

AI・サービス特集 —文書・画像処理技術—
ビジネスの現場に寄り添うLLM基盤技術
自然言語処理 生成AI DX
駒田 拓也(こまだ たくや)
岡 慶介(おか けいすけ)
辰巳 守祐(たつみ しゅうすけ)
白水 優太朗(しらみず ゆうたろう)
サービスイノベーション部
あらまし
ChatGPTの登場以降,さまざまな分野で大規模言語モデル(LLM)による文書生成AIの利活用が行われる時代となった.しかしながら,業務でのLLMの利用は,「業務専門知識に対応していない」「出力内容に倫理的な懸念がある」「情報流出のリスクがある」などの課題が存在する.そこで,ドコモはこれらの課題を解決するさまざまな付加価値機能をもつLLM付加価値基盤を開発し,ドコモグループに向けて提供を開始した.本稿では,LLMの業務活用を実現するためにLLM付加価値基盤が有する機能とそれを実現する技術について解説する.
01. まえがき
-
ChatGPT[1]の登場以降,さまざまな分野で大規模言語モデル ...
開く

ChatGPT[1]の登場以降,さまざまな分野で大規模言語モデル(LLM:Large Language Model)*1による文書生成AIの利活用が行われる時代となった.文書生成AIの活用範囲は多岐にわたり,メールの文章作成,ドキュメントの要約,アイデアの壁打ち*2,プログラムのサンプルコード生成などの豊富なビジネス応用を行うことが可能である.文書生成AIのビジネス活用への関心は社会的にも高く,昨今ではさまざまな企業が独自に文書生成AIを導入し,社内での利活用に繋げている.
しかしながら,社内業務での文書生成AIの利用においては以下のような課題が存在する.1点目は,業務専門知識に対応できないことである.これは,文書生成AIの事前学習時に社内文書などの非公開情報を訓練データに含めることができず,適正な回答が生成できないためである.2点目は,文書生成AIの出力内容には倫理的な懸念が存在することである.文書生成AIはLLMによりAI自身がゼロから文書を生成するため,事前に出力内容をコントロールすることが難しく,時に倫理的に問題がある文書を生成する可能性がある.実際に文書生成AIの出力が攻撃的な文書を生成しこれを世間に公表することで炎上した事例も数多く存在する.3点目は,情報流出リスクが存在することである.非公開の社内文書を他社がSaaS(Software as a Service)*3形式で提供する文書生成AIに入力することは,機密情報流出リスクの1つとしてみなされることがある.
そこでドコモは,これらの課題を解決するさまざまな付加価値機能を有し,生成AIを業務でも容易かつ安全に使えるLLM付加価値基盤を開発した.LLM付加価値基盤はGUI(Graphical User Interface)*4ベースの,チャット機能を備えたWebアプリケーション*5として提供されており,ユーザはブラウザから基盤にアクセスするだけで生成AIのさまざまな機能を容易に利用することができる.付加価値機能には,外部ファイル参照機能があり,専門的な知識が必要な問いかけについても参考となるファイルを入力することで,精度よく生成AIに応答させることができる.また,倫理フィルタ機能を利用することで生成AIの出力に問題のある表現が無いかどうかを自動的に評価することができる.運用体制では,個人情報の入力に対して機械・目視のハイブリッドによる監視を常に行っており,情報の外部流出をすぐに検知できるようになっている.
本稿では,LLMの業務活用を実現するためにLLM付加価値基盤が有する機能とそれを実現する技術について解説する.
- 大規模言語モデル(LLM):大量の文章データセットを使ってトレーニングされた自然言語処理のモデルのこと.
- アイデアの壁打ち:自身のもつ漠然としたアイデアを他人に話すことで思考を整理すること.特に近年ではLLMをはじめとしたチャットAIの登場から,人間でなくAIを壁打ち相手とすることができるようになった.
- SaaS:インターネットなどのネットワーク経由で利用するソフトウェアのこと.
- GUI:ボタンやアイコンの組合せからなり,直感的な操作性や優れた視認性を特長とするインタフェース.
- Webアプリケーション:インターネットブラウザ上で利用可能なソフトウェアのこと.PCへの事前インストール不要で実行できる特徴をもつ.
