
Technology to Grade English Speaking
Automatic Grading Deep Learning Language Processing
Atsuki Sawayama
Service Innovation Department
Housei Matsuoka
Mirai Translate, Inc.
Abstract
In recent years, English education in Japan has required a balanced acquisition of the four skills of listening, reading, writing, and speaking. Among these skills, particular emphasis is placed on the acquisition of the active skills, writing and speaking. Since it is difficult for an individual to learn these skills, NTT DOCOMO has developed a speaking grading technology that enables an individual to practice speaking. This technology enables speaking practice and automatic grading based on interview tests. This article provides an overview of the technology and its application.
01. Introduction
-
In recent years, English language learning in Japanese school education has come ...
Open

In recent years, English language learning in Japanese school education has come to require a well-balanced acquisition of the four skills of listening, reading, writing, and speaking. Among these skills, emphasis is placed on helping students acquire active skills, writing and speaking. As a result, students are encouraged to acquire qualifications that can determine their active skills, and significant changes are taking place for students, such as certifications such as The EIKEN Test in Practical English Proficiency (EIKEN) being recognized as class credits and partial exemptions from entrance examinations based on certifications acquired.
In this context, there is an increasing burden on teachers to teach students so that their active skills improve, which has become a major issue. For example, interview test practice for external examinations and entrance examinations often requires teachers to teach after school and other out-of-class time. On top of that, teachers’ time is limited, which means that students might not receive adequate instruction.
Against this background, we believe that Artificial Intelligence (AI) technology to support student learning and automatic grading will be effective in improving students’ active skills and reducing teachers’ workload.
As a first step to solve these issues, NTT DOCOMO has developed an AI-based writing grading and correction function [1] and has provided this function as an AI writing function in “English 4skills” [2], an English language learning service for junior high and high school students. This service has supported students learn the skill of writing and helped reduce teacher grading and instructional workload.
Meanwhile, from the perspective of school education, we believe that speaking skills are also an urgent issue that needs to be addressed. To support the acquisition of speaking skills, functions that can evaluate what students say without human intervention is needed, similar to the AI writing functions currently provided. However, unlike the AI writing function, it must be able to grade the student’s spoken English explanations of situations and opinions as well as the student’s English translations.
Therefore, NTT DOCOMO has developed English speaking grading technology that enables students to practice and improve the skill of speaking. This technology consists of grading technology for descriptions of images depicted on question cards and grading technology for one-answer questions. Incorporating these into the speaking grading system, which simulates a face-to-face interview test, it is possible to practice and improve their English speaking skills. This article describes the English speaking grading technology we developed.
-
The speaking grading system using this technology is designed to ...
Open
The speaking grading system using this technology is designed to enable practice that simulates a face-to-face interview test in the form of a Web application. Students can practice the following sequence of steps using a smartphone or tablet: “greeting the examiner at the beginning of a test,” “receiving a question card,” “describing the image depicted on the question card,” “one-answer questions,” “returning the question card,” and “thanking the examiner at the end of a test” (Figure 1).
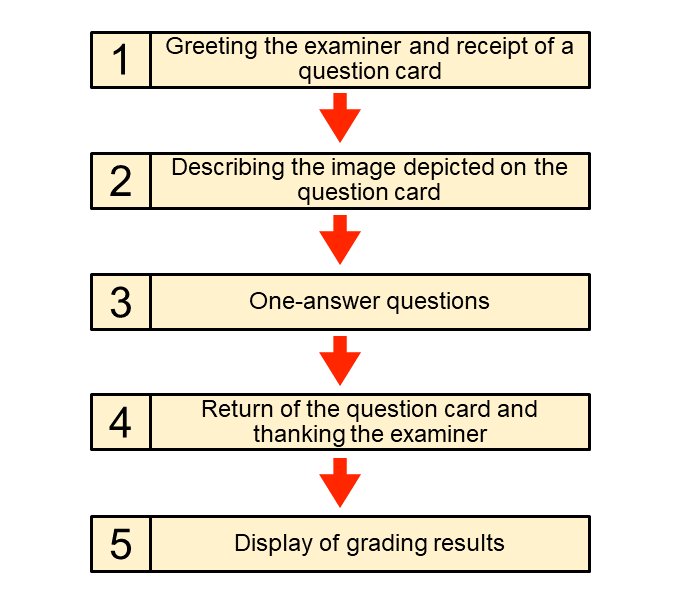
Figure 1 Interview test practice flow
This system recognizes speech made by students into a microphone on a smartphone or tablet and processes the grading. After thanking the examiner at the end of a test, the results of the series of interview grades are presented to the students. We describe the two types of questions implemented in the grading system (describing the image depicted on card questions and one-answer questions).
