
Online Communication System for the Synlogue Experience
Voice Call System Low Latency Transmission Automatic Mute Control
Junya Takiue and Aogu Yamada
Service Innovation Department
Taku Nakamura
Core Network Development Department
Masahiro Takano
Communication Device Development Department
Abstract
“Synlogue” is a style of conversation that is considered to be empathetic and preferred by Japanese people, and in which overlapping utterances and reactions such as agreement responses and laughter are interweaved. In online communication, latency in voice transmission and microphone muting hinder synlogue. To address this issue, NTT DOCOMO has developed a voice call system that enables synlogue in online communication through low-latency, high-quality voice transmission using 5G and MEC as well as the multimodal microphone mute control by speech prediction.
01. Introduction
-
“Synlogue” is a way of speaking in which the speaker intentionally pauses ...
Open

“Synlogue” is a way of speaking in which the speaker intentionally pauses between phrases so that they can interact with the listener and complete the sentence together by overlapping each other’s speech processes. In the field of linguistics, synlogue has been compared with the Western-style “dialogue” and is regarded as a style of conversation preferred by Japanese people [1]–[3]. A comparison of dialogue and synlogue is shown in Figure 1. In synlogue, speakers frequently change, and reactions such as agreement responses and laughter overlap with utterances to create a sympathetic atmosphere. This enables participants to speak casually and with reassurance like when close friends meet and talk with each other, and enables conversations to proceed intuitively and at a good tempo.
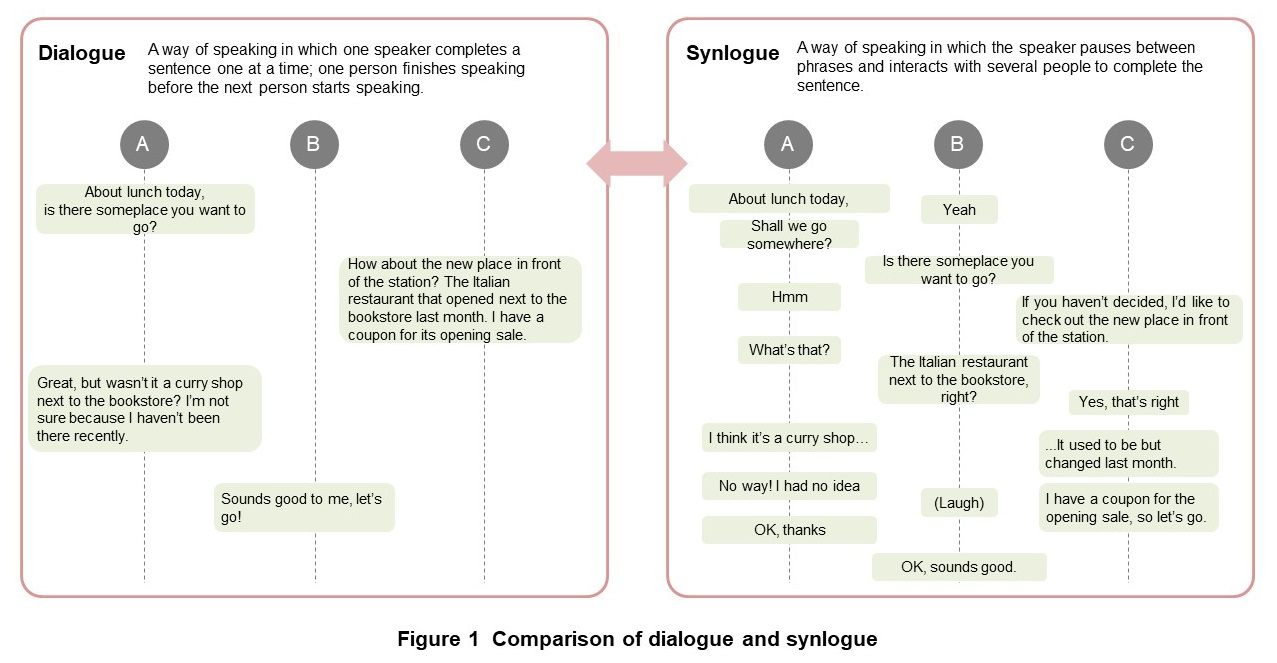
While synlogue is quite natural in face-to-face conversation, in online communication, latency in voice transmission and the operation of muting the microphone each time a person speaks can become a hindrance and make it difficult to achieve synlogue like a face-to-face meeting in which everyone is in harmony. In fact, conversations in remote work are often dialogue-like with a focus on efficiency to achieve a purpose. For this reason, it is said that remote work entails fewer conversations that are seemingly purposeless but that nevertheless provide reassurance, such as casual chats in the office. In casual talk and brainstorming, participants should speak freely and with reassurance in a sympathetic atmosphere to draw out their opinions and information, stimulate conversations, and generate new ideas, which also leads to productivity improvements.
