

秘匿クロス統計技術特集 ―企業横断の統計的なデータ活用による社会課題解決―
企業横断の統計的なデータ活用における安全性を達成する手法
プライバシー保護 セキュリティ 差分プライバシー
野澤 一真(のざわ かずま) 長谷川 慶太(はせがわ けいた)
落合 桂一(おちあい けいいち) 中川 智尋(なかがわ ともひろ)
佐々木 一也(ささき かずや) 寺田 雅之(てらだ まさゆき)
クロステック開発部
紀伊 真昇(きい まさのぶ) 市川 敦謙(いちかわ あつのり)
宮澤 俊之(みやざわ としゆき)
NTT社会情報研究所
あらまし
企業を横断した統計的なデータ活用は,単一企業では得られない新たな視点を得るための方法であり,これによって得られた知見を活用することで,社会課題の解決に繋がる.しかし,出力データを作成する過程において,自社のデータが他社に明かされることや,出力データのプライバシー保証の課題がある.そこで,ドコモはこれらの課題を解決する秘匿クロス統計技術を開発した.本稿では,企業を横断した統計的なデータ活用における満たすべき安全性要件を整理し,秘匿クロス統計技術で用いられるセキュアマッチングプロトコル,差分プライバシーに基づくノイズ付加技術,隔離実行環境を併用した安全性要件を満たす手法を解説する.
01. まえがき
-
複数企業が保有するデータを企業横断で利活用することで, ...
開く

複数企業が保有するデータを企業横断で利活用することで,単一企業では得られない視点でのデータ分析を実現し,社会課題の解決に繋がる価値を創出すると期待されている.企業横断でのデータ利活用の方法として,複数企業のデータから,個人のプライバシー情報を保護しつつ,統計情報を作成し活用すること(以下,企業横断の統計的データ活用)が考えられる.企業横断の統計的データ活用における安全性要件では,1つ目にデータ連携前に個人を識別できないデータに加工し,データ連携中に自社のデータが他社に明かされないこと,2つ目にデータ連携後の出力データにおけるプライバシー情報が保護されることが求められる[1].
プライバシー情報を保護した上で,企業横断の統計的データ活用を行うためには,これらの要件を満たす必要がある.そこでドコモでは,これらの要件を技術的に満たすことを目的として,準同型暗号技術,差分プライバシー*1に基づくノイズ付加*2技術,隔離実行環境*3を応用することで,データを相互に明かすことなく,すなわち,一連の処理を人の目に触れることなく機械が行うことを保証して,安全な統計情報作成を実現する秘匿クロス統計技術を開発した.本稿では,本特集冒頭記事[1]で述べた企業横断の統計的データ活用における課題と要件を踏まえて,秘匿クロス統計技術が満たすべき安全性要件とそのデータ処理方法について解説する.
また,秘匿クロス統計技術の処理の正しさについては隔離実行環境と呼ばれる技術を用いた保証により達成する構成となっている.その内容については本特集別記事[2]で述べる.
- 差分プライバシー:特定の背景知識や攻撃能力をもつ攻撃者に対しても安全性を保証できることを目的として作成された,プライバシー保護の強度を定量的に測る指標.なお,米国国勢調査においても,「差分プライバシー」を用いた保護手法が採用されている.
- ノイズ付加:出力データからプライバシー情報を保護するため,集計表に対して,乱数を付与すること.
- 隔離実行環境:ホストOSから論理的に隔離された安全な実行環境.ホストOSからメモリやCPUなどのリソースにアクセスすることはできない.
02. 秘匿クロス統計技術が達成すべき安全性要件
-
ここでは,本特集冒頭記事[1]で述べた企業横断の統計的データ活用 ...
開く
ここでは,本特集冒頭記事[1]で述べた企業横断の統計的データ活用における課題と要件から,秘匿クロス統計技術が達成すべき安全性要件を整理する.