2.1 Describing the Image Depicted on a Question Card
In these questions, students are asked about the content related to the passages and images on a question card, and students are asked to explain the situation and give reasons for why they described things as they did. An example of the images included on question cards is shown in Figure 2. The examiner asks questions to get the student to explain the actions of each of the characters depicted in the image on the question card to describe the situation.

Figure 2 Example of the images included in question cards
2.2 One-answer Questions
In these questions, questions on a topic are asked without using a question card or other reference materials. Students respond with their own positions and opinions (Figure 3). The examiner asks additional questions about the student reasons based on the student’s answers.

Figure 3 Image of a one-answer question
-
We describe the grading technology for the two forms - describing the image ...
Open
We describe the grading technology for the two forms - describing the image depicted on a question card, and one-answer questions.
3.1 Grading for Describing the Image Depicted on a Question Card
As shown in Figure 4, grading for describing the image depicted on a question card consists of three steps: (1) estimation of the character/situation from the student’s answer, (2) selection of a model answer from the set of model answers for character/situation, and (3) student’s grading and correction using English composition correction technology.
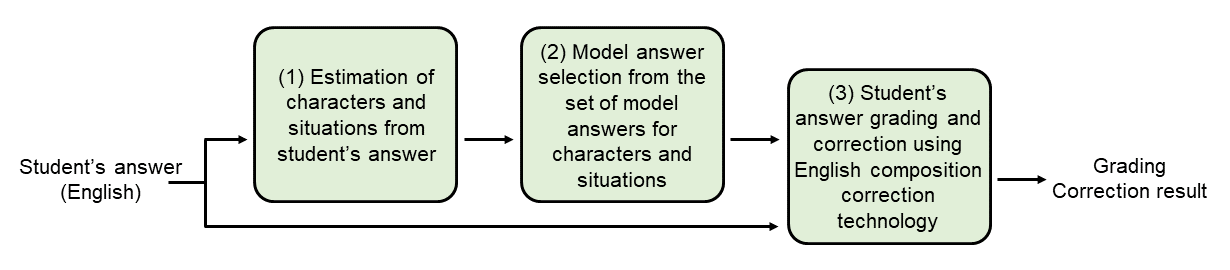
Figure 4 Grading flow for describing the image depicted on a question card
At first, in step (1), the student’s answer entered is compared to the model answers prepared in advance, which describe the situation of each of the characters depicted in the image on the question card and estimates to which character or situation in the image the student’s answer correspond.
In the next step (2), the model answer that is most similar to the student’s answer is selected from the set of model answers corresponding to the estimated character/situation, and a Japanese sentence of the model answer paired with the selected model answer is output.
Then, through step (3), the Japanese sentence corresponding to the selected model answer is translated into English using the English writing correction technology [1] and compared with the student’s answer to grade and correct the student’s answer in terms of meaning.
These three steps make it possible to estimate which character or situation in the image the student’s answer is describing, while also providing semantic correction of the student’s answer.
1) Estimation of Characters and Situations from Student’s Answers
To estimate the character/situation in the image on a question card that is similar to the student’s answer, a set of model answers is prepared in advance, consisting of multiple pairs of English and Japanese sentences that describe the situation of each character depicted in the image. This set of model answers is structured, with the first level containing information about which character or situation in the image is represented, and the second level containing the various model answers that represent each character or situation (Figure 5 left).
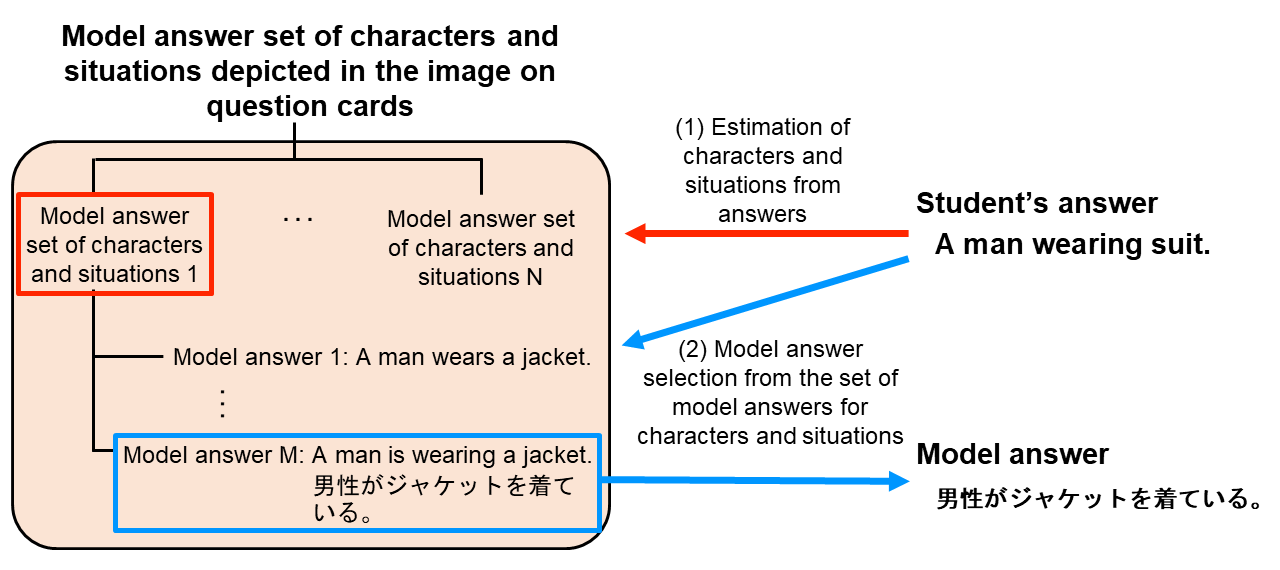
Figure 5 Structure of the model answer set and the flow of estimation steps of characters and situations from answers
We describe an example of the operation of the estimation step of the character/situation model answer set. The student’s answer - “A man wearing a suit.” is input and split into word units. Next, the words in the answer sentence are converted to word vectors using Word2Vec*1 [3]. The word vectors are then added together to create a sentence vector [4]. Similarly, each model answer sentence in the model answer set of the character/situation depicted in the image on the question card is converted in advance into a sentence vector, the cosine similarity*2 between the sentence vector of the student’s answer and the sentence vector of each sentence in the respective model answer set is calculated, and the most similar model answer set is selected from the average similarity between the student’s answer and the model answer set.
2) Model Answer Selection from the Set of Model Answers for Characters and Situations