Therefore, NTT DOCOMO has developed a voice call system (hereafter referred to as “the system”) that eliminates voice delay and troublesome mute operations that separate the speaker from the listener, enabling online synlogue. The system adopts two core technologies, such as low-latency, high-quality voice transmission utilizing 5G networks and Multi-access Edge Computing (MEC)*1 services, and automatic microphone mute control based on speech prediction.
This article describes an overview of the system, the two core technologies that enable online synlogue, evaluation results of the feasibility of synlogue, and applications of the system for facilitating communication.
- MEC: A mechanism for deploying servers and storage close to client terminals on a mobile communications network.
-
Figure 2 shows an overview of the system that enables the low-latency, ...
Open
Figure 2 shows an overview of the system that enables the low-latency, high-quality voice transmission and automatic microphone mute control necessary for online synlogue communications. The system consists of a Web Real-Time Communication (WebRTC)*2 server that provides voice call functions, an application server with User Interface (UI)*3-related functions for voice calls to create rooms for selecting a call partner from among online users, etc., and client terminals (smartphones). Voice calls are established by connecting client terminals via the 5G network. The WebRTC server provides voice call functions. The WebRTC server and application server which are implemented in docomo MEC, an MEC service provided by NTT DOCOMO, provides low latency speech transmission by the shorter physical distance between the servers and clients. In addition, automatic mute control using the terminal camera is performed in client terminals.
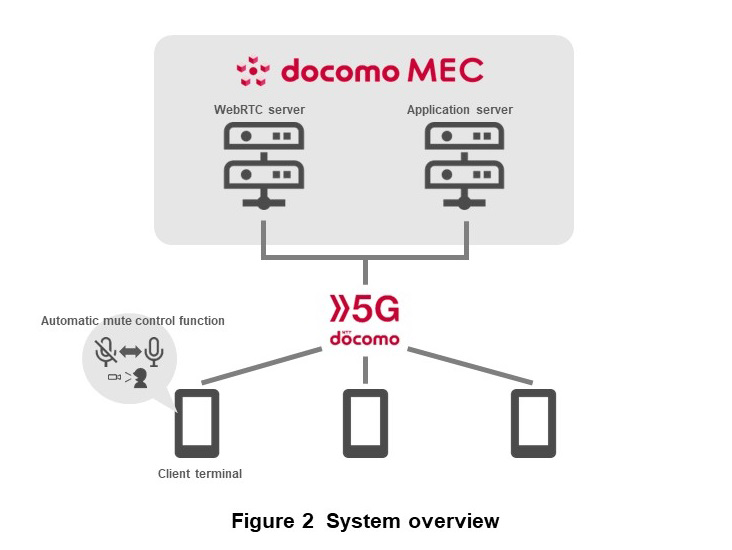
- WebRTC: A mechanism for real-time communication of audio, video, and other files between Web browsers and mobile applications, etc., via APIs, and an open standard whose source code is publicly available.
- UI: Generally, this refers to the interface (point of contact) between a user and a product or service.
-
3.1 Low-latency, High-quality Voice Transmission Using 5G and MEC
Open
In synlogue communications, it is essential that the listener shares reactions such as agreement responses and laughter with the speaker to convey sympathy, etc. When reactions are conveyed at unnatural intervals due to delay, it becomes difficult to speak and thus synlogue does not work. Therefore, low-latency voice transmission that allows reactions to be received in a natural and intended interval is essential. In addition, since utterances overlap frequently, clear sound quality that makes it easy to hear what the other person said while you are speaking is required.
