

コンテンツメタ情報を活用したセレンディピティのあるレコメンドエンジンの開発
レコメンド 機械学習 自然言語処理
相場 邦宏(あいば くにひろ) 明石 航(あかし わたる)
加藤 剛志(かとう たけし)
サービスイノベーション部
伊藤 拓(いとう たく)
プロダクトデザイン部
あらまし
映像配信サイトなどにおいて,レコメンドエンジンを活用したコンテンツ推薦がさかんに行われている.そのアルゴリズムはさまざまだが,ユーザの行動履歴を利用したレコメンドではクリック率を高めるために,推薦対象が人気作に偏ってしまうという課題がある.そこでドコモでは,ジャンルやあらすじなどのコンテンツのメタ情報を活用し,クリック率が高い人気コンテンツだけでなくユーザが興味をもつようなコンテンツも提供することで,新たな気付きを与えることのできるレコメンドエンジンを開発した.
01. まえがき
-
近年,映像配信サイト,EC(Electronic Commerce)サイト*1,SNSなどにおいて, ...
開く

近年,映像配信サイト,EC(Electronic Commerce)サイト*1,SNSなどにおいて,個人を特定せず計算できる仕組みを用いて,ユーザの行動履歴を基にしたレコメンド(コンテンツの推薦)を行う広告配信やマッチングサービスが主流となっている.レコメンドの目的はサービスによって異なるが,一般的にはユーザに新たな発見を与え,回遊*2,購買を促すといったものが多い.また,そのロジックは人気なコンテンツをランキング形式で出すという単純なものから,履歴を機械学習*3などによって高度に学習・予測する手法まで幅広く存在する.
ここで,レコメンドエンジンの開発で特に気を付けるべきは,その推薦内容がユーザの履歴に基づいて計算される点である.履歴に基づいて自動生成される内容はコンテンツ(ページ)のアクセス・閲覧特性を反映することが多く,コンテンツ(ページ)のレコメンド表示枠別に適切なアルゴリズムを検討する必要がある.そこで考慮すべき課題として,「表示されるコンテンツが人気なものに偏ってしまう」,といった現象が挙げられる.例えば,人気コンテンツで構成される人気ランキングのリストのみを表示していた場合,表示されるものは一定のクリック率*4を達成できるが,それ以外のコンテンツを表示することができず,一度人気コンテンツを見たことのあるユーザはサービスから離れてしまう.
本誌過去記事[1]において,アルゴリズムの工夫により,レコメンドの偏りに対する1つの解決策を提示したが,今回ユーザの履歴のみならず,コンテンツのメタ情報を考慮する新しいアプローチにより,ユーザに新しい発見・気付き(セレンディピティ)を与えられるロジックを新たに開発した.実際にこのロジックを採用したエンジンを適用したサービスでは,クリックされるコンテンツの種類,また,ホーム画面全体のクリック数を増加させることを達成し,セレンディピティのあるレコメンドを実現した.本稿では,レコメンドにおいて考慮が必要な課題,適用したアルゴリズム,実サービスでの効果について解説する.
- ECサイト:商品やサービスを販売するWebサイト.
- 回遊:WebサイトなどにおいてユーザがWebページを遷移,閲覧すること.
- 機械学習:事例をもとにした統計処理により,計算機に入力と出力の関係を学習させる枠組み.
- クリック率:レコメンドエンジンがコンテンツを表示した回数に対して,ユーザが実際にコンテンツをクリックした回数の割合.
02. レコメンドとセレンディピティ
-
2.1 レコメンドにおける課題
開く
現状のレコメンドにおける代表的な課題として,本稿では大きく2つの問題について紹介する.
(1)コールドスタート問題
これは,一般的にはユーザの行動データが蓄積されるまでは精度の高い結果が得られないという課題である.基本的にレコメンドエンジンは履歴をベースにした学習を行うため,そもそも履歴が少なければユーザにとって最適なものが何かを判断できず,回遊・購買に繋がるようなコンテンツをおすすめすることができない.新規サービスのリリース時によくある課題ではあるが,既存のサービスでも,新規コンテンツが流入してきた際には,そのコンテンツに関する「誰がクリックしたか」という情報が事前には得られないため推薦が行えない,というコールドスタート問題も存在する.
