

AI・サービス特集 —文書・画像処理技術—
音声DX基盤が拓く音声データの活用
音声データ活用 音声認識 感情認識
千葉 麻莉子(ちば まりこ)
斉藤 優樹(さいとう ゆうき)
加藤 拓(かとう たく)
山田 仰(やまだ あおぐ)
山縣 将貴(やまがた まさき)
サービスイノベーション部
あらまし
大規模言語モデル(LLM)の隆盛に伴い,ビジネスでのAIの活用は加速している.データドリブン経営の推進のためにも,ビジネスシーンにおけるさまざまなデータの一層の活用が望まれているが,人と人とのコミュニケーションを記録した音声データの活用は未だ限定的である.ドコモでは,対面やオンラインでの会議など,音声コミュニケーションがかかわるあらゆる場面での業務効率化や生産性向上への貢献をめざし,音声データを多角的に分析できる「音声DX基盤」の開発に取り組んでいる.本稿では,「音声DX基盤」に搭載している技術の概要と,その活用例について解説する.
01. まえがき
-
音声を介するコミュニケーションは,人間にとって最も基本的な情報伝達方法の ...
開く

音声を介するコミュニケーションは,人間にとって最も基本的な情報伝達方法の1つであり,メールやテキストチャットが普及した現代においても,多くのコミュニケーションは音声を介して行われている.音声によるコミュニケーションは即応的に情報交換を行えるほか,声のトーンや対話のリズムといった非言語情報を通して感情やニュアンスを伝えることで,相手との共感や理解をさらに深めることができる.人と人とのコミュニケーションでは,このような言外の情報も大きな役割を担っており,ビジネスにおけるデジタルトランスフォーメーション(DX:Digital Transformation)*1を推進するためには,会話の文字起しでは表れない多様な情報を含む音声データの蓄積と的確な分析が重要となってくる.
音声から発話内容の文字起しを行う音声認識技術は,スマートフォンに搭載された音声エージェントやWeb会議システムの文字起し機能などを通して広く普及している一方,音声データから,非言語情報を含めたさまざまな情報を取り出す技術は,未だ活用方法の検討が進められている段階にある.
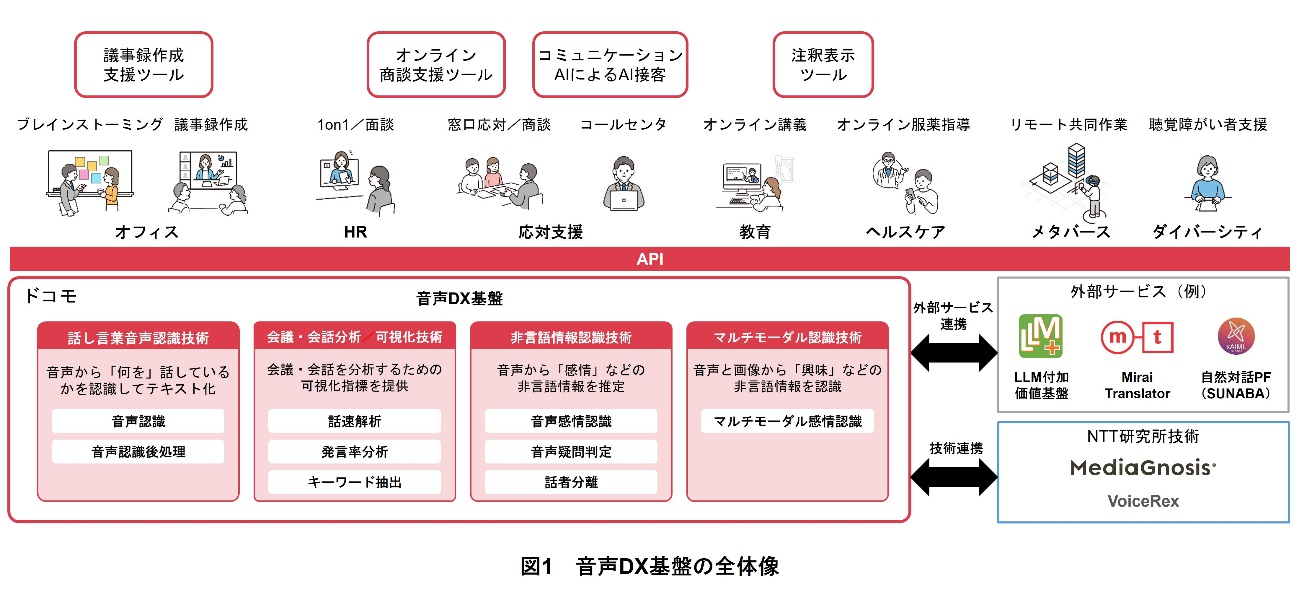
ドコモでは,ビジネスでの音声データ活用促進のために,音声データからテキストや感情,話し方の特徴などを多角的に分析できる「音声DX基盤」の開発に取り組んでいる(図1).音声DX基盤は,音声データから発話内容テキストや感情などを分析用に抽出する音声分析技術の実用性検証の効率化を目的として,音声分析AIアセット*2を集約した基盤であり,2つの大きな特徴をもつ.