2.1 企業横断の統計的データ活用
企業横断の統計的データ活用において,想定されるデータ形式を図1に示す.企業A,BはテーブルTA(例えば,企業Aが保有する位置情報から得られた,ある施設を訪問したユーザのリスト),TB(例えば,企業Bが保有する20代男性のリスト)をそれぞれ保有しており,テーブルTA,TBには企業間で共通のデータ形式であるIDリストIDA,IDB(例えば,電話番号など)が格納されている.なお,IDリストが少数にならないように,IDリストの付加情報(ある施設を訪問したユーザや,20代男性などの情報)は十分に丸められている.このとき,企業横断の統計的データ活用とは,企業A,BのテーブルTA,TBから,ある施設を訪問した20代男性の人数を求めるため,IDリストIDA,IDBが一致する数を集計した,集計テーブルを作成し,それを企業Aまたは企業Bの施策に活用することである.集計テーブルはテーブルTAとTBの共通集合要素数であり,いずれか一方の企業のデータのみでは作成することができない.なお,統計的データとして,企業間でのデータの平均値や中央値などさまざま想定されるが,本稿では集計値(共通集合の要素数)を前提とする.
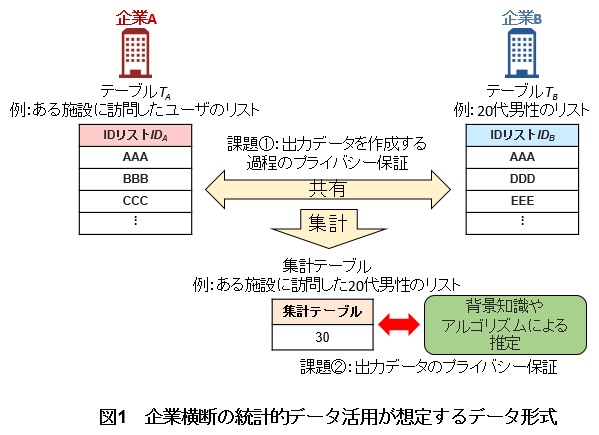
図1 企業横断の統計的データ活用が想定するデータ形式
2.2 企業横断の統計的データ活用における課題
ここで,企業横断の統計的データ活用をする際に,出力データを作成する過程のプライバシー保証と出力データのプライバシー保証の課題が生じる(図1).
(1)出力データを作成する過程のプライバシー保証
出力データを作成する過程のプライバシー保証の課題とは,企業横断で統計情報を作成する際にデータ連携先や第三者に対してプライバシー情報が明かされる*4ことである.企業のデータを横断して統計情報を得るためには,通常ならば,企業A,Bの少なくとも一方はテーブルTAもしくはTBを,相手企業に明かす必要がある.例えば,企業Bは明かされた企業Aの情報(ある施設に訪問したユーザのリスト)から,特定のユーザがある施設に訪問したことが分かってしまう.
そのため,満たすべき安全性要件(以下,安全性要件①)として,データ連携前にテーブルTA,TBを,個人を識別できないデータに加工し,データ連携中にテーブルTA,TBに関する個人のプライバシー情報が出力である集計テーブルを除いて他社に明かされないことが求められる.
(2)出力データのプライバシー保証
出力データのプライバシー保証の課題とは,出力結果である集計テーブルからのプライバシー侵害である.仮に安全性要件①を満たすデータ処理を実現したとしても,出力である集計テーブルからプライバシー情報が明かされる可能性がある[3][4].例えば,企業Bが自社の入力リストの人数を知っており,その値が集計結果の値と合致した場合には,企業Bの入力リストのユーザ全員がある施設を訪問したことが分かってしまう.さらに,企業Bに限らず,企業Aや第三者においても集計テーブルから,ユーザの情報が明かされる可能性が存在する.
そのため,満たすべき安全性要件の2つ目(以下,安全性要件②)として,集計テーブルTCにおいて,テーブルTA,TBに関する個人のプライバシー情報が適切に保護されることが求められる.
以上から,秘匿クロス統計技術が満たす安全性要件を以下にまとめる.
- 安全性要件①:データ連携前にテーブルTA,TBを,個人を識別できないデータに加工し,データ連携中にテーブルTA,TBのプライバシー情報は,出力である集計テーブルを除いて,他社に明かされないこと.