The sentence vector of the student’s answer with the sentence vectors of the model answers in the set of model answers selected in (1) are compared, and the model answer most similar to the student’s answer is selected. In Fig. 5, “A man is wearing a jacket,” which is most similar to “A man wearing a suit,” is selected. At this time, for the grading and correction of the student’s answer utilizing the English composition correction technology in the next section, the Japanese sentence of the selected model answer, “Dansei ga jaketto wo kiteiru.” is used.
3) Answer Grading and Correction using English Composition Correction Technology
Next, the English composition correction technology is used to grade and correct the students’ answer based on the Japanese sentence corresponding to the model answer selected in (2). This technology can grade English sentences based on a Japanese-English translation model, and in the process of generating English sentences from model Japanese sentences, it can generate sentences that are similar to the wording of the student’s answers. This makes it possible to grade and correct student’s answers that are similar in meaning to the model answers but worded differently, which is difficult to do simply by comparing student’s answers to the model answers written in English.
As an example of grading, the Japanese model answer is “Dansei ga jaketto wo kiteiru.” and the student’s English answer is “A man wearing suit.” First, the Japanese model answer is word segmented and input into the encoder in the encoder-decoder model*3 based on the Japanese-English translation model. Then an English translation of the model sentence begins and the predicted words are estimated. From the predicted words and the words answered by the student, a grade for each word and the results of the correction are output. Once all word grades and correction results are output, the grade for the sentence is calculated. In this way, the grading and correction results of the student’s answers are displayed (in Figure 6, only the correction result is displayed).

Figure 6 Example of grading for describing the image depicted on a question card (description for the man in the lower left corner of Fig. 2)
3.2 Grading One-answer Questions
In the one-answer question grading technology, as answers are entered into the system, the grading system evaluates the consistency of the question-student’s answer pairs (i.e., whether student’s answers answer the question) and outputs a score. This makes it possible to grade the degree to which the answers correctly answer the questions presented.
To grade the student’s answers to questions, a large number of pairs of questions and answers that correctly answered the questions (positive examples) and pairs of questions and answers that did not answer the questions (negative examples) were prepared in advance. In this process, instead of using only manually created positive/negative example pairs for training, questions and answers in the positive example pairs were randomly recombined to create pseudo-negative example data, which was added to the training data. The word-segmented question-answer pairs were then combined with a split token “<SEP>” as the input series and trained into a structured attention model [5], a type of deep learning. This enables the meaning of the question and answer statements to be understood and graded to determine whether the answers answer the questions.
Figure 7 shows the grading behavior when the question “Do you like dogs?” and the answer “Yes, I do.” are entered into the grading model. First, the question/answer pairs created as described above are entered into the grading model. The hidden layer*4 of each input is then combined and input into the attention layer*5 to calculate which parts of the question and answer statements are relevant. The consistency grades for the question-answer pairs are then output with values ranging from 0 to 1. The output values are normalized to a 10-point scale. Finally, if the student’s answer to the question is clearly too short, the answer is considered inadequate to the question and the difference in sentence length between the question statement and the student’s answer is given as a brevity penalty, which is the final score for the student’s answer.

