
Recommendation Engine with Serendipity Using Content Metadata
Recommendation Machine Learning Natural Language Processing
Kunihiro Aiba, Wataru Akashi and Takeshi Kato
Service Innovation Department
Taku Ito
Product Design Department
Abstract
Content recommendation using a recommendation engine is actively performed on video distribution sites, etc. There are various algorithms for this, but there is an issue that recommended content is biased toward popular productions to increase the click rate in recommendations that use the user’s behavior history. To address this issue, NTT DOCOMO has developed a recommendation engine that can provide new insights by utilizing content metadata such as genre and synopsis to provide not only popular content with a high click rate, but also content that is of interest to users.
01. Introduction
-
In recent years, on video distribution sites, Electronic Commerce (EC) sites ...
Open

In recent years, on video distribution sites, Electronic Commerce (EC) sites*1 and social media, etc., advertisement delivery and matching services that use a mechanism to perform calculations without identifying individuals to make recommendations (content recommendation) based on the user’s behavior history are becoming mainstream. The purpose of recommendations varies depending on the service, but in general, it is often to provide the user with new discoveries, encourage them to browse*2, and encourage them to make purchases. For such recommendations, there is a wide range of logic, from simple rankings of popular content to advanced learning and prediction techniques using machine learning*3, etc. based on usage history.
With recommendation engine development, particular focus should be on the fact that the content of recommendations is calculated based on user history. Content automatically generated based on user history often reflects the access/browsing characteristics of the content (page), so it is necessary to consider an appropriate algorithm for each recommendation display frame of the content (page). An issue to be considered is the phenomenon of displayed content being biased towards the popular content. For example, if only a list of popularity rankings composed of popular content is displayed, displayed content can achieve a certain click rate*4, but other content cannot be displayed, and users who have seen the popular content once will leave the service.
In the previous article in this journal [1], we presented a solution to the recommendation bias by devising an algorithm. Since then, we have developed a new logic that provides the user with new discoveries and awareness (serendipity) though a new approach that considers not only the user’s history but also content metadata. In a service that actually used an engine that adopted this logic, we were able to increase the number of types of content that were clicked and clicks on the entire home screen, and present recommendations with serendipity. In this article, we describe issues that need to be considered in recommendations, the applied algorithm, and effects of the algorithm in actual services.
- EC site: A Web site that sells products and/or services.
- Browse: Moving from one Web page to another for viewing by users on a Web site.
- Machine learning: A mechanism allowing a computer to learn the relationship between inputs and outputs, through statistical processing of example data.
- Click rate: The ratio of the number of times a user actually clicks on content to the number of times the recommendation engine displays the content.
-
2.1 Issues with Recommendations
Open
In this article, we introduce two major issues as representative issues in current recommendation systems.
1) The Cold Start Issue
In general, highly accurate results cannot be obtained until the user’s action data is accumulated. Basically, the recommendation engine learns based on user history, so if the history is small in the first place, it is not possible to judge what is optimal for the user, and it is not possible to recommend content that leads to migration and purchases. This is a common issue when new services are launched. However, the cold start issue exists even with existing services - when new content comes in, it is not possible to obtain information in advance about who clicked on that content, so recommendations cannot be made.