- 安全性要件②:集計テーブルにおいて,テーブルTA,TBのプライバシー情報が保護されること.
- プライバシー情報が明かされる:テーブルに含まれる個人に関するプライバシー情報が推定できること.
03. 秘匿クロス統計技術
-
以下では,前述の安全性要件を満たし,企業横断での統計情報作成における ...
開く
以下では,前述の安全性要件を満たし,企業横断での統計情報作成における課題を解決する秘匿クロス統計技術について解説する.
3.1 秘匿クロス統計技術の全体構成
出力データを作成する過程のプライバシー保証の課題は,テーブルTA,TBに格納されている情報へのアクセスが可能であることで生じるため,対策として,許可されたものがアクセスできる性質である,機密性の保証が必要となる.秘匿クロス統計技術における機密性とは,データの入力から出力データが得られるまで,自企業の情報が他企業や第三者から意味ある情報(暗号化されていない平文の状態)として確認できないことを意味する.さらに,処理途中の中間データから,テーブルTA,TBに格納されている情報が復元されることも考えられるため,企業A,Bいずれも,処理が確認できない手法が求められる.また,出力データのプライバシー保証の課題は,集計テーブルに個人が特定される可能性が高いデータが残ったまま明かされることで生じるため,対策として,出力データを公開する前に,影響が出ないようにデータの削除やノイズを付加するなどの加工が考えられる.
秘匿クロス統計技術の処理の概略を図2に示す.秘匿クロス統計技術は①非識別化処理,②集計処理,③秘匿処理で構成されており,データを相互に明かすことなく,統計情報を作成できる.また,前述した安全性要件を満たすための構成技術として,セキュアマッチングプロトコル*5[5]~[8],差分プライバシー[9],隔離実行環境を用いる.
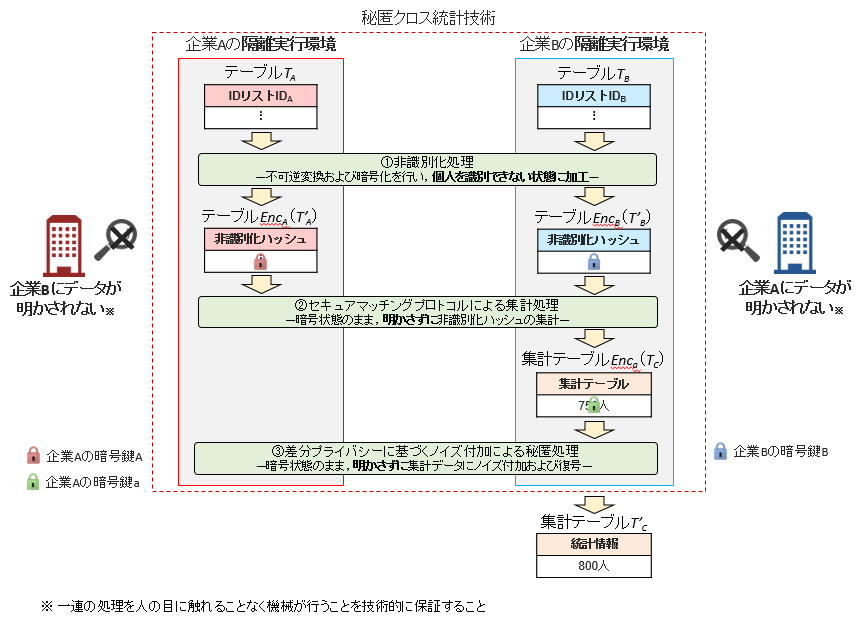
図2 秘匿クロス統計技術の全体構成
①非識別化処理
企業A,Bが共有するソルト*6(ランダムな文字列という意味)をそれぞれのテーブルTA,TBのID群に付加した上で,これらのハッシュ化*7を行い,ハッシュ値(以下,非識別化ハッシュ)に変換する処理である.なおハッシュ化を行った後にソルトを破棄することで,不可逆にIDを変換する.