02. LLM付加価値基盤
-
2.1 概 要
開く
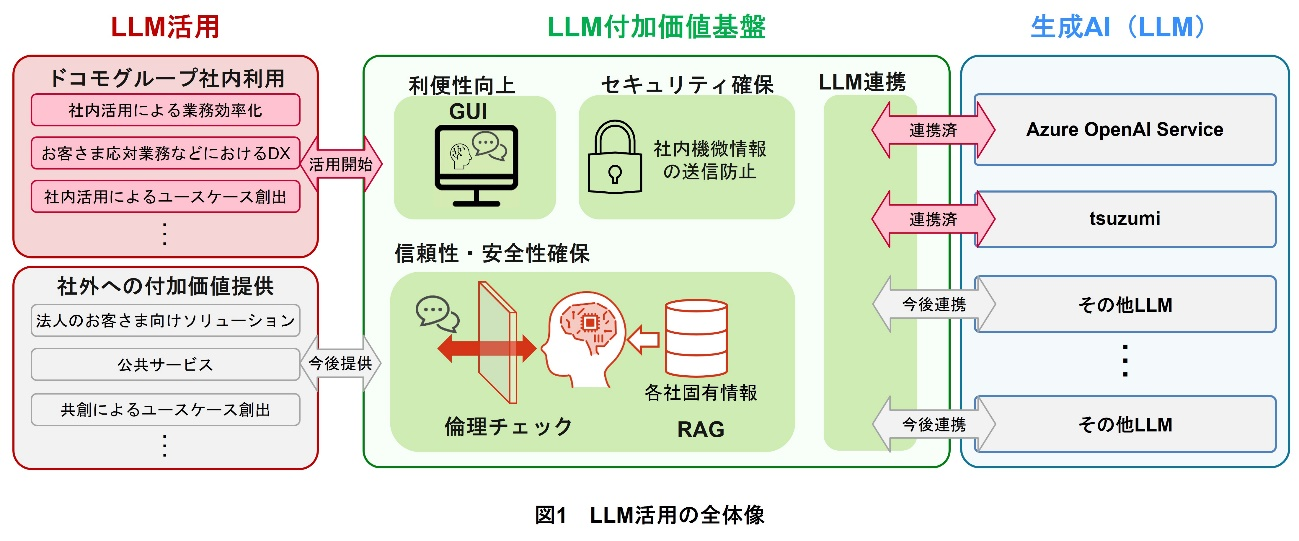
LLM付加価値基盤は,LLMの事業活用を目的として開発された基盤システムの名称であり,Webアプリケーションを通じて提供される.LLM付加価値基盤では,利便性向上,セキュリティ確保,信頼性・安全性確保,LLM連携の4つの観点から機能開発を進めている.ドコモでは,本基盤によってドコモグループでのLLM活用を推進している(図1).また,各機能は,基盤を展開し運用する上で汎用的となる基本機能と,ドコモの独自要素技術を加えた付加価値機能の2つに大別される.以下,基本機能と付加価値機能の詳細について解説する.
2.2 基本機能
(1)機能構成および機能概要
LLM付加価値基盤は基本機能として,GUI,API(Application Programming Interface)*6,ユーザ認証,ログ監視機能とセキュリティを備えている.特にGUIとログ監視は,エンドユーザが生成AIを直感的かつ安全に利用するために必須の機能であり,付加価値基盤の中核をなしている.
LLM付加価値基盤の機能およびシステム構成を図2に示す.LLM付加価値基盤のシステム構成は,①Webサーバ,②アプリケーションサーバ,③APIゲートウェイ*7および④アクセス管理DBから構成され,社内外にホストされたさまざまな生成AIを利用することができる.
- Webサーバでは,ユーザが複雑なコマンドを入力することなく,生成AIおよび後述する付加価値機能を簡易な操作で利用可能とするGUIを提供している.
- アプリケーションサーバは,付加価値機能APIおよび,それらのAPIと生成AIを連携するコントローラからなるマイクロサービスアーキテクチャ*8で構築される.
- APIゲートウェイには,ユーザを管理する機能があり,APIキー*9の発行と発行されたAPIキーによるユーザ認証が可能である.また,各APIは,APIゲートウェイを通じて,付加価値機能と生成AIを連携した形式で提供している.
- アクセス管理DBでは,APIゲートウェイから送信されたユーザ認証情報のうち,所属情報の照合を行い,所属組織ごとの機能制限やアクセス管理を実現している.