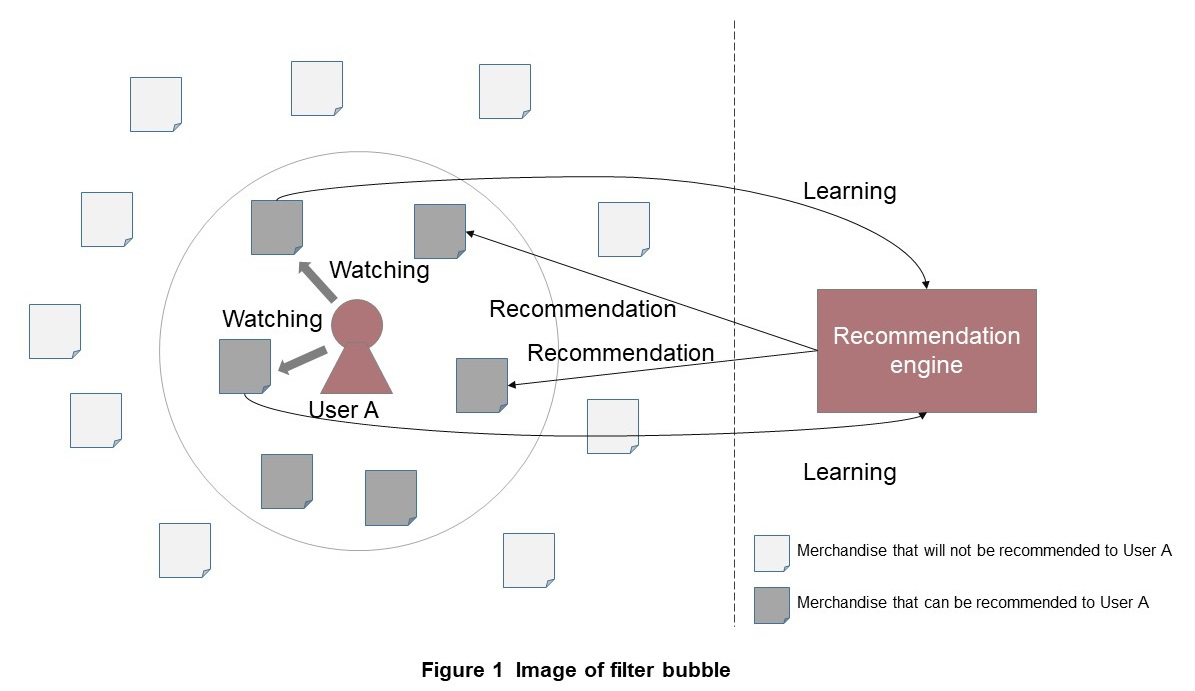
2) The Filter Bubble Issue
This issue occurs when the cycle of learning user actions and presenting optimal content is repeated. At such times, the user is presented with only a certain range of content related to the user’s history and is separated from other content that may have been of interest. In this situation, which is called a filter bubble, the user is isolated and only provided filtered information. This is a major issue with content recommendation (Figure 1). Various solutions have been studied, but it is necessary to match them appropriately to the service.
2.2 The Importance of Serendipity
Serendipity is an important concept in recommendation. Serendipity is interpreted as a fortunate chance encounter. In recommendation, the situation where the recommendation engine presents content that the user could not find on their own in the past and gets the user to click on it is often assessed as serendipitous. Taking the purpose of the recommendation engine into account, which is to give users new discoveries and encourage them to browse and purchase, serendipity is considered to be an important index along with the click rate. Considering this in conjunction with the issues mentioned above, in situations where there are no clicks on new content and a cold start issue arises as in 1), recommendations cannot be displayed to users who might have been looking for that content, which results in significant loss for the content provider. In addition, in services where the filter bubble issue described in 2) occurs, users are only presented with similar categories and content, so serendipity is considered to be low. The issue of recommendation is also an issue of serendipity, thus, thinking about serendipity leads to solving the issue of recommendation. Therefore, we built a recommendation engine with an algorithm that considers serendipity.
-
3.1 Overview
Open
To improve the serendipity in recommendations, NTT DOCOMO built a recommendation engine that can consider not only the user’s history but also the information about productions available on a video distribution site. The engine performs the following three processes.
- Vectorization of metadata of productions
- Acquisition of user vectors
- Model learning considering production and user vector information
By performing the calculations in the above order, it is possible to present productions that contain the user’s favorite things as metadata while taking into account the user’s history. As a result, recommendations that encourage new discoveries are achieved. This technology can be applied regardless of the domain*5 as long as it can use metadata. We describe its application in video services as an example.
3.2 Vectorization of Metadata of Productions
To utilize the metadata of each production to make recommendations, we used a technique that acquires natural language*6 as multi-dimensional vectors (distributed representations*7) so that metadata can be converted to a form that is easy for the machine learning model installed in the recommendation engine to learn. As a method for vectorization, we trained the model so that the words appearing in the same production are close to each other, for the metadata obtained from the production, such as the title, genre, and detailed description. This makes it possible to acquire vectors so that productions with the same words are naturally close to each other, and that words in titles and genres, titles and detailed descriptions, and genres and detailed descriptions are naturally close to each other.
3.3 Vectorization of Information of Users
Next, to let the model learn which productions the user likes, we also created vectors for the user side. Specifically, we created vectors by averaging the vectors calculated for each title, genre, and detailed description of productions that the user has viewed in the past. As a result, it is possible to obtain vectors representing the user’s favorite titles, genres, and detailed descriptions.