(2)フィルターバブル問題
これは,ユーザの行動を学習し,最適なコンテンツを提示していくサイクルを繰り返した際に発生してしまう課題である.その際,ユーザ側には履歴に関係する決まった範囲のコンテンツしか提示されなくなり,その他の「もしかしたら興味があったかもしれないコンテンツ」とは分断されてしまう.この,ユーザが一定のフィルタされた情報の泡に閉じ込められたかのような状況をフィルターバブルといい,レコメンドにおける大きな課題となっている(図1).解決策はさまざま検討されているが,それらをサービスに適切に合わせていく必要がある.
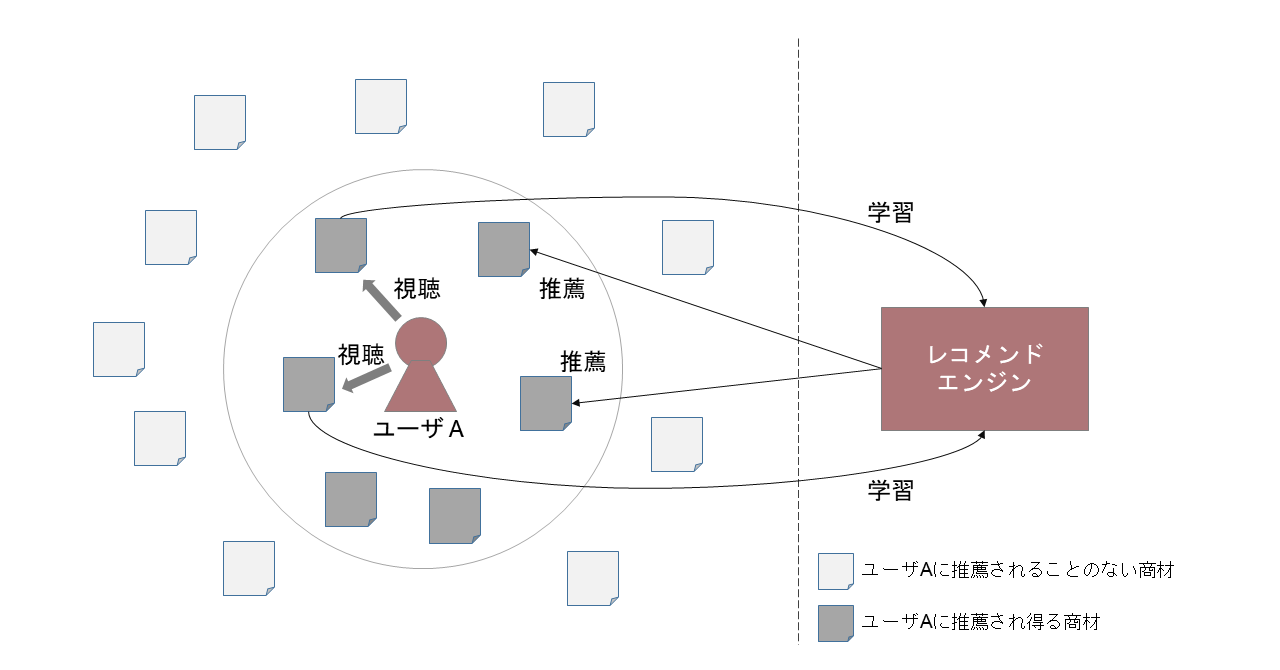
図1 フィルターバブルのイメージ
2.2 セレンディピティの重要性
レコメンドにおける重要な考え方の1つに,セレンディピティというものがある.これは,偶然の素敵な出会い,などと訳されるもので,レコメンドにおいては,ユーザが過去に自力で見つけられなかったコンテンツをレコメンドエンジンが提示し,ユーザにクリックさせることができた際にセレンディピティがあると評価されることが多い.ユーザに新たな発見を与え,回遊,購買を促すといったレコメンドエンジンの目的を踏まえると,セレンディピティがクリック率と並んで重要な指標であると考えられる.ここで,先に挙げた課題と併せて考えたとき,(1)のように新規コンテンツに対するクリックが無く,コールドスタート問題が発生するような状況では,そのコンテンツを求めていたかもしれないユーザに対しておすすめ表示できないことはコンテンツ提供側にとって大きな損失となり得る.また,(2)のフィルターバブル問題が発生しているようなサービスでは,同じようなカテゴリ,内容のコンテンツしかユーザに提示されないため,このセレンディピティが低いと考えられる.このように,レコメンドの課題は言わばセレンディピティにおける課題でもあり,セレンディピティを考えることが課題解決にも繋がる.そこで,このようなセレンディピティを意識したアルゴリズムでレコメンドエンジンを構築した.