これら一連のシステムの環境構築は,IaC(Infrastructure as Code)*10で行われており,システムの更新を安全かつ迅速に対応できるよう工夫している.
(2)GUI
LLM付加価値基盤では,生成AIをチャット形式のインタフェースで利用できるGUIを提供している.さらに,ユーザの利便性向上のため,(a)対話履歴,(b)対話内容の引継ぎ機能および(c)テンプレート機能を実装している.LLM付加価値基盤のGUIを図3に示す.
(a)対話履歴機能
対話履歴機能は,過去に利用した生成AIの入出力を履歴として保存する機能であり,過去のチャットの参照や一度中断したチャットの継続を可能とする.
(b)対話引継ぎ機能
対話引継ぎ機能は,1つのチャット中の入出力の履歴をユーザの現在の入力に含めて,生成AIへリクエストを行う機能であり,チャット上のやり取りを踏まえたマルチターン対話*11を可能とする.
(c)テンプレート機能
テンプレート機能は,ユーザがあらかじめ作成した独自のプロンプト*12を保存する機能である.メール作成業務のような定型的なタスクをプロンプトとして保存することで作業を効率化する.
(3)ログ監視およびセキュリティ確保
LLM付加価値基盤では,多数のユーザが入力制限無しに利用できるため,機密情報の入力を禁止する利用規約を設け,情報流出リスクを低減する運用監視体制を構築している.具体的には,生成AIの入出力を基盤上でログとして保存しており,そのログを定期的に監査している.また,監査時にお客さまの個人情報といった機密情報の入力が発見された場合,該当のログを基盤内から削除し,ユーザへ注意喚起を行っている.
ログの監査は,自動的に入力内容をチェックする個人情報検知器と目視による監視のハイブリッドで行っており,多量のログの監視作業を効率化し,機密情報の流出を迅速に感知できる体制を整えている.
2.3 付加価値機能
(1)LLM連携
LLM付加価値基盤には,ユーザが用途に応じて最適なLLMモデルを選択して使い分けられる,LLM接続機能を実装している.一例として,議事録作成のような比較的文字数の多い文章の入力が想定されるユースケースでは,コンテクストサイズの大きなモデルを選ぶといったことが可能である.
このように,用途に合わせて選択できる複数のモデルの拡充を進めている.一例として,より軽量で業務に活用しやすいNTT研究所提供独自モデルtsuzumi[2]の提供も行っている.
また,多くの生成AIでは,大きなマシンリソースが必要となるため,リクエスト数や単位時間当りの入出力トークン*13数に制限が設けられている.LLM付加価値基盤では,複数のモデルを選択できることでこれらの制限緩和を実現している.
(2)外部知識参照
SaaSやOSS(Open Source Software)*14として提供されている生成AIは,一般知識のみを学習しているため,専門的な知識を回答できず,社内業務での利用が難しい.これに対しては,ファインチューニング*15などで専門知識を獲得させるアプローチが考えられるが,そのために各利用組織で大量の学習データを用意し,計算資源を確保することは容易ではない.
LLM付加価値基盤では,この課題を解決するために,外部知識を入力に取り入れるための機能として,ファイル参照機能および文書検索機能を実装し,専門的な知識の回答を可能とした.
なお,外部知識参照の実装に関する技術的な取組みの詳細は後述する.
(a)ファイル参照機能
通常のチャット形式のユーザ入力に加えて,社内文書などのファイルを生成AIへ入力するインタフェースとしてファイル参照機能を実装している.ファイル参照機能は,アップロードされたユーザファイル内から,ユーザ入力と関連する文書を自動で抽出し,生成AIへ入力するため,ファイル内の情報を含めた回答が可能となる.さらに,ファイル参照機能で利用されたファイルは,LLM付加価値基盤上に保存されないため,機密性を高めながらセキュアに利用できる.
(b)文書検索機能
通常のチャット形式のユーザ入力に加えて,事前にデータストレージへ保存したファイル群を参照し,生成AIへ入力するインタフェースとして文章検索機能を実装している.
ファイル参照機能との違いは,データストレージを利用することで,フォルダにまとめて格納された複数ファイルの参照が可能となり,なおかつ各ユーザの所属情報に基づいた公開範囲をフォルダごとに指定できることである.これにより,複数のユーザの公開範囲を制御することが可能となり,特定のユーザのみを閲覧可能とする必要があるコンテンツを検索するようなケースに対応可能となる.