1つ目は,音声分析AIアセットの集約によるインタフェースの共通化である.音声分析に関するさまざまなAIアセットを1つの基盤に集約し,共通のインタフェースを介してそれらを利用できるようにすることで,技術検証やサービス開発における新しい音声分析技術の導入コストを下げることができる.
2つ目は,幅広い場面での音声データ活用を見据えた,豊富な音声分析AIアセットのラインナップである.音声DX基盤には,音声認識,音声感情認識,マルチモーダル*3感情認識(音声感情認識と表情感情認識の組合せ),話者分離などのさまざまな音声分析技術に加え,音声認識結果の可読性向上のための後処理や音声認識結果からのキーワード抽出,会議単位での発言率分析などの音声分析結果を用いた付随的な分析機能を搭載している.これらは,NTT研究所の技術をベースとしつつ,実用性を向上させるためにドコモ独自で実装した機能となっている.
本稿では,「音声DX基盤」に搭載されている技術の概要と,その活用例について解説する.
- DX:IT技術を活用してサービスやビジネスモデルを変革させ,事業を促進するとともに人々の生活をあらゆる面で良い方向に変化させること.
- アセット:技術資産のこと.
- マルチモーダル:複数の種類の情報のこと.ここでは,音声データや画像データなどの複数のメディアデータを入力情報として扱うことを指す.
02. 音声DX基盤の概要
-
音声DX基盤の構成の概要を図2に示す.音声DX基盤は,音声ストリームと ...
開く
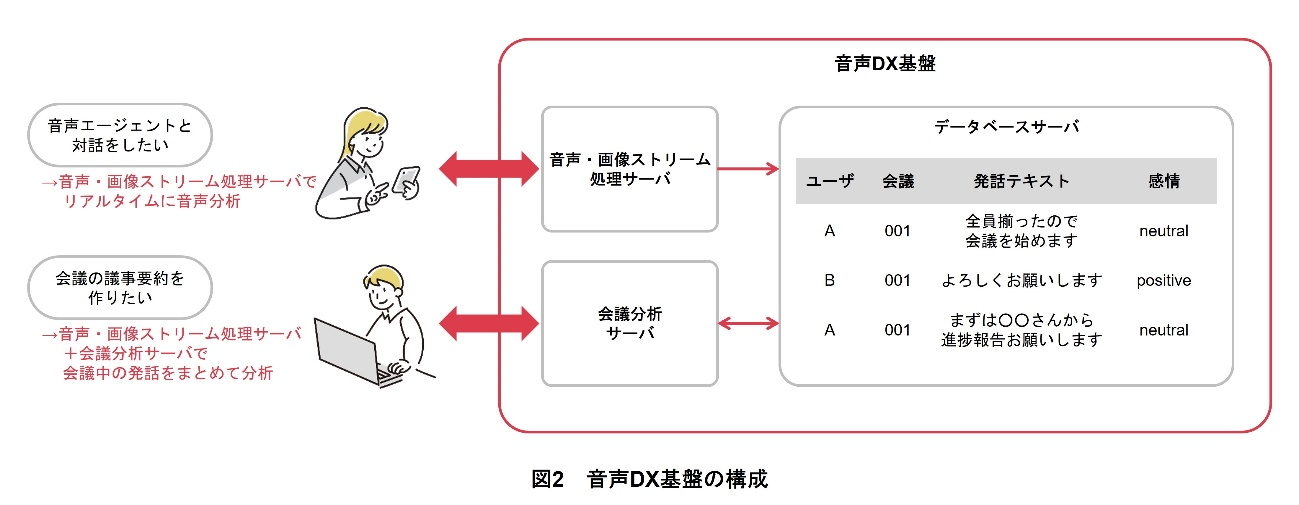
音声DX基盤の構成の概要を図2に示す.音声DX基盤は,音声ストリームと画像ストリームをリアルタイムに分析するための音声・画像ストリーム処理サーバと,複数の発話をまとめて分析するための会議分析サーバと,データベースサーバから構成される.