②集計処理
準同型暗号技術に基づくセキュアマッチングプロトコルを利用し,暗号状態で集計テーブルを作成する.セキュアマッチングプロトコルを利用することで,企業A,Bが保有している非識別化ハッシュを相互に明かさずに,一致した非識別化ハッシュの数を暗号状態の集計テーブルとして得ることができる.非識別化処理とセキュアマッチングプロトコルによる集計処理により,出力データを作成する過程のプライバシー保証の課題で挙げた,データ連携中に自社のデータが他社に明かされることを防止する.よって,非識別化処理とセキュアマッチングプロトコルによる集計処理が正しく行われる限り,安全性要件①が満たされる.
③秘匿処理
セキュアマッチングプロトコルの出力である暗号状態の集計テーブルに差分プライバシーに基づくノイズを付加する処理である.これにより,データ連携の出力から,出力データのプライバシー保証の課題で挙げた,プライバシー情報が明かされることを防止する.よって,秘匿処理が正しく行われる限り,安全性要件②が満たされる.
なお,秘匿クロス統計技術は,非識別化処理,集計処理,秘匿処理の一連のデータ処理がいずれも正しく行われることを保証する必要がある.よってデータ処理が正しく行われることを隔離実行環境により保証する構成としている.隔離実行環境による保証については本特集別記事[2]を参照されたい.
3.2 非識別化処理
非識別化処理は,IDを再識別*8できないよう不可逆的に変換し,個人を識別できない状態に加工する処理である.非識別化処理の概略を図3に示す.以下,安全性要件を満たすため実装した処理内容の概要を解説する.
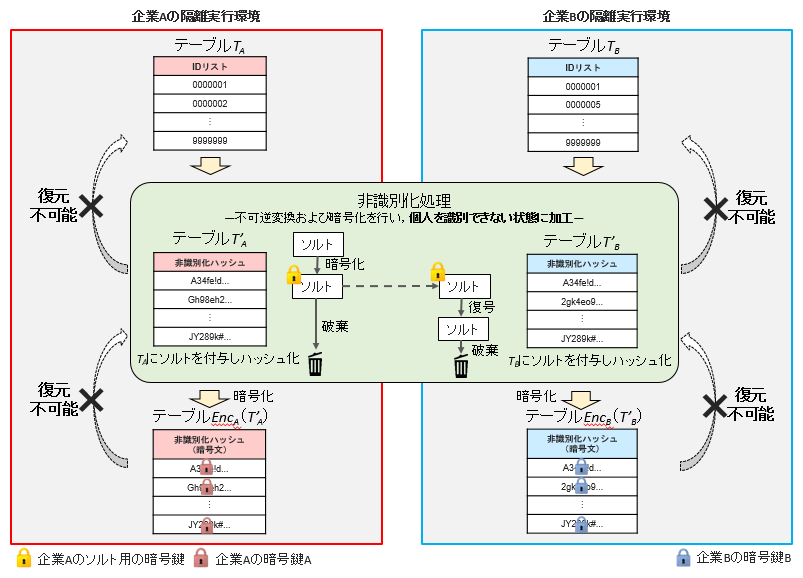
図3 非識別化処理
- 企業Aは,企業Aの隔離実行環境内でテーブルTA,TBのハッシュ化に必要なソルトを生成し,その暗号化を行う.なお,ソルトの暗号化/復号は,事前に定められた企業A,Bの隔離実行環境内でのみ実行可能な手法を用いる.
- 企業Aは,企業Bに暗号化したソルトを送付し,企業Bは企業Bの隔離実行環境内で送付されたソルトを復号する.
- 企業A,Bは,それぞれテーブルTA,TBにソルトを付与し,ハッシュ関数*9を用いて,ハッシュ化を行い,非識別化ハッシュであるテーブルT'A,T'Bを得る.
- 企業A,Bは,それぞれソルトを破棄する.
- 企業Aは,テーブルT'Aを自身の暗号鍵Aで暗号化し,EncA(T'A)を得る.同様に企業Bも,テーブルT'Bを自身の暗号鍵Bで暗号化し,EncB(T'B)を得る.ただし,EncX(T)はテーブルTを暗号鍵Xで暗号化したものとする.