さらに,ファイル参照機能と同様に,生成AIの入力としてユーザ入力と関連する文書をファイル内から自動抽出するが,文書検索機能ではその抽出文書を出力根拠として提示することで,該当ファイルが手元にないユーザに対しても結果が正しいかどうかの判断が可能となっている.
(3)倫理チェック機能
倫理チェック機能はLLMの出力に対し,倫理的に問題がないかのチェックを行う機能である.ユーザがLLMを利用するユースケースとして,メール作成や対外文書の推敲などが考えられる.しかしLLMは時に非倫理的な文章を生成する可能性があるため,LLMの出力をそのまま他者に見せることには一定のリスクが存在する.倫理チェック機能では,LLMの出力に対して,内容が非倫理的であるかどうかを判定し,非倫理的であると判断された場合にはユーザに警告を行い,ユーザがこの出力を他者に見せる文書に用いないよう注意喚起をする.
なお,倫理チェック機能の実装に関する技術的な取組みの詳細は後述する.
- API:ソフトウェアが互いにやり取りするのに使用するインタフェースの仕様.
- APIゲートウェイ:システムにおいて,クライアントとバックエンドサービスの間に置かれるAPI管理機構のこと.開発者はAPIゲートウェイを用いることで,サービスのセキュリティや性能を集中的に管理することができる.
- マイクロサービスアーキテクチャ:システムを構成する各要素を独立した小さなコンポーネントとして実装する手法.
- APIキー:API利用に必要な認証情報.
- IaC:サーバやネットワーク,ストレージなどのインフラストラクチャの構成をコードとして記述して管理するという考え方.設定やプロビジョニングの作業を自動化できる.
- マルチターン対話:過去の話の流れに沿った複数回の対話のやり取りを実現する対話形式.
- プロンプト:コンピュータやプログラムに対して与える命令のこと.特にLLMの文脈では,LLMの出力を制御する自然言語形式の入力文のことを指す.
- トークン:テキストの最小単位として扱われる文字や文字列のこと.近年の自然言語処理分野では文字よりも小さいバイト単位をトークンとすることが多い.
- OSS:ソースコードが無償で公開されており,誰でも再利用や改変が行えるソフトウェア.ただし,原作者の著作権自体は放棄されておらず,派生物を作成した場合や再配布を行った場合にも,元の著作権表示を保持することが求められる.
- ファインチューニング:あるデータセットを使って事前学習(Pre-training)した学習済みモデルの一部もしくは全体を,別のデータセットを使って再学習することで,新しいタスク向けに機械学習モデルのパラメータを微調整すること.
03. LLMの出力に対する付加価値
-
3.1 概 要
開く
大規模コーパス*16を事前学習したLLMは自由形式で文章を出力することが可能であり,学習やチューニングを実施しなくても,アイデアの壁打ち,一般的な事柄の質疑,雑談などのタスクをこなすことが可能である.しかしながら未学習・未チューニングのLLMをそのまま業務に活用する場合,専門知識への回答性能が低い,非倫理的な内容を回答する可能性がある,という2点の課題が存在する.LLM付加価値基盤ではこれらの課題に対して,それぞれ外部知識参照や倫理チェック機能による技術的解決を図っている.
3.2 外部知識参照
(1)社内情報連携ニーズとLLMの課題
企業においては,各組織のもつ社内規定類や顧客情報などの社内情報をLLMに参照させ,これらの情報に基づいて回答を生成させたいというビジネスニーズがある.企業のもつこれらの情報はWeb上には存在していない非公開情報で,LLMの事前学習データに含まれていないため,LLMはこれらの知識を必要とする質問に対しては,適切な回答を生成できない課題がある.