1) Low-latency, High-quality Voice Transmission
In the system, the WebRTC server that enables real-time voice calls is implemented on docomo MEC, where the physical transmission distance between the server and clients is minimized. Low-latency, high-quality voice transmission has also been achieved by optimizing audio codec*4 parameters for the system. Specifically, the parameters related to delay defined in Session Description Protocol (SDP)*5 are set as low as possible while maintaining voice quality. The optimal values for both latency and voice quality were adopted after confirming the causal relationship between them. The system has no additional audio signal processing that requires buffering*6 Packetization cycle*7 for analyzing the input audio signal on the transmission path. That also contributes the low-latency transmission.
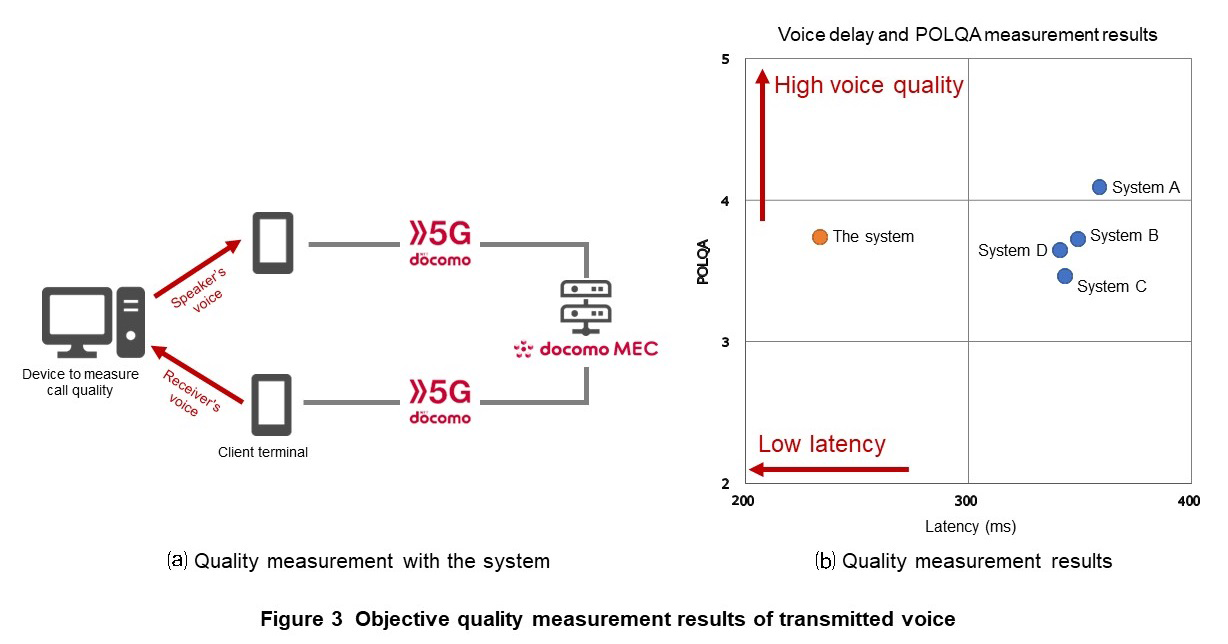
2) Results of Objective Speech Quality Assessment
The objective quality in Perceptual Objective Listening Quality Assessment (POLQA)*8 and latency of the transmitted speech in the system were measured by the system in Figure 3(a). For the purpose of comparison, online Web conferencing systems (applications) A to D were also evaluated via the 5G network and “sp-mode” connection environment. As in Fig. 3(b) , the system shows POLQA of 3.7 and latency of approximately 230 ms. The latency of the system is significantly shorter than any of the online web conferencing systems tested while speech quality equivalent to them is maintained.
3.2 Automatic Mute Control by Speech Prediction
In addition to low-latency and high-quality voice transmission, countermeasures against ambient noise are essential for realization of synlogue in online communication. Ambient noise, such as noise in daily life and echoes of voices, is a factor that hinders online communication. In particular, in synlogue communication in which there are active interactions among participants with reactions and utterances, the occurrence of utterances is irregular and frequent and thus conventional manual countermeasures such as people who are not speaking mute their microphones by themselves, as in the case of dialogue, do not work. As a result, the microphone remains enabled (unmuted), and the ambient noise of all participants is always mixed in. Therefore, it is more important to take countermeasures against ambient noise during synlogue than during dialogue.
As conventional countermeasures against ambient noise, there are speech detection technologies that activate the microphone only when speech is detected, and noise canceling technologies that cancels sounds other than speech. These technologies require some period of time to analyze and process the input audio signal. Typically, buffering by allowing some amount of delay is used, otherwise annoying loss of speech at the beginning occurs.