④のソルトの破棄について補足すると,企業Aもしくは企業Bがハッシュ化で用いたソルトおよびハッシュ関数を再利用可能である場合,非識別化ハッシュとIDの対応が再識別される可能性がある.例えば,IDの形式(電話番号であれば数字11桁)が既知であれば,再利用したソルトを用いてすべてのIDのハッシュ値を計算する総当り攻撃*10が成功し得る.そのため,IDから非識別ハッシュへの変換を不可逆なものとするためには,ソルトが再利用できないよう破棄することが必要である.
秘匿クロス統計技術では,非識別化処理を含む処理全体を隔離実行環境に実装し,処理の完全性を保証することで,④の処理の改ざんを防ぐ.例えば,ソルトを破棄しない処理に改ざんされることを防ぎ,ソルトの再利用を防ぐことができる.
また,⑤においても,隔離実行環境で処理が行われるため,処理の改ざんを防ぐ.例えば,企業Aが暗号鍵Aを用いた,テーブルEncA(T'A)からテーブルT'Aへの復元をはじめとする想定していない処理を防ぐことができる(企業Bも同様).
3.3 セキュアマッチングプロトコルによる集計処理
集計処理は,暗号状態でテーブルEncA(T'A), EncB(T'B)の一致した非識別化ハッシュの個数を集計する処理である.秘匿クロス統計技術では,集計処理にセキュアマッチングプロトコルと呼ばれる手法を利用している.セキュアマッチングプロトコルは,データを暗号化したまま処理できる準同型暗号技術に基づいたプロトコルであり,複数の主体が各々もつ非識別化ハッシュを互いに明かさずに,集計処理を可能にする.
セキュアマッチングプロトコルによる集計処理の概略を図4に示す.以下,安全性要件を満たすために実装した処理内容の概要を解説する.詳細な処理は文献[6]を参照されたい.
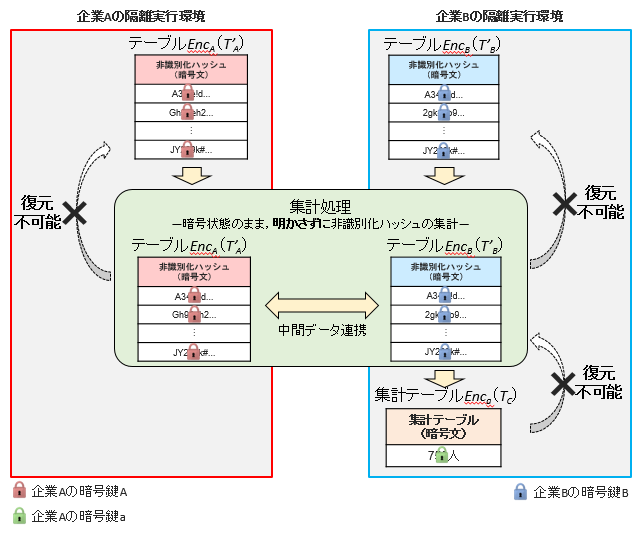
図4 集計処理
企業Aは非識別化処理で得たEncA(T'A)を企業Bに送る.同様に企業BもEncB(T'B)を企業Aに送る.ここで,企業Aから企業Bに送付されるEncA(T'A)には,企業BへテーブルTAのレコード数の公開を防ぐために,ダミーの非識別化ハッシュが含まれる.
企業AはEncB(T'B)を自身の暗号鍵Aで暗号化することで,EncAEncB(T'B)を作り,企業Bに送る.同様に企業BもEncA(T'A)を自身の暗号鍵Bで暗号化することで,EncBEncA(T'A)を作り,企業Aに送る.
企業AはEncBEncA(T'A)の非識別化ハッシュに,企業Aの暗号鍵aで暗号化した1を,ほかにあり得るダミーの非識別化ハッシュに,暗号鍵aで暗号化した0を紐づけたEncBEncA(T'A|D)を作り,企業Bに送る.
企業BはテーブルEncBEncA(T'A|D)からEncAEncB(T'B)の非識別化ハッシュに紐づけられた暗号文を集計し,企業Aの暗号鍵aで暗号化されたEnca(TC)を得る.