(2)付加価値基盤で提供している検索拡張生成(RAG:Retrieval-Augmented Generation)関連技術
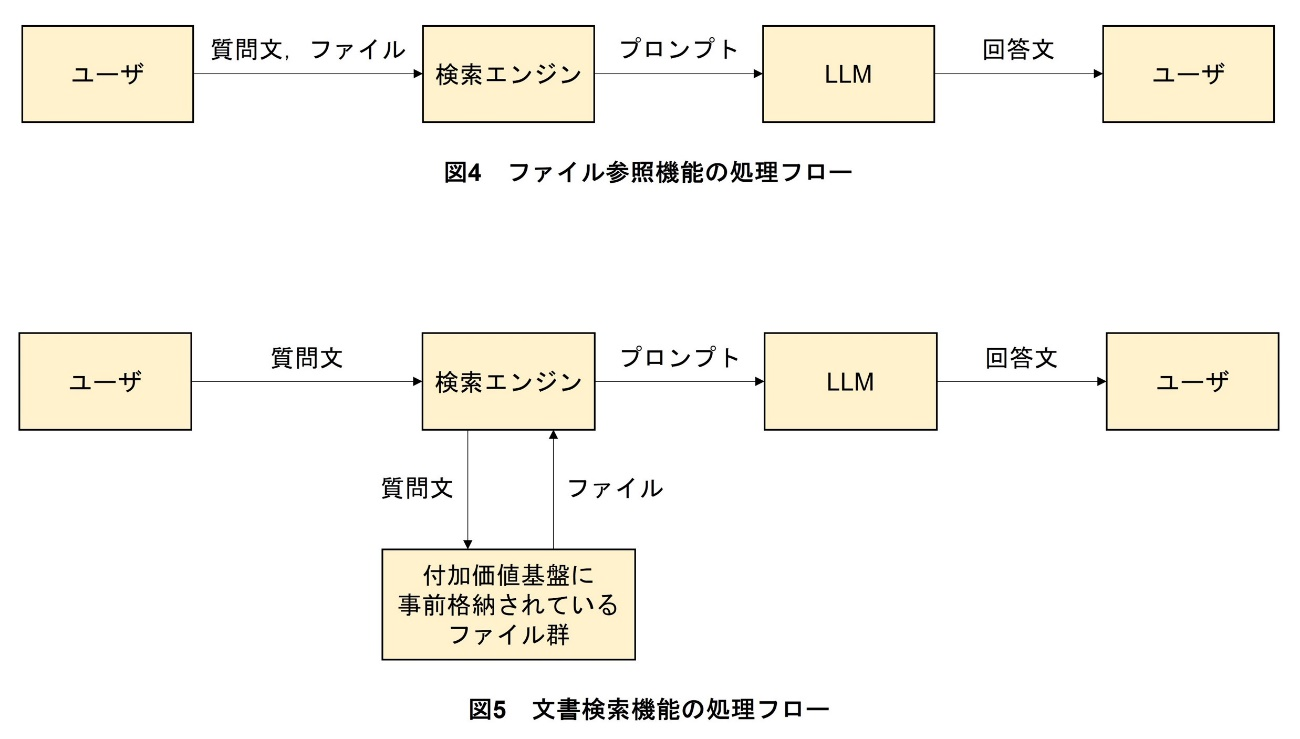
社内データベースに保管されている社内情報をLLMに参照させることで,社内情報に関する質問にも回答を生成できるようにするRAG[3]という技術が注目を集めている.RAGでは,まず,ユーザが入力したプロンプトを基に,検索エンジンが社内データベースを検索する.次に,得られた情報をユーザが入力したプロンプトに追加する.最後に,そのプロンプトに基づいてLLMが回答文を生成し,ユーザに提示する.
LLM付加価値基盤では,RAGをベースとした機能をユースケース別に2種類,具体的には,前述したファイル参照機能と文書検索機能を提供している.いずれも,利用している技術はRAGであるが,LLMが回答生成時に参照するファイルのアップロードタイミングとそのファイルの格納者が異なる.ファイル参照機能は,ユーザがアップロードした,自身のPC上に保存されているファイルの中身を検索エンジンが検索・参照して回答生成する機能であり,図4に示すように,ファイルアップロードを,ユーザが質問を入力する際に行う.一方,文書検索機能は,図5に示すように,管理部門によって付加価値基盤上へ事前にアップロードされた大量のファイル群から,ファイルならびにその中身を検索エンジンが検索・参照して回答生成する機能である.また,文書検索機能には,ユーザのファイルアクセス権限に準拠したファイル参照を行えるように,アクセス制御機能も実装している.
(3)現状の課題と改善策
RAGは,理論上は,事前学習データに含まれていない社内情報などに関する質問に対しても回答を生成できる画期的な技術だが,実用上は,社内情報をLLMに参照させる機能がボトルネックとなり,適切な回答を生成できないことが多い.そこで,ドコモは社内情報をLLMに参照させる際の動作,特に図表の読取りとファイル検索の精度向上に取り組んでいる.