3.4 Learning Based on Vector Information
We used a technique called DeepFM [2] to recommend the most suitable productions to the user based on the obtained vectors. DeepFM is a coined word that combines Deep Learning and Factorization Machine (FM) [3], and as the name suggests, it has both features of deep learning and FM. Simply put, deep learning is a learning method that uses multi-layered neural networks*8 and refers to learning relationships between feature values using a huge number of parameters. An FM is a model devised to appropriately consider the interaction between multiple feature values and has shown higher performance in the field of recommendation. DeepFM is an appropriate combination of these two and has strengths in both high prediction performance by deep learning and interaction consideration by FM. Input data (explanatory variables) and correct data were given to this DeepFM to train it. Here, the input data (explanatory variables) are the above-mentioned production vectors and the user vectors. The correct data is 1 if the input data is a pair of a production and a user who has viewed it in the past, and 0 otherwise (Figure 2).
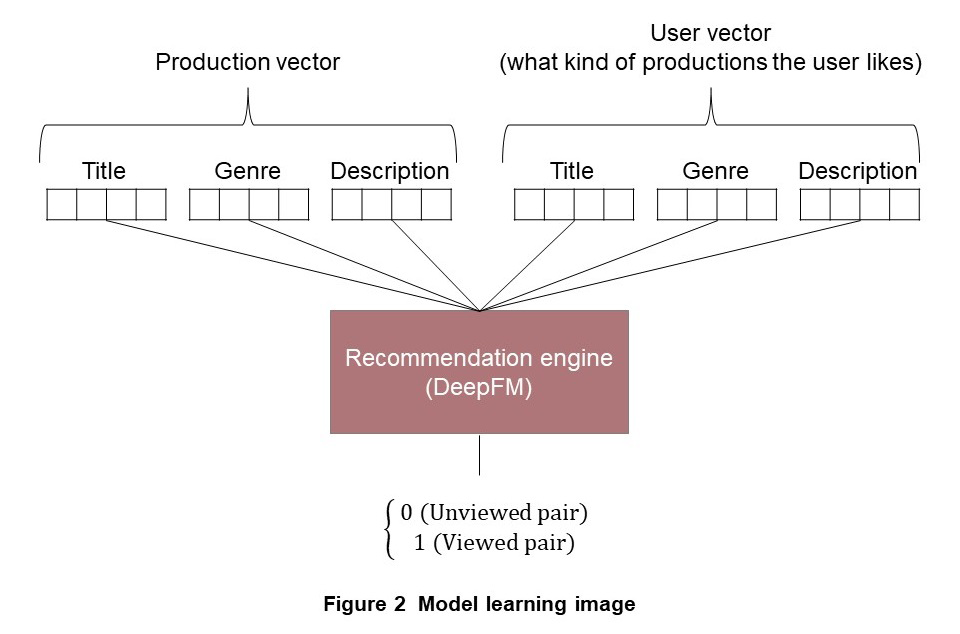
As a result, it is possible to learn what kind of productions are preferred by people who like certain kinds of productions, taking into account the interaction of the titles and genres of the productions. The result of inference in the model learned in this way can be regarded as a probability representing pseudo-viewability. In addition, because this technology uses metadata to make inferences, it is possible to calculate scores and make recommendations even for productions that have not been clicked even once, which solves the cold start issue to a degree.
- Domain: A usage scenario in machine translation.
- Natural language: A language such as Japanese or English. In this article this mainly refers to text such as sentences.
- Distributed representation: A vector representation of natural language.
- Neural network: A representation of the neural network inside the human brain by a numerical model consisting of an input layer, middle layers, and output layer.
-
4.1 Results of Application to the docomo TV Terminal (Set-top Box)
Open
We applied this recommendation technology to the “recommendation frame for you” (hereafter referred to as a “recommendation frame”) on the home screen for a docomo TV Terminal*9 [4], which is our actual service (Figure 3). For verification, we conducted an A/B test*10 between this engine and a conventional general machine learning model and obtained the following characteristic two results.