We developed an automatic microphone mute control technology that predicts the start of an utterance to enable the microphone by detecting the movement of the mouth with the camera of the user’s PC or smartphone and disables the microphone after the end of the utterance [4]. Unlike conventional technologies, this technology enables the microphone before the start of an utterance, which makes it possible to prevent the loss of speech at the beginning without buffering the input speech signal.
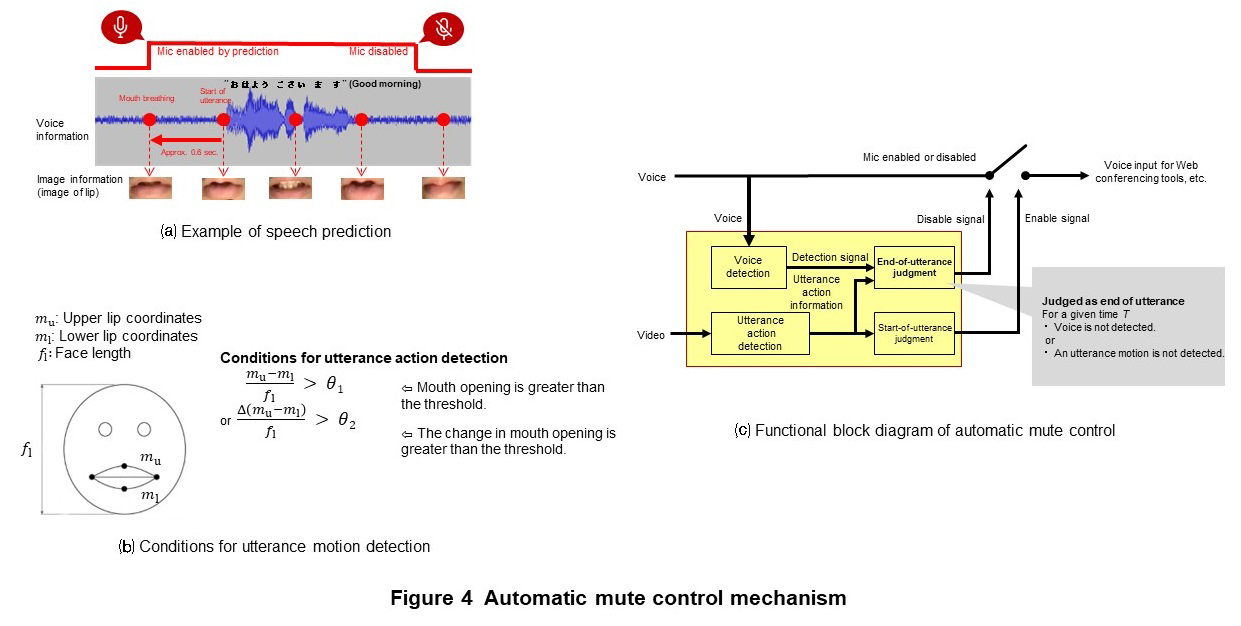
1) Mechanism of Automatic Mute Control
This technology focuses on the movement of the mouth just before a person speaks. For example, in Figure 4(a), the speaker opens his/her mouth approximately 0.6 seconds before the utterance to take a breath. By using image recognition to detect such pre-utterance motions, the microphone is activated before the utterance starts. In addition, the technology disables the microphone after the mouth stops moving to make an utterance and the voice is no longer detected. In this way, by activating the microphone only when the user is using his or her mouth to speak, ambient noise is avoided while the user is not speaking.
The details of utterance motion detection are explained in Fig. 4(b). First, the lip part is extracted by image recognition from the user’s face video (a face image that is continuous in the direction of the time axis). The maximum point (top of the upper lip) and the minimum point (bottom of the lower lip) of the vertical coordinates of the extracted lip part are respectively taken as feature points mu, ml. The ratio of the length of the line segment connecting feature point mu and feature point ml to the length of the face fl is calculated, and if the ratio exceeds the threshold θ1, or if the amount of variation (between video frames) per unit time of this ratio exceeds the threshold θ2, it is judged that an utterance motion has been performed. At this time, if the microphone is disabled, it is enabled, otherwise it continues to be enabled.