なお,T'Aは企業Aの暗号鍵A,企業Bの暗号鍵Bの順で,T'Bは企業Bの暗号鍵B,企業Aの暗号鍵Aの順で,暗号化されているが,セキュアマッチングプロトコルでは,暗号化の順番が異なっても,一致を確認できる.さらに,暗号鍵aは準同型暗号で用いられる暗号鍵であるため,データの中身を明かすことなく,Enca(TC)を得ることができる.
3.4 差分プライバシーに基づくノイズ付加による秘匿処理
秘匿処理は,出力結果からのプライバシー情報を保護する処理である.秘匿クロス統計技術では出力結果の安全性を保証するため,セキュアマッチングプロトコルによる集計で得た暗号状態の集計テーブルEnca(TC)に対して,差分プライバシーに基づくノイズ付加を行う.差分プライバシーとは,特定の背景知識や攻撃能力をもつ攻撃者に対しても安全性を保証できることを目的として作成された,プライバシー保護の強度を定量的に測る指標である[10].出力データのプライバシー保証をするために,集計テーブルEnca(TC)が公開される前に,暗号状態のままノイズ付加を行うことが必要であり,その状態で差分プライバシーを達成する手法がいくつか研究されている[11]~[13].これらのうち秘匿クロス統計技術では紀伊のプロトコル[12]を利用した.秘匿処理の概略を図5に示す.企業Bが集計テーブルEnca(TC)に対して,差分プライバシーに基づくノイズ付加による秘匿処理を施した後に,企業Aがそれを復号し,秘匿処理済み集計テーブルT’Cを得る.これらの処理の詳細は文献[12]を参照されたい.
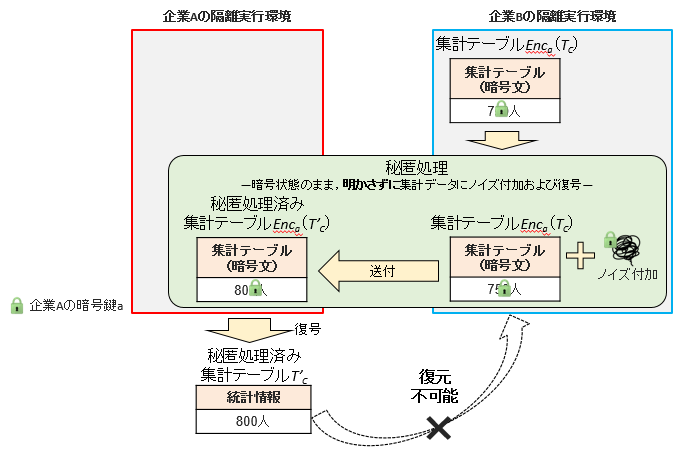
図5 秘匿処理
3.5 秘匿クロス統計技術の各処理の完全性保証
秘匿クロス統計技術を構成する技術とデータ処理は前述したとおりであり,一連の処理が正しく実行される限りにおいて,安全性要件①,②を満たす.ただし,一連の処理が正しく実行されるというプロトコルの完全性を技術的に保証する必要がある.
一連の処理が正しく実行されなかった場合において,生じ得る脅威の例をあげる.1つ目に非識別化処理を改ざんし,ソルトを取得するユーザがいる場合,総当り攻撃によるIDとハッシュ値の再識別が発生する可能性がある.2つ目に,秘匿処理を改ざんし,適切なノイズが付与されない場合,出力の集計テーブルからプライバシー情報が明かされる懸念がある.
このような脅威への対策を行うための,隔離実行環境を用いたプログラムの完全性*11の保証については,本特集別記事[2]において解説する.
- セキュアマッチングプロトコル:データを暗号化したまま処理できる暗号方式(準同型暗号)を応用し,複数の主体が各々もつデータを互いに明かすことなく,データ結合処理と統計情報の作成を行う技術.
- ソルト:データをハッシュ化(*7参照)する際に,ハッシュ関数の入力に加えるランダムなデータ.