音声・画像ストリーム処理サーバでは,音声データを音声区間検出によって発話単位に分割し,発話内容テキストなどの言語情報の抽出処理と感情などの非言語情報の抽出処理を並列で実行する.これにより,ユーザは1回の通信セッション*4で複数の音声分析AIによる分析(抽出処理)結果を取得することができる.音声・画像ストリーム処理サーバは,my daiz*5[1]やドコモAIエージェントAPI®(Application Programming Interface)*6[2]でも利用されている音声ストリーム処理技術を用いて開発されており,音声対話エージェントのようなリアルタイム性が求められるユースケースでの利用も可能である.
音声・画像ストリーム処理サーバで分析したユーザごと・発話区間ごとの音声分析結果は,データベースサーバへと格納される.会議分析サーバでは,データベース上の音声分析結果を会議単位でまとめて分析する.複数話者・複数発話をまとめて分析することで,会議参加者内で誰がたくさん発言をしていたか,会議中にどんなキーワードが話されていたかといった, 会議全体の様子にかかわる情報を抽出することができる.
音声・画像ストリーム処理サーバと会議分析サーバを組み合わせることで,ユーザごとの音声分析結果をリアルタイムに得ることも,会議全体の発話を考慮した分析を行うことも可能となる.また,音声DX基盤は,搭載しているさまざまな音声分析技術や音声分析に付随する機能を選択できるため,さまざまなユースケースに合わせた活用ができる.
- 通信セッション:クライアントとサーバ間でやり取りされる一連の通信のこと.
- my daiz:ユーザに合わせた幅広い情報を提供する,スマートフォンやタブレット上で動作する音声対話エージェント.my daizおよびmy daizロゴは㈱NTTドコモの登録商標.
- ドコモAIエージェントAPI®:NTTグループのAI「corevo®」の一部である,音声ユーザインタフェースをパッケージ化した対話型AIのASP(Application Service Provider)サービス.GUIによる簡単な対話の作成や,マークアップ言語であるAIML(Artificial Intelligence Markup Language)を利用することで複雑な対話シナリオが実現できる.また,QAリストから対話シナリオを自動生成するFAQ用チャットボットとして,よくある問合せの応対に活用できる.corevoは,日本電信電話株式会社の登録商標.ドコモAIエージェントAPIは㈱NTTドコモの登録商標.
03. 音声分析AIアセット
-
音声DX基盤の機能は,NTT研究所で研究開発された技術とドコモで独自開発した ...
開く
音声DX基盤の機能は,NTT研究所で研究開発された技術とドコモで独自開発した技術を組み合わせて実現している.音声分析AIアセットとして,音声・画像ストリーム処理サーバ向けには,音声認識,音声感情認識,表情感情認識,話者分離や,ユーザの話す速度を解析する話速解析,あらかじめ登録した単語の発話を検知するキーワード抽出などの機能が利用可能である.会議分析サーバ向けには,ワードバブル分析や,会議におけるユーザごとの発言時間の比率を計算する発言率分析などの機能が利用可能である.また,大規模言語モデル(LLM:Large Language Model)*7を利用した要約処理など,外部API連携*8による高度なテキスト処理も可能である.本稿では,「音声認識」「音声感情認識」「表情感情認識」「話者分離」「ワードバブル分析」の5つの技術について解説する.
音声をテキスト化する「音声認識」技術では,NTT研究所における音声情報処理の研究開発の中で生み出された技術[3]~[7]を用いて,ドコモで収集した音声データを本AIに学習させることで,実利用環境における,より高精度なテキスト化を実現している.また,ドコモで開発した可読性向上のための技術を組み合わせることで,例えば表1に示すように,ユーザにとってより読みやすいテキストを提供可能である.
「音声感情認識」技術,「表情感情認識」技術では,NTT研究所の開発した「次世代メディア処理AI『MediaGnosis®』」[5][6][8]を用いて,音声および画像から感情などの非言語情報の推定を実現している.ドコモで収集した実利用環境に近い音声データ・画像データを本AIが学習することで,音声・画像に対する各推定モデルを構築している.音声のみ,画像のみだけでなく,両者の分析結果を組み合わせたマルチモーダル処理による分析も可能である.