On the other hand, the microphone is disabled when at least either the utterance motion or the voice is not detected within the time T (2 seconds in this article) after the above-mentioned utterance motion is detected. Furthermore, appropriately setting the time T suppresses the unpleasant discontinuity of utterances caused by frequently muting and unmuting the microphone during short periods of utterances.
2) Automatic Mute Control Function Implementation
A functional block diagram of the automatic mute control is shown in Fig. 4(c). This function operates as a functional block that outputs a signal that controls whether to enable or disable transmission of the user’s voice to the Web conferencing tool by using the user’s voice and face video acquired from the microphone and camera of the user’s PC or smartphone as input. This control signal is generated based on the microphone enable/disable decision method described above and controls the voice input to the Web conference tool.
As shown in Fig. 4(c), this function performs processing without going through the voice path from the voice input from the microphone to the Web conferencing tool. Thus, in contrast to normal speech detection technology or audio processing technology such as noise cancellation, there is no waiting time for signal processing with voice input. Therefore, this function can be an effective countermeasure against ambient noise for the system, which requires low latency, because it does not increase latency of the call voice even when it is implemented.
3) Performance Evaluation Results
We evaluated the utterance motion detection technology used in this technology based on the rate at which utterances can be accurately detected from their beginning (the utterance loss-free detection rate). The database used is a video and audio database (total number of utterances: 3,107 utterances) that records synlogue scenes in online communication. The evaluation confirmed that 3,079 utterances, which accounted for 99.1% of the total, could be detected without loss. Sounds that could not be detected were short utterances without mouth movements, such as “um,” “he he,” and “ah,” and were only sounds that did not interfere with normal conversation.
In addition, we confirmed that the microphone was enabled at least 10 milliseconds before the following preparatory actions for utterances included in this database.
- Breath before an utterance
- Action to create a lip shape to say a consonant
- The action of opening the mouth to speak as soon as a word is found
- The action of opening the mouth to determine the timing when trying to speak while the other person is speaking
4) Acceptability Evaluation Results
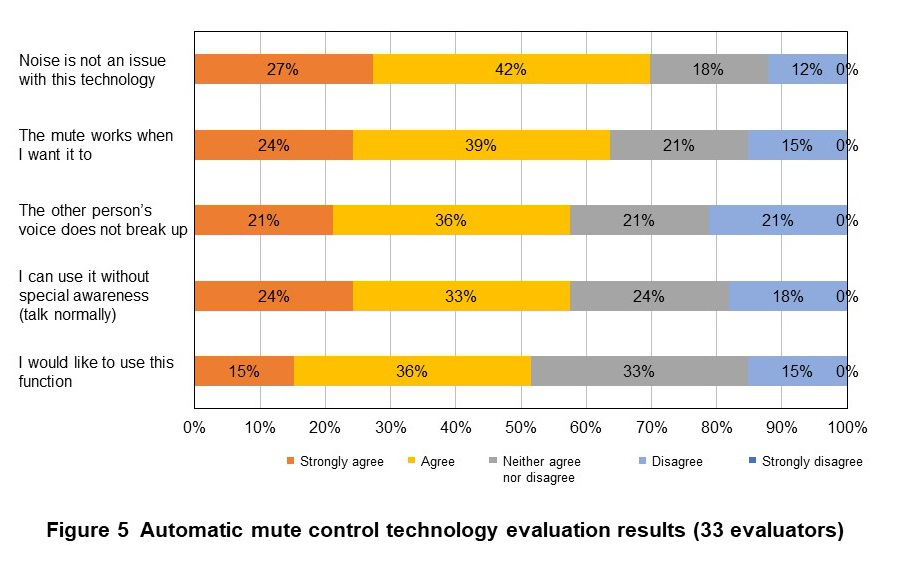
We conducted subjective evaluations on the effectiveness and user acceptability of this technology when it was used in an actual synlogue scene. Using the system, a group of three people talked for several minutes in a noisy environment with and without the technology. After that, the following five items were evaluated on a 5-point scale from “strongly agree” to “strongly disagree.” The evaluators were 33 men and women in their 20s to 50s.
- Noise is not an issue with this technology
- The mute works when I want it to
- The other person’s voice does not break up
- I can use it without special awareness (talk normally)
- I would like to use this function
Figure 5 shows the evaluation results. Approximately 70% of the evaluators evaluated that “noise is not an issue with this technology,” demonstrating its effectiveness against noise. In addition, most users rated the other four items related to performance, effectiveness, and acceptability as “agree” or higher, confirming the high effectiveness and acceptability of the utterance detection-based automatic mute control.