Figure 7 Summary of grading model for one-answer questions
An example of grading student’s answers is shown in Figure 8. The system outputs a high score for sentences that answer the question, while outputting a low score for sentences that do not answer the question, even if they contain words used in the question.
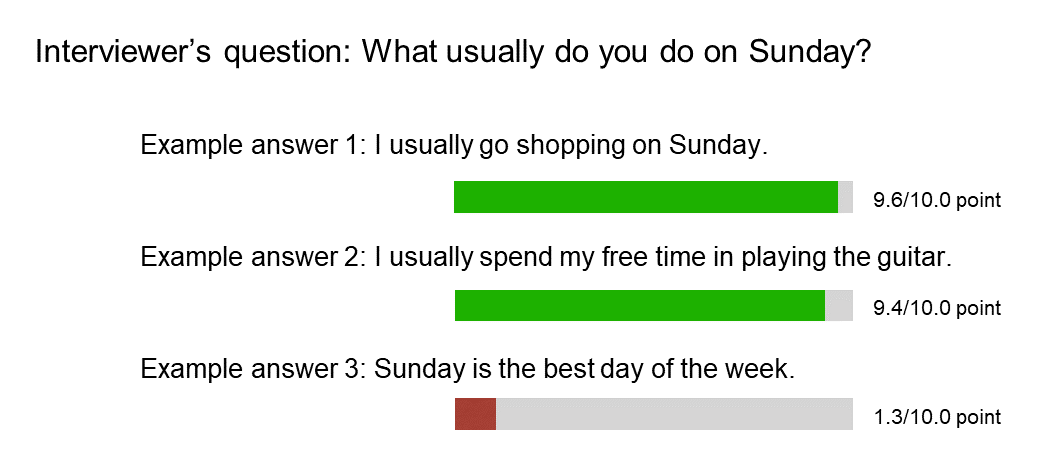
Figure 8 Example of grading a one-answer question
- Word2Vec: A technique that analyzes text data and represents the meaning of each word in vector form.
- Cosine similarity: A numerical measure of how close the directions of two vectors are.
- Encoder/decoder model: A recurrent neural network structure that generates time series data from some time series data input. A type of deep learning.
- Hidden layer: A layer that calculates internal values based on learned weights, etc., and propagates them to the output layer when certain inputs are given.
- Attention layer: An output layer that calculates the part of the input data to focus on (whether to give it weight) when producing a certain output. In this grading, we use a method called self-attention, which can capture the relative relationship between words in the input text.
-
This article described an English speaking grading technology ...
Open
This article described an English speaking grading technology that enables practice of speaking skills. By incorporating the grading technology developed for interview test practice into learning applications, it is now possible to practice speaking with free answers, simulating realistic interview test situations, which was previously difficult for individual students to do by themselves. This technology is implemented as “AI Speaking” in “English 4skills,” an English 4 skills learning service provided by NTT DOCOMO and is actually beginning to be used in educational settings. In the future, we would like to develop technology capable of grading more advanced free conversation.
-
REFERENCES
Open
- [1] H. Matsuoka et al.: “Technology to Grade and Correct Compositions in English,” NTT DOCOMO Technical Journal, Vol. 21, No.4, pp. 61–66, Apr. 2020.
 https://www.docomo.ne.jp/english/binary/pdf/corporate/technology/rd/technical_journal/bn/vol21_4/vol21_4_009en.pdf (PDF format:1,276KB)
https://www.docomo.ne.jp/english/binary/pdf/corporate/technology/rd/technical_journal/bn/vol21_4/vol21_4_009en.pdf (PDF format:1,276KB) - [2] NTT DOCOMO: “English 4skills,” Apr. 2018 (in Japanese).
 https://e4skills.com/
https://e4skills.com/ - [3] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean: “Distributed representations of words and phrases and their compositionality,” Advances in neural information processing systems 26, Oct. 2013.
- [4] D. Shen, G. Wang, W. Wang, M. R. Min, Q. Su, Y. Zhang, C. Li, R. Henao, and L. Carin: “Baseline needs more love: On simple word-embedding-based models and associated pooling mechanisms,” arXiv preprint arXiv: 1805.09843, May 2018.
- [5] Z. Lin, M. Feng, C. Nogueira dos Santos, M. Yu, B. Xiang, B. Zhou, and Y. Bengio: “A structured self-attentive sentence embedding,” arXiv preprint arXiv: 1703.03130, Mar. 2017.
- [1] H. Matsuoka et al.: “Technology to Grade and Correct Compositions in English,” NTT DOCOMO Technical Journal, Vol. 21, No.4, pp. 61–66, Apr. 2020.