「話者分離」技術では,「MediaGnosis」により出力可能な話者特徴量*9を利用することで,複数の人が会話している状況において,音声の話者ごとの分離を実現している.本技術を用いることで,リアルタイムに話者数を自動で推定しながら,入力音声を分類することが可能である.さらに,1つのマイクに対し複数人が発話している状況であっても,話者ごとの分析・解析が可能となる.
「ワードバブル分析」技術は,会議における発言内容をビジュアライズする技術である.会議参加者の発言内容を分析し,単語の発話頻度や,単語間の類似度,どの単語と同じ文で発話されやすいかを表す共起度*10などを基に,各単語を図3のように2次元平面上にマッピングする.頻度の高さを円の大きさで,各単語間の類似度を単語間の距離で表現している.クラスタ*11分析による各単語のカテゴリ分類も実施しており,同じカテゴリの単語を同じ色で描画する.また,会議中に発言された単語と類似する単語・関連する単語を表示可能であり,本機能を用いることで,会議内容の振返りだけでなく,例えばブレインストーミングにおけるアイデア創出の補助などにおいても活用可能であると考えられる.

- 大規模言語モデル:大量のテキストデータを用いて構築された自然言語処理のモデルのこと.従来の言語モデルよりも高度な自然言語処理タスクに利用可能である.
- 外部API連携:あらかじめ定義したインタフェースを介し,別システムや別サービスの異なるプログラムやソフトウェアを連携すること.
- 話者特徴量:音声波形から抽出される,話者固有の情報のこと.話者識別や話者照合において用いられる.
- 共起度:同じ文中に,ある単語とある単語が同時に出現する頻度.
- クラスタ:似た性質や特徴をもつデータがグループ化された集合.
04. 音声DX基盤の活用例
-
4.1 議事録作成支援ツール
開く
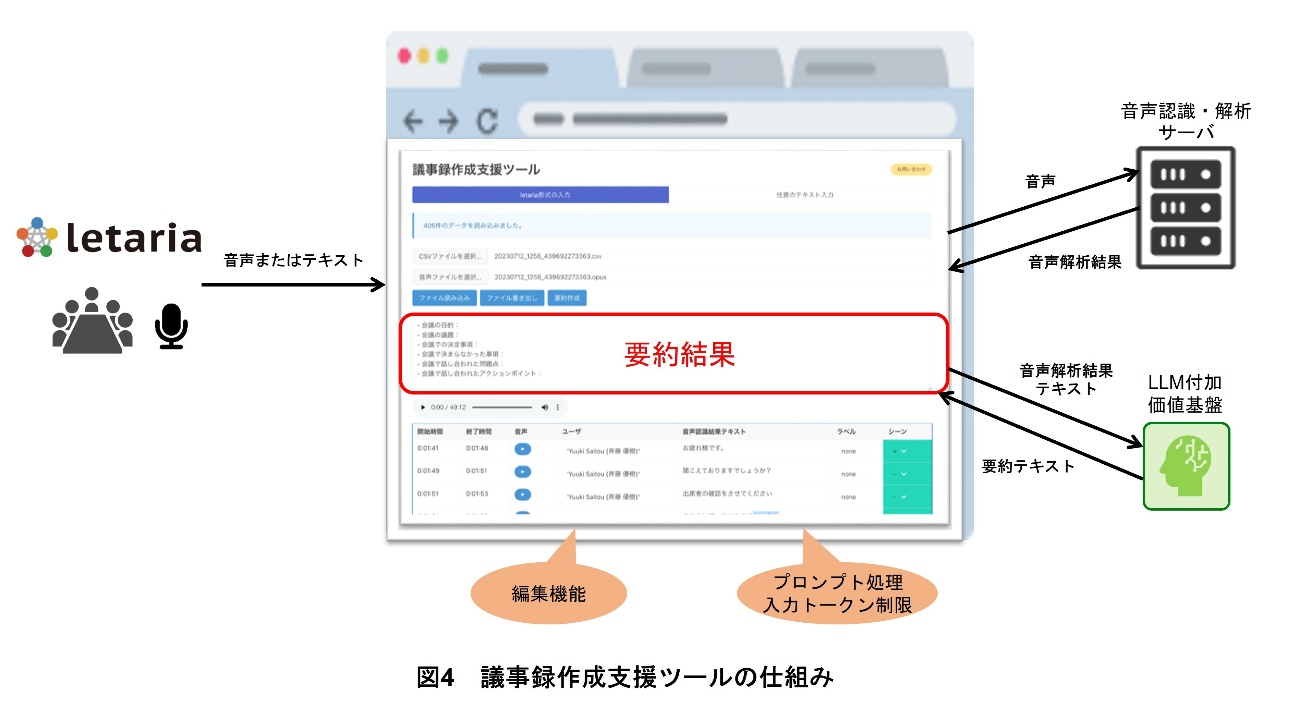
議事録の作成にかかる時間と手間は依然として大きな負担となっており,これを解決するために,ドコモは新たに会議などの音声やテキストの内容を要約する議事録作成支援ツールを開発した(図4).本ツールでは,会議などの音声を音声認識・解析サーバで解析することでテキスト化し,テキスト内容をLLM付加価値基盤で要約する.これにより議事録作成の効率向上を実現し,作成稼働の大幅な削減を可能にする.