- Codec: A technology, device, or program, etc., that encodes or decodes data.
- SDP: One of the data standard formats for communicating parameters required to start streaming media data.
- Buffering: A mechanism for storing a certain amount of data in advance in case of latency in the network.
- Packetization cycle: The cycle in which audio is converted into packets for transmission. In general, increasing the packetization cycle improves transmission efficiency, but increases latency.
- POLQA: An international standard for objective speech quality assessment methods. It is a model of human perception and cognition and can be used to estimate subjective evaluation values that evaluators actually hear to evaluate speech.
-
We verified that the system enables synlogue. Since there has been ...
Open
We verified that the system enables synlogue. Since there has been no quantitative evaluation method for synlogue feasibility and synlogue is a conceptual style of conversation, we designed an evaluation method for feasibility.
4.1 Evaluation Method
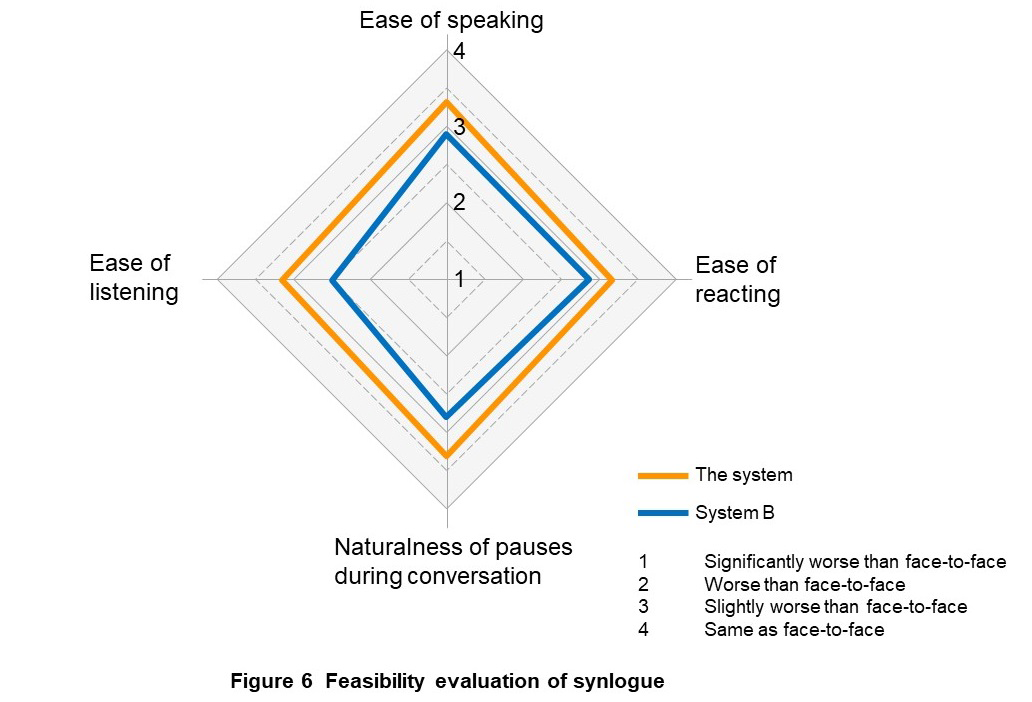
If low-latency, high-quality voice transmission and automatic mute control, which are the technical requirements for realizing online synlogue, are sufficiently achieved, it will create favorable conditions that will make it possible to interrupt the preceding speaker’s utterance with intended timing or react, or enable both sides to hear utterances even if they collide, and enable conversation to proceed without stress even in various noisy environments, etc. In developing the evaluation method, we adopted the approach of verbalizing the experiences of the speaker and the listener by realizing the above conditions as evaluation items and quantitatively evaluating them subjectively. Considering the evaluation load, the degree to which synlogue is realized (synlogue feasibility) was evaluated subjectively with the four factors, i.e., “ease of speaking,” “ease of reacting,” “naturalness of pauses during conversation,” and “ease of listening.”