03. 提案手法
-
3.1 概要
開く
ドコモでは,レコメンドにおけるセレンディピティの向上をめざし,映像配信サイトにおいて,ユーザの履歴だけでなく,作品の情報を考慮できるレコメンドエンジンを構築した.エンジンは,下記3つの処理を行う.
- ①作品のメタ情報のベクトル化
- ②ユーザベクトルの獲得
- ③作品とユーザベクトル情報を加味したモデル学習
上記の順に計算を行うことで,ユーザの履歴を加味しつつ,ユーザの好きなものをメタ情報としてもつ作品を提示できるようにした.これにより新しい発見を促すようなレコメンドを実現した.なお,本技術はメタ情報を用いることができればドメイン*5を問わず適用可能であるが,以降は一例として動画系サービスにおける適用について解説する.
3.2 作品のメタ情報のベクトル化
各作品のメタ情報をレコメンドに活用するために,レコメンドエンジンに搭載する機械学習モデルが学習しやすい形にメタ情報を変換できるように,今回は,自然言語*6を複数次元のベクトル(分散表現*7)の形で獲得する手法を利用した.ベクトル化の際の工夫として,作品から得られるタイトル,ジャンル,詳細説明文などのメタ情報に対し,同じ作品の中に登場する単語は近くなるようモデルに学習させた.これにより,同じ単語をもつ作品同士は当然近く,さらに,タイトルとジャンル,タイトルと詳細説明文,ジャンルと詳細説明文内の単語もそれぞれ自然と近くなるようベクトルを獲得することができる.
3.3 ユーザ情報のベクトル化
次に,ユーザがどの作品を好むかをモデルに学習させるため,ユーザ側に対してもベクトルを作成する.具体的にはユーザが過去に視聴した作品のタイトル,ジャンル,詳細説明文ごとに算出したベクトルの作品間平均を取り,ベクトルを作成した.これにより,いわばユーザの好きなタイトル,ジャンル,詳細説明文を表すベクトルを獲得することができる.
3.4 ベクトル情報を基にした学習
獲得したベクトルを基にユーザ最適な作品を推薦するため,DeepFM[2]という手法を利用した.DeepFMはDeep LearningとFM(Factorization Machines)[3]を組み合わせた造語であり,その名のとおり,Deep LearningとFMの特徴を併せもっている.Deep Learningは端的に言えば多層のニューラルネットワーク*8を用いた学習手法で,膨大なパラメータによって特徴量の関係性を学習することを指す.FMは,複数の特徴量間の相互作用を適切に考慮できるよう工夫されたモデルで,レコメンドの分野では以前より高い性能を発揮している.この2つを適切に組み合わせたのがDeepFMで,Deep Learningによる高い予測性能と,FMによる相互作用考慮の双方に強みをもつ.このDeepFMに入力データ(説明変数)と正解データを与えて学習させた.その際,入力データ(説明変数)を前述の作品のベクトル,ユーザのベクトルとし,正解データとして,入力データが過去に視聴を行ったユーザと視聴された作品のペアなら1,そうでなければ0を学習させた(図2).