本ツールは以下の特徴がある.
(1)ユーザ向けWebアプリケーション
議事録作成支援ツールは,ドコモ社内に構築したWebアプリケーションとして公開され,社内システムに接続が許可されたすべての社員が容易にアクセスできるようになっている.これにより,ユーザは議事録作成・確認をスムーズに行える.
(2)多様な入力形式
本ツールはいくつかの入力形式をサポートしている.会議や打合せで作成した議事メモなどが含まれる任意のテキストを利用できる.また,会議ツールletaria[9]を利用した音声ファイルや音声認識結果のテキストファイルを利用できる.これにより,ユーザは任意の方法で情報を入力できる.
(3)LLM付加価値基盤[10]を活用
LLMの強力な能力を活用し,議事録の要約をサポートしている.LLMの利用に投入が必要なプロンプト*12を意識することなく,ユーザはUI上で要約を実行させることで,システム内に組み込まれたプロンプトを活用し,要約を受け取ることができる.これにより,新たなプロンプトの作成が不要となり,利用を容易にした.
(4)効率的な要約処理
本ツールはLLMの入力トークン*13制限に対応し,入力テキストを一定のテキスト長に複数分けて要約し,その結果を最終的に1つにまとめて要約する仕組みを具備している.これにより,LLMのリソースを効率的に活用し,高品質な要約を生成する.
4.2 オンライン商談支援ツール
音声DX基盤の活用例の1つとして,オンライン商談支援がある.コロナ禍をきっかけとしたテレワークの普及に伴い,多くの企業でオンライン商談の導入が急増した.しかしながら従来の対面での商談と比べて,オンライン商談は「相手の反応が捉え難い」という課題がある.具体的には,お客さまがカメラをオンにしていたとしても画面に表示される顔が小さいことや,営業のためのプレゼンテーション中は営業担当者が画面に投影した資料の説明に手一杯になることが要因で,お客さまの反応の把握が困難になってしまうなどがある.
そこでドコモでは,音声DX基盤の音声認識や表情感情認識を活用し,リアルタイムでお客さまの「興味の反応」を検知し可視化することによる,オンライン商談支援をめざしている.音声DX基盤を使ったオンライン商談支援ツールによるお客さま分析の例を図5に示す.この例では,住宅メーカの営業担当者が自社の商品について,お客さま(妻と夫)にオンライン商談で説明しているシーンを想定している.このオンライン商談支援ツールでは,以下の2つの機能を有しており,営業担当者のサポートが可能である.
- お客さまのPCから取得したカメラ画像を音声DX基盤の表情感情認識によって分析し,その結果(ポジティブ/ネガティブの確率)を時系列のグラフとして表示
- 営業担当者のPCから取得したマイク音声を音声DX基盤によって分析し,抽出されたキーワードを表示
例えば,営業担当者が「デザイン」について説明を始めたとき,図5のポイント1のようにお客さま方の反応がポジティブからネガティブに遷移しているようであれば,営業担当者は次の話題へ切り替えようという判断ができる.また,お客さま方の反応が芳しくないときに,図5のポイント2のように,試しに営業担当者が「ここだけの話」というキーワードを発し,お客さまの反応がポジティブに転じるようであれば,この商談を展開するうえで「ここだけの話」という切口が有効であるという判断ができる.以上のように,音声DX基盤の音声認識や表情感情認識を用いることによって,営業担当者が最適な営業シナリオを選ぶためのサポートが可能となる.

4.3 注釈表示ツール
専門用語や独自用語が多く使われる場面での内容理解を支援する活用例として,音声DX基盤の音声認識技術とキーワード抽出機能を利用した注釈表示ツールがある.