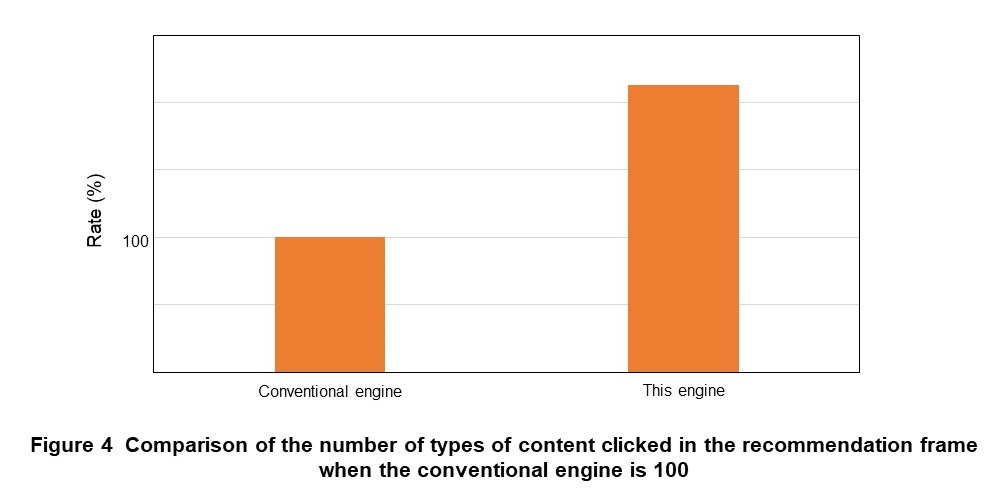
- More than double the types of content were recommended by the engine and clicked compared to the conventional machine learning model (Figure 4)
- The number of clicks on the entire home screen of the service increased compared to the conventional machine learning model (Figure 5)
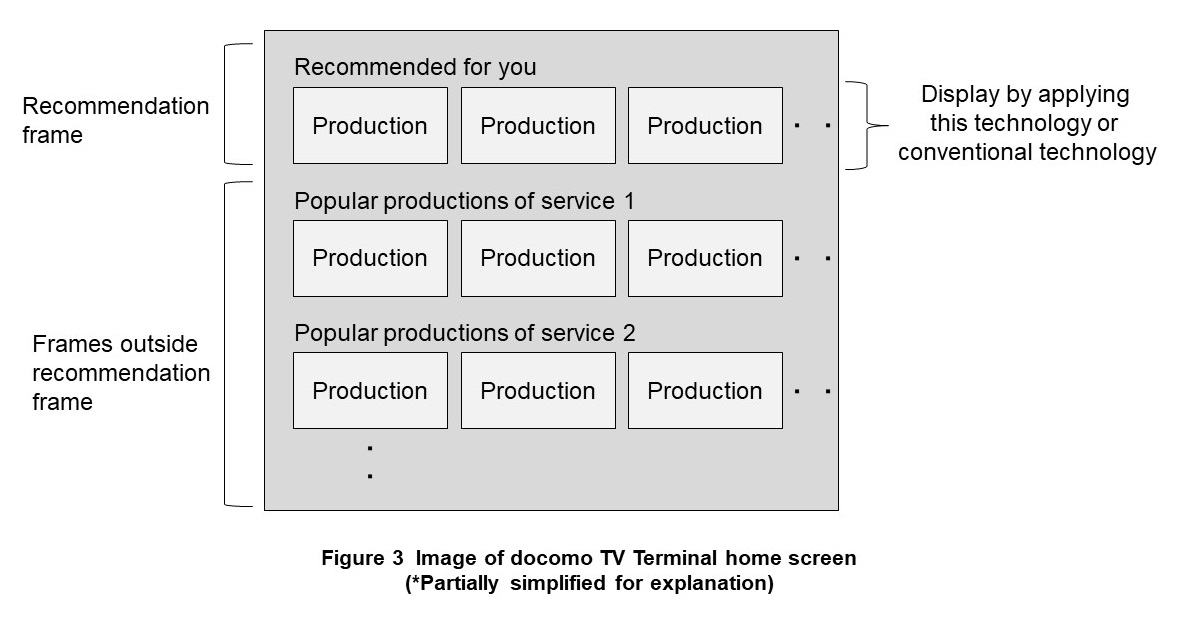
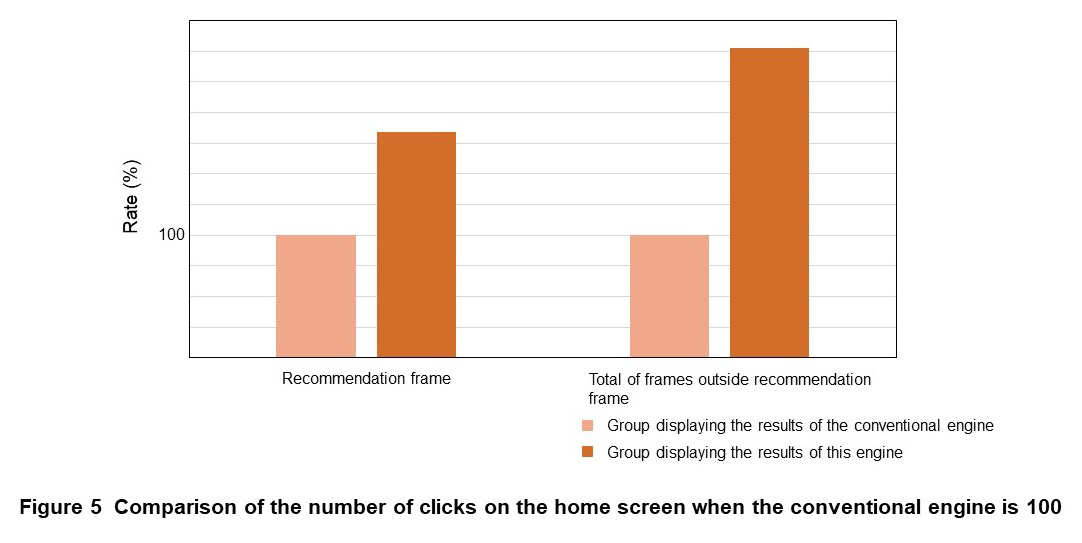
Here, as shown in Fig. 3, the home screen of the docomo TV terminal service has several recommendation frames, including the target of the A/B test, and frames that display the popularity ranking of each DOCOMO video service (frames outside the recommendation frame). Especially for (2), there was a difference between the increase in the number of clicks in the recommendation frame and the increase in the number of clicks in frames outside the recommendation frame. We discuss these influences and reasons.