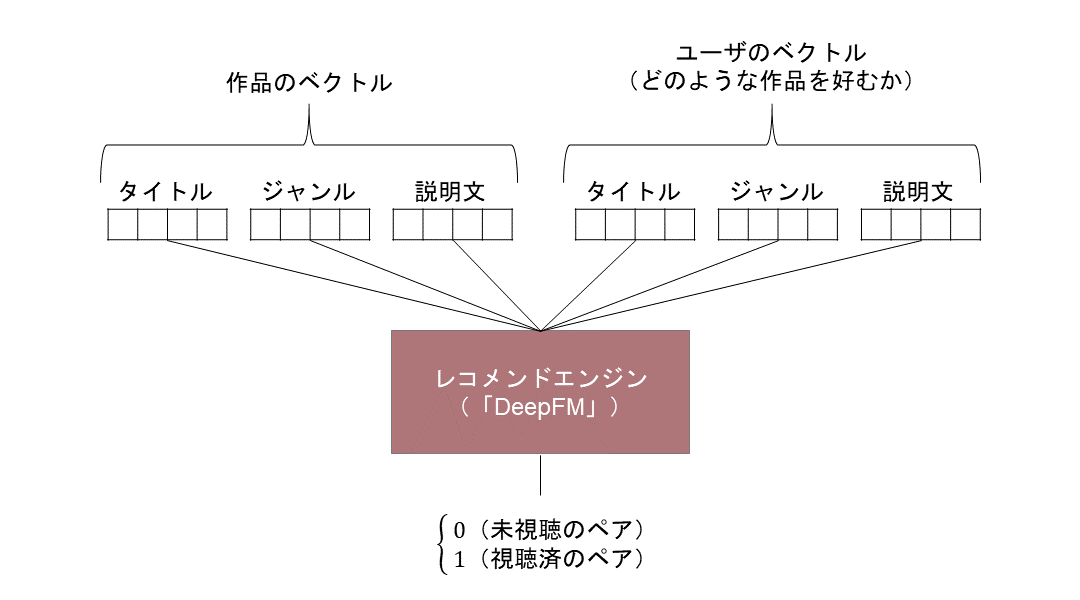
図2 モデルの学習イメージ
これにより,どのような作品を好きな人が,どのような作品を好むのか,作品のタイトルやジャンルなどの相互作用も加味された形での学習を可能とした.こうして学習されたモデルにおける推論時の結果は,擬似的に視聴可能性を表す確率と見なすことができる.また,本技術はメタ情報を活用して推論するため,1回もクリックされていない作品に対してもスコアを計算,推薦でき,コールドスタート問題に対し一定の解決を図っていることも特長の1つである.
- ドメイン:機械翻訳の利用シーンに相当するもの.
- 自然言語:日本語や英語などの言語のことで,本稿では主に文章などのテキストを指す.
- 分散表現:自然言語をベクトル表現したもの.
- ニューラルネットワーク:人間の脳内の神経回路網を数式モデルで表したもの.入力層,中間層,出力層から構成される.
04. サービスへの適用結果と考察
-
4.1 ドコモテレビターミナル(セットトップボックス)への適用結果
開く
本レコメンド技術を,実際の自社サービスであるドコモテレビターミナル*9[4]向けホーム画面の「あなたにおすすめ枠」(以下,おすすめ枠)に適用した(図3).検証のため,本エンジンと従来の一般的な機械学習モデルとのA/Bテスト*10を実施し,この際の結果としては,下記2つが特徴的であった.