専門的な内容を扱う大学の講義や独自用語が多く話される社内会議では,使われる言葉に対する背景知識の差によって,内容が理解しにくくなってしまうことがある.加えて,大人数が参加する講義や会議では,言葉の意味について質問をすることへの心理的なハードルが高く,また,話し手が聴衆の理解状況を正確に把握することも難しい.
注釈表示ツールは,事前に登録したキーワードが話されたときに,該当のキーワードとその説明を注釈として表示するアプリケーションである.注釈表示ツールを使うことで,話し手がいつもどおりに話している間に,聞き手は表示された注釈から知らない単語に関する基礎知識を補い,内容の理解に役立てることが期待される.また,レベルやカテゴリを設定することで,聞き手の理解度に応じた注釈表示を行うことも可能である.
- プロンプト:生成AIを操作する際にユーザが投入する指示や入力文.
- トークン:テキストの最小単位として扱われる文字や文字列のこと.
05. あとがき
-
本稿では,ドコモの音声分析AIアセットを集約した「音声DX基盤」の特徴と ...
開く
本稿では,ドコモの音声分析AIアセットを集約した「音声DX基盤」の特徴とその活用例を解説した.音声認識,音声感情認識,マルチモーダル感情認識などのさまざまな音声分析AIアセットを,共通のインタフェースを介して利用できるようにすることで,幅広いユースケースでの活用が可能となる.
音声DX基盤を活用したサービスの開発も進んでおり,docomo Open House’24[11]で展示したMetaMe[12]やコミュニケーションAIによるAI接客システム*14では,ユーザの発話テキストだけでなく,感情や話速などの非言語情報も手がかりとした音声対話を実装している.
今後は,音声分析AIアセットのさらなる拡充に加え,社内外での実証実験を通した技術の有効性検証を進め,音声データ起点のDXの推進に貢献していく.
- コミュニケーションAIによるAI接客システム:お客さまの感情や行動特性を考慮した応対を行う音声対話アバターシステムである.従来の音声対話システムと異なり,AI接客システムはユーザの発話テキストに加えて,ユーザの話速や音声や顔画像から取得できるユーザの感情といった非言語情報も手がかりとして,システム応答の生成を行う.
-
文献
開く
- [1] NTTドコモ:“my daiz.”
https://www.docomo.ne.jp/service/mydaiz/ - [2] NTTコミュニケーションズ:“ドコモAIエージェントAPI®.”
https://www.ntt.com/business/services/ai_agent_api.html
- [3] NTT:“音声情報処理.”
https://www.rd.ntt/hil/category/voice - [4] NTT:“進化を続ける音声認識エンジン「VoiceRex®」.”
https://www.rd.ntt/research/JN20190709_h.html - [5] NTT:“次世代メディア処理AI「MediaGnosis®」によるマルチモーダルWebアプリケーションを一般公開開始.”
https://group.ntt/jp/topics/2022/11/16/rd_mediagnosis_demo.html - [6] NTT:“MediaGnosis®次世代メディア処理AI.”
https://www.rd.ntt/mediagnosis/ - [7] R. Masumura, Y. Yamazaki, S. Mizuno, N. Makishima, M. Ihori, M. Uchida, H. Sato, T. Tanaka, A. Takashima, S. Suzuki, S. Orihashi, T. Moriya, N. Hojo and A. Ando:“End-to-End Joint Modeling of Conversation History-Dependent and Independent ASR Systems with Multi-History Training,”In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH), pp.3218-3222, 2022.
- [8] A. Takashima, R. Masumura, A. Ando, Y. Yamazaki, M. Uchida and S. Orihashi: “Interactive Co-Learning with Cross-Modal Transformer for Audio-Visual Emotion Recognition,”In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH), pp.4740-4744, 2022.
- [9] NTTコムウェア:“letaria.”
https://www.nttcom.co.jp/dscb/letaria/index.html - [10] NTTドコモ報道発表資料:“生成AIを活用した業務のDX推進および付加価値サービス提供に向けた実証実験を開始~生成AIの安全性と利便性の向上をめざす「LLM付加価値基盤」を開発~,”Aug. 2023.
- [11] NTTドコモ:“docomo Open House’24共創プロジェクトを、ここから一緒に。,”Jan. 2024.
https://www.docomo.ne.jp/corporate/technology/rd/openhouse/openhouse2024/ - [12] NTTドコモ:“MetaMe.”
https://lp.metame.ne.jp/