(a)図表情報の読取り精度の改善策
LLMの入出力形式はテキストデータであるため,参照できる情報も基本的にはテキストデータのみである.一方,社内情報には文章だけでなく多くの図表情報が含まれている.シンプルな図表からはまとまったテキストデータとして情報を抽出できるものの,複雑な図表からは意味のあるまとまりのテキストデータとして情報を抽出しきれず,LLMが必要な情報を参照しきれない.
そこで,現在ドコモは,座標情報を活用したAI+OCR(Optical Character Recognition)*17技術と,それらの技術によって図表から抽出したテキストデータをマークダウン形式*18でLLMに入力する手法を検証している.検証を通して,これらの手法により,図表の構造情報によるテキストの位置関係を極力欠落させることなくLLMに参照させられることが分かってきている.
(b)参照ファイルをQ&A形式に変換することによる検索精度向上
ユーザの質問文とLLMに参照させるファイルの文体が異なると,検索精度が落ちることが知られている.そこで,現在ドコモでは,ファイルの文体を質問文と近づければ,検索精度が向上するという仮定のもと,格納するファイルをQ&A形式に変換する手法を検証している.具体的には,ファイルを格納する際,ファイルそのものを格納するのではなく,ファイルに書かれている内容をQ&A形式に変換し,変換後のファイルを格納している.Q&A形式への変換では,LLMを使って自動で行っている.具体的には,ファイルのテキスト文と「ファイルに関するQ&Aを生成してください」という旨の指示文からなるプロンプトをLLMに入力することで,LLMにQ&Aを自動生成させている.検証を通して,この前処理の追加により,検索精度が向上することが分かってきている.
3.3 倫理チェック機能
(1)倫理チェックの必要性
LLMはテキストをテンプレートなど無く自由に生成できるという特性から,時に不適切な内容の文章を出力する可能性がある.LLMが出力する文章の不適切性は2種類に大別され,①倫理的に不適切な文章を出力すること,②事実と異なる内容を出力すること(ハルシネーション)が挙げられる.特に①の観点では,過去LLMを活用して文書生成のサービスを提供した事業者が,そのLLMによって出力された不適切な内容に起因してSNS上で炎上した事例が複数存在する[4].
非倫理的な内容は有害であり,社内外に向けて公表してしまうと,SNSで炎上したり,企業評価・信用の低下リスクに繋がったりするリスクがある.これらのリスクに備えるべく,LLM付加価値基盤では,不適切な出力のうち①の課題に対して,LLMの出力に倫理的問題がないかをチェックする倫理チェック機能を開発している.
(2)倫理チェック機能の概要
倫理チェック機能は,入力された文章が倫理的に問題をもつか否かを判定する文書分類器*19を中心としたシステムである.倫理チェック機能では,文書分類器がLLMの生成したテキストを評価し,倫理的な側面を検証する.具体的には,文書分類器は,事前に定義された倫理カテゴリ体系に基づいて,テキストが特定の倫理的問題を含んでいないかの判定を行う.
倫理チェック機能で利用されるカテゴリ体系は,独自に定義された8つのカテゴリによって構成されている.分類器は,テキスト内容が各カテゴリそれぞれに該当するかどうかを判断する8つの2値分類*20器からなり,これらが各カテゴリへの該当可能性を確率的に出力する.
倫理チェック機能を用いることで,テキストが特定のカテゴリに該当するかどうかを客観的に評価することができ,LLMが倫理的に不適切な文書を出力した場合には,ユーザに生成内容の倫理性に関するアラート喚起ができるようになる.
(3)カテゴリ体系と分類器
現在世界で提供されている倫理チェック機能のサービスとしてOpenAI Moderation APIやPerspective APIなどが挙げられるが,これらのサービスは米国英語の表現や文化的背景を前提としており,また柔軟性や多様性の点でドコモの倫理チェック機能とは差異が存在する.特に,カテゴリ体系を自由に書き換えることができないという点や,あくまでビジネス向けではないという課題が存在する.LLM付加価値基盤の倫理チェック機能は,カテゴリ体系と分類器を独自に構築することで,こういった課題に柔軟に対処できる強みをもつ.
