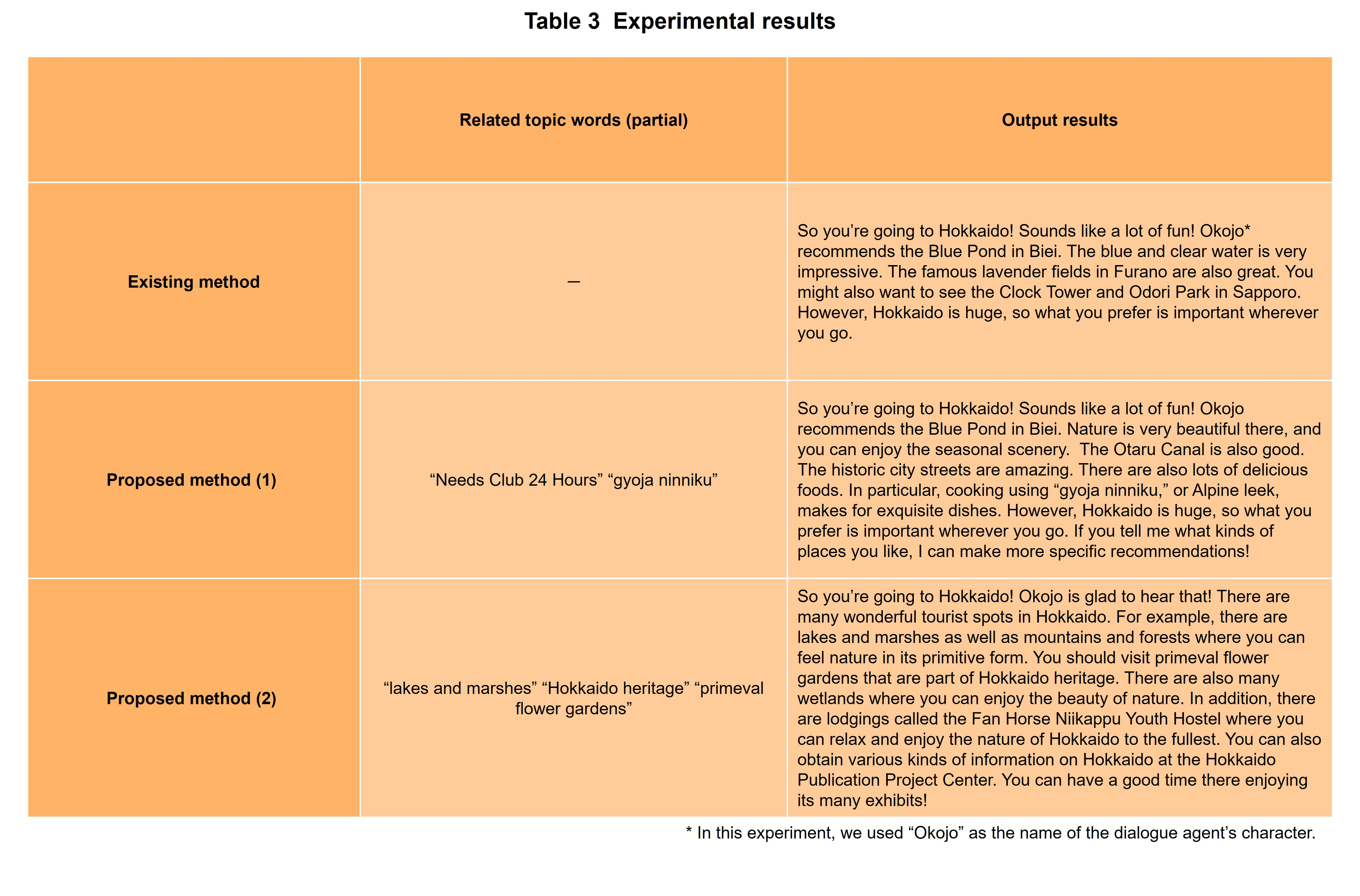
Experimental results are listed in Table 3.
The existing method provides sightseeing information that mainly covers Hokkaido on the whole. No content specific to the user can be seen. This answer centers about general sightseeing information and the degree of personalized information is low.
Proposed method (1) supplements general sightseeing information with mention of a unique regional food called “gyoja ninniku” or Alpine leek. This method obtains related topic words using a knowledge graph with respect to the keyword “Hokkaido,” which enables it to reflect “gyoja ninniku” in the dialogue within a natural context.
Proposed method (2), meanwhile, develops a conversation centered about tourist spots involving “nature.” This method uses an episodic memory section to obtain episodic memory regarding “nature” as information related to Hokkaido from past dialogues. It then searches a knowledge graph based on that information and obtains topic words like “lakes and marshes,” “Hokkaido heritage,” and “primeval flower gardens” that should also be of interest to the user. Combining episodic memory and RAG based on a personal knowledge graph makes it possible to provide content more in tune with user interests and concerns.
In this way, we consider that the proposed method is better than the existing method at personalizing topics based on user interests and concerns by effectively using the user's dialogue history and a personal knowledge graph.
- Triplets: A triplet is three elements consisting of subject, predicate, and object that represent the basic unit for concisely expressing the relationship between targets.
- GPT4: A large language model provided by OpenAI.
-
This article has described the design concept of the WIDESTAR III ...
Open
This article described technologies for optimizing dialogue tailored to the user with the aim of achieving human-centered AI. Specifically, we developed technology (Graph RAG) that presents related topics matching personal interests based on the content of dialogue and we combined this with technology called episodic memory that extracts important content from the history of past exchanges. In this way, we achieved a system that broadens the range of topics not only from current utterances but also from past utterances. Going forward, we plan to incorporate not only dialogue content but also personal behavior such as travel memories and store purchases in Graph RAG and episodic memory. Our goal here is AI that is more deeply centered on the user as an individual.
-
REFERENCES
Open
- [1] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel and D. Kiela: “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp. 9459–9474, Jul. 2021.
 https://proceedings.neurips.cc/paper_files/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
https://proceedings.neurips.cc/paper_files/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html - [2] D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt and J. Larson: “From Local to Global: A Graph RAG Approach to Query-Focused Summarization,” arXiv preprint arXiv:2404.16130, Apr. 2024.
https://arxiv.org/abs/2404.16130 - [3] B. J. Gutiérrez, Y. Shu, Y. Gu, M. Yasunaga and Y. Su: “HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models,” arXiv preprint arXiv:2405.14831, May 2024.
https://arxiv.org/abs/2405.14831 - [4] J. S. Park, J. C. O'Brien, C. J. Cai, M. R. Morris, P. Liang and M. S. Bernstein: “Generative Agents: Interactive Simulacra of Human Behavior,” Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, Oct. 2023.
https://dl.acm.org/doi/10.1145/3586183.3606763 - [5] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston and O. Yakhnenko: “Translating Embeddings for Modeling Multi-relational Data,” Advances in Neural Information Processing Systems 26 (NIPS 2013), pp. 2787–2795, Apr. 2014.
https://proceedings.neurips.cc/paper_files/paper/2013/hash/1cecc7a77928ca8133fa24680a88d2f9-Abstract.html - [6] L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez and I. Stoica: “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,” Advances in Neural Information Processing Systems 36 (NeurIPS 2023), pp. 46595–46623, Oct. 2024.
https://proceedings.neurips.cc/paper_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Abstract-Datasets_and_Benchmarks.html
- [1] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel and D. Kiela: “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp. 9459–9474, Jul. 2021.