- ①エンジンが推薦しクリックされたコンテンツの種類が従来の機械学習モデルの2倍以上に増加(図4)
- ②サービスのホーム画面全体のクリック数が従来の機械学習モデルに比べて増加(図5)
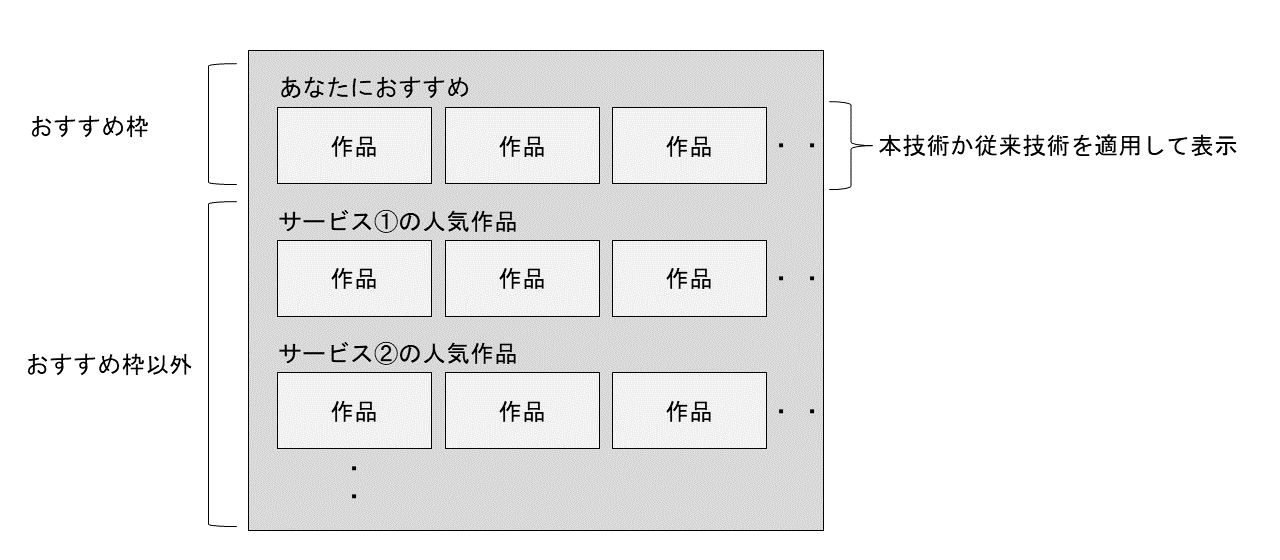
図3 ドコモテレビターミナルホーム画面のイメージ
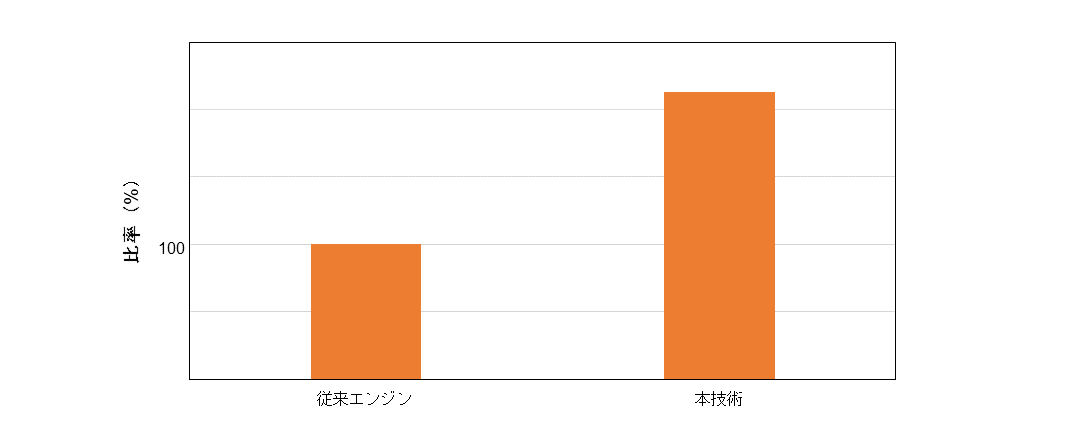
図4 従来エンジンを100としたときのおすすめ枠において
クリックされたコンテンツの種類数の比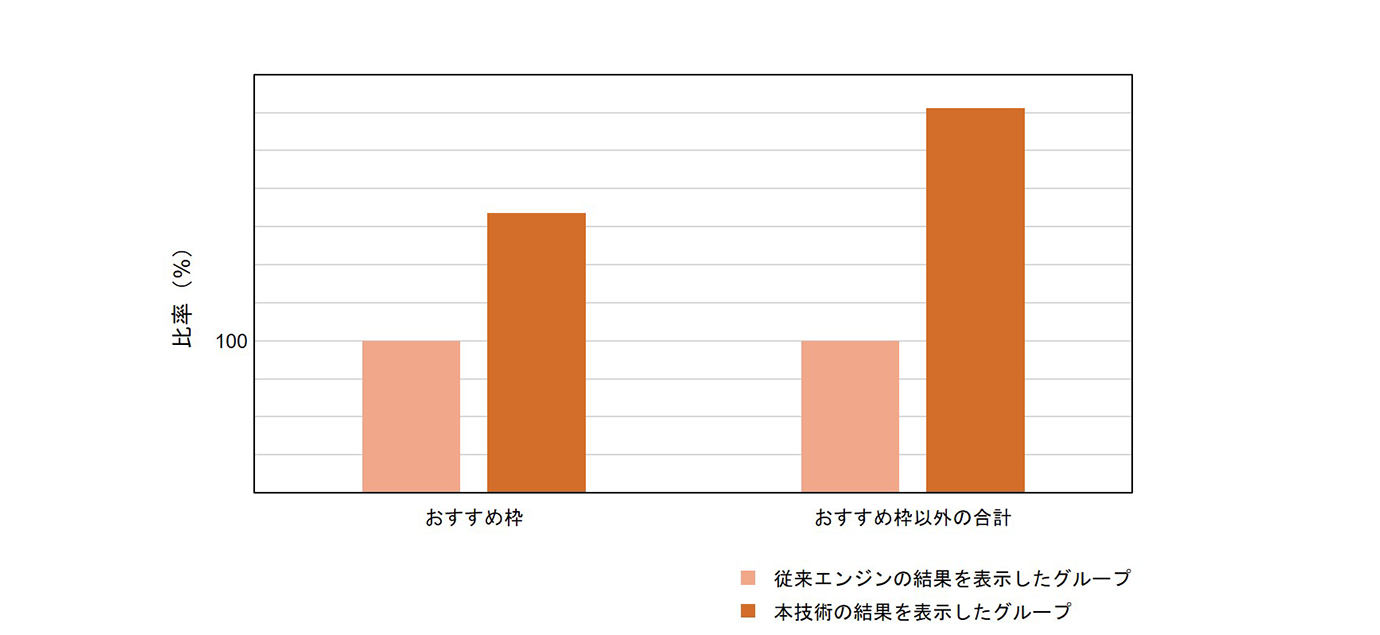
図5 ホーム画面における従来エンジンのクリック数を100としたときの比
ここで,図3に示すように,ドコモテレビターミナルサービスのホーム画面にはA/Bテストの対象であるおすすめ枠のほかに,ドコモの映像サービスごとの人気ランキングなどを表示する枠(おすすめ枠以外)も存在する.特に②については,おすすめ枠におけるクリック数の増加とおすすめ枠以外のクリック数の増加に差があった.これらの影響や理由について考察する.