4.2 Increased Viewing Content Coverage
In the A/B test, the increase in the types of content clicked by the user means that the engine can present content with high serendipity to the user, that is, content that the user has never seen before, and the user has shown interest in and clicked. This is because this engine employs a technique in which productions that should be recommended based on metadata are recommended even if they are not popular, which makes it possible to present content that is likely to be of interest to the user, although it is outside the scope of the user’s viewing tendencies.
4.3 Increase in Clicks on the Entire Home Screen
In this A/B test, as shown in Fig. 5, the number of clicks in frames outside the recommendation frame, which was not subject to the test, increased significantly. This is because in the recommendation frame using this technology, a wide range of content other than popular content is displayed, and there are differences in the content displayed between the recommendation frame and frames outside the recommendation frame such as popularity rankings, thus we believe there was a change in the user’s actions, such as choosing a production based on their preferences from the recommendation frame and other frames. On the other hand, the recommendation frame by the conventional engine in the A/B test was biased toward popular content, therefore presumably, the overall number of clicks decreased because there was no difference in the content between the recommendation frame and other frames. Therefore, the introduction of this algorithm has the effect of encouraging more users to browse by changing the direction of what kind of content is recommended in each frame such as the recommendation frame and other frames.
- docomo TV Terminal: A service that allows users to watch docomo video services and other services on a single device by connecting it to a TV. The latest product name is “docomo TV Terminal 02.”
- A/B test: A test in which conditions other than the function are controlled to compare the effects of A and B for a specific function. Here, two algorithms, A and B, are used to provide users with different recommendation results.
-
In this article, we have described a case of presenting recommendations ...
Open
In this article, we have described a case of presenting recommendations with serendipity using a recommendation engine that utilizes metadata. As described with the filter bubble issue, the results of recommendation engines tend to converge on popular content. However, with this technology, we succeeded in encouraging new discoveries by appropriately displaying unexpected content to users through the use of metadata. This technology has already been used in our service, but we would like to continue to improve this technology to create better user experiences.
-
REFERENCES
Open
- [1] T. Ito et al.: “A Recommendation Engine Using Time Series Prediction Models of User Behavior,” NTT DOCOMO Technical Journal, Vol. 23, No. 4, pp. 28–35, Apr. 2022.
 https://www.docomo.ne.jp/english/binary/pdf/corporate/technology/rd/technical_journal/bn/vol23_4/vol23_4_005en.pdf (PDF format:1,489KB)
https://www.docomo.ne.jp/english/binary/pdf/corporate/technology/rd/technical_journal/bn/vol23_4/vol23_4_005en.pdf (PDF format:1,489KB) - [2] H. Guo, R. Tang, Y. Ye, Z. Li and X. He: “DeepFM: A Factorization-Machine based Neural Network for CTR Prediction,” arXiv preprint, arXiv:1703.04247, Mar. 2017.
- [3] S. Rendle: “Factorization Machines,” In 2010 IEEE International Conference on Data Mining, pp. 995–1000, Dec. 2010.
- [4] NTT DOCOMO: “docomo TV Terminal 02,” as of Dec. 2022 (in Japanese).
https://www.docomo.ne.jp/product/tt02/
- [1] T. Ito et al.: “A Recommendation Engine Using Time Series Prediction Models of User Behavior,” NTT DOCOMO Technical Journal, Vol. 23, No. 4, pp. 28–35, Apr. 2022.