倫理チェック機能のカテゴリ体系を表1に示す.倫理チェック機能のカテゴリ体系は,先行研究[5]や類似サービスのカテゴリ体系,社内での対外文書チェック基準を参考にして,卑語,差別表現,暴力表現,卑猥表現,違法表現,多様性の尊重,企業NGの7つのカテゴリで構成される.前者の6つのカテゴリでは基本的な不適切な表現の分類を行い,これらにより炎上リスクのある文章などが出力された場合に,これを事前に検出できるようになる.
企業NGカテゴリの詳細カテゴリを表2に示す.企業NGカテゴリでは,特に企業での業務活用時のリスク対策として,競合誘引,景品表示法・薬機法に関連する表現,飲酒・賭博などの違法ではないが取扱いの難しい表現についての分類チェックを行う.これにより世間一般の非倫理的という枠を超えて,企業特有の炎上リスクをもつような文章に対しても対応ができるようになっている.
倫理チェック機能では,こういったカテゴリ体系を独自にカスタマイズ・チューニングすることができ,ビジネス向き,日本語ユーザ向きといった企業活用ニーズに細かく対応できる利点がある.
また,倫理チェックを行う分類AIは動作速度と精度を重視し,LLMではなく,各カテゴリの2値分類データセットで微調整したBERT(Bidirectional Encoder Representations from Transformers)*21モデルを利用している.特にBERTの事前学習モデル*22にはNTT研究所作成のNTT BERT*23を用いており,NTT BERTの高い日本語性能を活かした分類器での倫理チェック機能の開発を行っている.

- コーパス:テキストを大量に収集してデータベース化した言語資料.
- OCR:画像内の活字や手書き文字を認識し,コンピュータで取り扱えるテキストデータに変換する技術のこと.
- マークダウン形式:テキストや表を記述,装飾する記法の1つ.プレーンテキスト形式で記述するため取り回しが良く,さまざまなサービスで利用される.
- 分類器:入力を,その特徴量に基づいてあらかじめ定められた分類先のいずれかに分類する装置.
- 2値分類:入力文書があるカテゴリに該当するか・該当しないかの形式で行う分類.
- BERT:Googleが開発した自然言語処理モデル.微調整をすることでさまざまな自然言語処理タスクで高精度を達成している.
- 事前学習モデル:目的タスクの教師あり学習実施前に,大量のコーパスで教師なし学習したモデル.
- NTT BERT:NTT人間情報研究所が独自で学習データを収集し,そのデータで事前学習させたBERTモデル.
04. あとがき
-
本稿では,LLMのビジネス活用に向け社内展開を行っているLLM付加価値基盤の ...
開く
本稿では,LLMのビジネス活用に向け社内展開を行っているLLM付加価値基盤の概要と基本機能を説明し,付加価値機能として専門知識が必要な問いかけにファイル参照を用いて回答するRAG,倫理性を担保する倫理チェックの機能について解説した.
ユーザはWebブラウザからGUIにアクセスすることで,対話履歴機能,対話内容の引継ぎ機能やテンプレート機能などの基本的な対話機能を備えたAIと対話を行うことができ,社内の専門的な知識についてもRAGを用いた文書生成で生成AIに応答させられるLLM付加価値基盤を利用できる.また,出力内容が倫理的に問題ないものかをチェックする倫理チェック機能も利用可能である.
今後は,社内での実利用検証と並行して,さらなる付加価値の付与として社内から要望のある機能の追加実装,RAGの精度向上,要望に応じた倫理チェック機能のカスタマイズなどを行い,LLM付加価値基盤の利便性を向上させていきたい.
-
文献
開く
- [1] OpenAI:“ChatGPT.”
https://chat.openai.com/
- [2] NTT人間情報研究所:“NTT版大規模言語モデル「tsuzumi」.”
https://www.rd.ntt/research/LLM_tsuzumi.html - [3] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. -T. Yih, T. Rocktäschel, S. Riedel and D. Kiela:“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” NeurIPS 2020, Apr. 2021.
- [4] BBC NEWS:“Tay:Microsoft issues apology over racist chatbot fiasco.”
https://www.bbc.com/news/technology-35902104 - [5] 小林 滉河,山崎 天,吉川 克正,牧田 光晴,中町 礼文,佐藤 京也,浅原 正幸,佐藤 敏紀:“日本語有害表現スキーマの提案と評価,” 言語処理学会第29回年次大会発表論文集,pp.933–938,Mar. 2023.