In the evaluation, it is necessary to use a method that ensures that participants who usually do not know each other achieve synlogue. One method focusing on reproducibility is asking the participants to make conversation following a given script which tends to reproduce a scene of synlogue. The problem of this method is almost impossible for the participants to speak naturally as they follow a predetermined script. To ensure a higher degree of freedom than the pre-determined script method and maintain a certain degree of reproducibility, we used a method in which conversation could be conducted freely according to a given purpose. Then, by changing the purpose of the conversation, there would be a high probability of reaching repeated synlogue, even for participants who meet each other for the first time. Three methods were selected for the measurement: (a) brainstorming, (b) word wolf game and a review of it, and (c) NG word game and a review of it.
Three participants were involved in one conversation, and in the brainstorming session (a), we gave themes such as “the scariest thing that starts with the letter M.” In the word wolf game (b), two people and one person are given different themes, and three people discuss and guess who the one person in the minority is. At this time, the one person will talk so that they will not be discovered. If they are found out, they will lose. In the NG word game (c), each of the three players was given a different NG word, each player’s NG word was displayed to the other two players, but not to themselves. A player loses if they say their NG word. In the brainstorming (a), there was time to be silent to think, and in the games (b) and (c) there were times when participants were wary of remarks and remained silent, but in the process of review, transitioning from tension to relaxation, synlogue was almost certainly achieved.
There were 33 men and women in their 20s to 50s in total. Each group of three participants performed (a) to (c). After that, they were asked to evaluate the synlogue feasibility based on the four factors mentioned before. They performed comparative evaluations with reference to the face-to-face case, with the four levels of “4: Same as face-to-face,” “3: Slightly worse than face-to-face,” “2: Worse than face-to-face,” and “1: Significantly worse than face-to-face.” For this purpose, participants conducted face-to-face conversations (but sat back-to-back and could not see each other) before any conversation via the system. For comparison, we also evaluated System B (Fig. 3(b)) as a general online Web conferencing system. By hiding the display of the system, the participants did not know the system to be evaluated (the system or System B).
To eliminate the influence of the order of evaluation, the order of the system and system B in the evaluation was randomized for each evaluation group.
4.2 Evaluation Results
Figure 6 shows the average scores of the 33 participants. Based on the result that the average scores for all four factors were between the level of 4: Same as face-to-face and 3: Slightly worse than face-to-face, we concluded that the system realized synlogue close to face-to-face communication. In addition, the system outperformed Systems B, a general online Web conferencing system, in all four. Notably, we also confirmed that there was a significant difference based on the statistical test*9 (two-tailed t-test*10 with a significance level of 5%) in two factors, “naturalness of pauses during conversations” and “ease of listening.”
- Statistical test: A method of statistically testing whether or not a hypothesis about a collection of things is true, based on a subset of the data obtained.
- Two-tailed t-test: A statistical test in which the rejection regions are set on both sides of a t-distribution. Used to verify whether two things are the same.
-
Using the system, we developed a prototype application for facilitating ...
Open
Using the system, we developed a prototype application for facilitating communication that focuses on casual online talk in the workplace.
5.1 Aim of Application Development
We conducted a survey of a total of 28 NTT DOCOMO employees and a survey company regarding the role of communication demanded in the remote work environments during the COVID-19 pandemic. The results showed that there are high demands for casual talk to deepen connections between employees.
Furthermore, when we conducted an in-house questionnaire survey targeting 91 NTT DOCOMO employees, we found that approximately 80% of employees were positive about casual talk. Meanwhile, approximately 80% of employees felt that casual talk decreased in remote work environments, and approximately 90% of them thought it was a shame about such changes. The following trends were observed regarding the reasons for decreases in casual talk.
- There are no casual encounters online that could trigger office casual talk.
- Employees feel the purpose of online communication is clear, and that high efficiency and economic efficiency are emphasized, so they feel guilty about casual talk during work hours.
From these survey results, it was found that the importance of chat in communication is being rediscovered. In a workplace where there is little casual talk, there is a risk of accumulating stress unknowingly, although seemingly purposeless chatting should relieve loneliness and improve work efficiency in the workplace.
We believe that the synlogue realized by the system would be effective in creating the sympathetic atmosphere required for such chats in online communication. The aim of this application development is to bring back the chats that were once held face-to-face even online by providing a system that facilitates opportunities for incidental casual talk.