4.2 視聴コンテンツのカバレッジ増大
A/Bテストにおいて,ユーザがクリックしたコンテンツの種類が増加したことは,本エンジンがユーザに対しセレンディピティの高いコンテンツ,つまりユーザが今まで視聴したことのなかったコンテンツを提示でき,それに対してユーザが興味をもってクリックを行ったことを示している.この理由としては,人気コンテンツでない作品でもメタ情報から推薦すべき内容であれば推薦する手法をとったことで,ユーザの視聴傾向の範囲の外にあるが,ユーザが興味をもつ可能性の高いコンテンツの提示ができるようになったためだと考えられる.
4.3 ホーム画面全体のクリック増加
今回のA/Bテストでは,図5に示すとおり,テスト対象となっていないおすすめ枠以外のクリック数が顕著に増加した.この理由として,本技術を用いたおすすめ枠では,人気コンテンツ以外の幅広いコンテンツが表示されており,人気ランキングなどのおすすめ枠以外で表示されたコンテンツとの差異もあることから,ユーザはおすすめ枠とそれ以外の枠から広く自分の好みの軸で作品を選ぶような行動の変化があったと考えられる.一方,A/Bテストの対向エンジンによるおすすめ枠は人気のコンテンツに偏っており,おすすめ枠以外との内容の差がなかったため全体のクリック数が少なくなったと想定される.従って,今回のアルゴリズムの導入は,おすすめ枠やおすすめ枠以外などのレコメンド枠ごとにどのようなコンテンツをおすすめするかの方向性を変えたことで,より多くのユーザの回遊を促す効果もあったといえる.
- ドコモテレビターミナル:テレビに繋ぐことでドコモの映像サービスなどを1台でまとめて視聴することのできるサービス.最新の製品名は「ドコモテレビターミナル02」.
- A/Bテスト:特定の機能について,AとBの2種類の効果を比較するためその機能以外の条件を統制して行うテストのこと.ここではAとBの2つのアルゴリズムによる推薦結果をユーザに出し分けている.
05. あとがき
-
本稿では,メタ情報を活用したレコメンドエンジンにより, ...
開く
本稿では,メタ情報を活用したレコメンドエンジンにより,セレンディピティのあるレコメンドを実現した事例について解説した.「フィルターバブル問題」でも紹介したように,レコメンドエンジンの結果は人気コンテンツに収束しやすい傾向があるが,本技術ではメタ情報の活用により,意外性のあるコンテンツを適切にユーザに表示することで,新たな発見を促すことに成功した.本技術はすでにサービス上で活用されているが,今後もより良いユーザ体験の創出に向けて,本技術の改良に努めていきたい.
-
文献
開く
- [1] 伊藤 拓,ほか:“ユーザ行動の時系列予測モデルを利用したレコメンドエンジンの開発,”本誌, Vol.29, No.4, pp.26-32,Jan. 2022.
- [2] H. Guo, R. Tang, Y. Ye, Z. Li and X. He:“DeepFM: A Factorization-Machine based Neural Network for CTR Prediction,”arXiv preprint, arXiv:1703.04247, Mar. 2017.
- [3] S. Rendle:“Factorization machines,”In 2010 IEEE International conference on data mining, pp.995-1000, Dec. 2010.
- [4] NTTドコモ:“ドコモテレビターミナル02,”Dec. 2022時点.
https://www.docomo.ne.jp/product/tt02/