In addition to promoting the use of the application, we will change the way of thinking about online casual talk from something people think it is emotionally difficult to do or it is unnecessary, to something essential and supplemental to work efficiently and enjoyably and produce results. Supplement is not only provided by oneself but also by other people; it is something that we give to each other. We aim to improve the well-being*11 of our employees by fostering an organization that encourages chat and an organizational culture that values chat and by building better friendships among peers, seniors, and juniors.
5.2 Application Functions
Figure 7 shows a prototype application developed based on the above-mentioned purpose. The application has the following six main functions.

- (1) Profile setting
To provide common topics for talking, users can set their favorite images as icons and input their hobbies and current feelings. - (2) User search/profile viewing within the company
To allow employees of the same company to casually talk with each other, users can search other employees within the company and view their profiles. - (3) Notification function when a follower logs in
A follow/follower function for users was installed to let users know that the person they want to talk to online has logged in. When a user logs in to this application, a notification is sent to their followers. - (4) Room setting that allows up to three people to talk at the same time
To differentiate from current Web conferencing tools and to avoid the difficulty of talking with many people, we set the maximum number of people that all users can talk to proactively as three people. It is also possible to talk with less than three people. When a new user enters a room where two people are talking, by setting a temporary waiting time, it is possible to reconstruct the content of the conversation when the third person enters. - (5) Time limit setting in five-minute units
To allow the user to move on to the next task after talking for a certain period of time, and to explicitly indicate to users to be aware of time in the conversation at the start of talking, we set a time limit for talking. This time setting has purpose to lower the hurdle to talking, which arises from the concerns that talking will fall into too long. It is also possible to extend the time in five-minute units if necessary. - (6) Automatic mute control by predicting speech from mouth movement during talking
This function indicates whether a user is speaking by a UI display, and controls the mute function automatically to enable synlogue.
- Well-being: A conceptual definition of health and happiness, not only physically and mentally, but also in a social sense.
-
In this article, we described a system that realizes synlogue communication, ...
Open
In this article, we described a system that realizes synlogue communication, which is Japanese-style conversation in which speakers and listeners work together as they converse, even in online environments. The low-latency, high-quality voice transmission of the system can realize natural pauses for conveying reactions such as agreement responses and laughter, as well as easy-to-hear overlapping utterances. The system also eliminates the annoyance of muting the microphone by implementing technology that predicts speech based on mouth movement and performs automatic mute control. Since the microphone is automatically unmuted only when a user is speaking, the system enables conversations with a good tempo in which users can communicate their reactions to each other without worrying about ambient noise when they are not speaking.
Communication systems based on WebRTC such as the system are not only used in many Web applications, but are also being considered for standardization by the 3rd Generation Partnership Project (3GPP)*12 as systems to replace the IP Multimedia Subsystem (IMS)*13. This aims to enable rich communications that are highly compatible with Internet services and are different from Voice over LTE (VoLTE)*14 on mobile networks. Therefore, we aim to deploy this newly developed system on the DOCOMO network as a new communications platform.
Going forward, we aim to commercialize the service through verification using the prototype application for facilitating communication. We would also like to pursue cross-sectoral value using the system and accelerate efforts toward commercialization by providing a communications platform.
Finally, we would like to express our deepest gratitude to Professor Dominique Chen of Waseda University, who provided us with knowledge about synlogue as we proceeded with this project.
- 3GPP: A project established by standardization organizations of various countries to study and develop specifications for mobile communications.
- IMS: A system that enables multimedia communications using Internet technologies such as Session Initiation Protocol (SIP) / SDP.
- VoLTE: Voice functionality provided over LTE networks.
-
REFERENCES
Open
- [1] N. Mizutani: “Theory of Agreement Responses,” Japanese Language Studies, Vol. 7, No. 13, pp. 4–11, Dec. 1988 (in Japanese).
- [2] N. Mizutani: “Agreement Response and Response,” Chikumashobo, pp. 37–44, 1983 (in Japanese).
- [3] D. Chen: “Words to create the future – To bridge the confusion,” Shinchosha, pp. 155–171, Jan. 2020 (in Japanese).
- [4] A. Yamada, J. Takiue, N. Naka, T. Yoshimura and K. Ohta: “Multimodal Speech Detection Technology that Predicts Speech and Controls Microphone Mute,” Information Processing Society of Japan, DICOMO2022 Symposium, pp. 705–709, Jul. 2022 (in Japanese).