- ハッシュ化:ハッシュ関数により元データからハッシュ値を計算すること.なお,ハッシュ化後に,ハッシュ化する際に用いたソルトを破棄するため,ハッシュ値から元のデータを算出することは不可能である.
- 再識別:加工したデータをもともとのデータ(個人情報など)と照合すること.
- ハッシュ関数:出力された文字列からは,入力された文字列を得ることが不可能という特性をもつ一方向関数の一種.任意の長さの文字列を固定長の文字列(ハッシュ値)に変換する関数であり,同一の入力に対しては,対応する同一の文字列が出力される特性をもつ.
- 総当り攻撃:暗号の解読やパスワードの割出しで用いられる手法で,解読した秘密情報の考えられるすべてのパターンを入力することで解読する手法.ブルートフォース攻撃とも呼ばれる.
- 完全性:ソフトウェアやデータが改ざんされていない性質.
04. あとがき
-
本稿では,企業を横断した統計的データ活用を実現するため,データ活用に ...
開く
本稿では,企業を横断した統計的データ活用を実現するため,データ活用における課題を示し,満たすべき安全性要件を整理した.さらに,ドコモが開発した秘匿クロス統計技術について解説し,この技術が安全性要件を満たすことを示した.
具体的には,出力データを作成する過程のプライバシー保証の課題について,IDを不可逆的に変換した後,一連の処理過程をすべて暗号化した状態で実行することで解決を図り,安全性要件①が満たされることを述べた.さらに,出力データのプライバシー保証の課題に対して,暗号状態の集計テーブルに差分プライバシーに基づくノイズ付加による秘匿処理を行うことで解決を図り,安全性要件②が満たされることを述べた.秘匿クロス統計技術は,非識別化処理,セキュアマッチングプロトコルによる集計処理,差分プライバシーに基づくノイズ付加による秘匿処理を隔離実行環境において適切に組み合わせることで,安全性要件を満たす企業横断の統計的データ活用を実現している.今後はパートナー企業と,実データを用いて,秘匿クロス統計技術の有用性を示し,実用化をめざす.
-
文献
開く
- [1] 野澤,ほか:“企業横断の統計的なデータ活用による社会課題の解決―秘匿クロス統計技術の概要―,”本誌, Vol.31, No.1, Apr. 2023.
- [2] 長谷川,ほか:“秘匿クロス統計技術の完全性保証方法の設計と実装,”本誌, Vol.31, No.1, Apr. 2023.
- [3] 千田 浩司,紀伊 真昇,市川 敦謙,野澤 一真,長谷川 慶太,堂面 拓也,中川 智尋,青野 博,寺田 雅之:“パーソナルデータの等結合に適した匿名化技術の考察,”2022-SCIS,2022.
- [4] 寺田 雅之:“差分プライバシーとは何か,”システム/制御/情報,Vol.63,No.2,pp.58-63,2019.
- [5] R. Agrawal, A. Evfimievski and R. Srikant:“Information sharing across private databases,”SIG- MOD 2003, ACM, pp.86–97, 2003.
- [6] P. Buddhavarapu, A. Knox, P. Mohassel, S. Sengupta, E. Taubeneck and V. Vlaskin:“Private matching for compute,”Cryptology ePrint Archive, Paper 2020/599,2020.
- [7] 千田 浩司,寺田 雅之,山口 高康,五十嵐 大,濱田 浩気,高橋 克巳:“統計的開示制御を考慮したセキュアマッチングプロトコル,”情報処理学会研究報告,Vol.2011- CSEC-52,No.12,pp.1-6,Mar. 2011.
- [8] K. Chida, K. Hamada, A. Ichikawa, M. Kii and J. Tomida:“Private Intersection-Weighted-Sum,”Cryptology ePrint Archive, Paper 2022/338,2022.
- [9] C.Dwork:“Differential Privacy,”Proc. of 33rd Intl. Conf. Automata, Languages and Programming-Volume PartⅡ,Vol.4052,pp.1-12,2016.
- [10] 寺田 雅之:“差分プライバシーとは何か,”システム/制御/情報,Vol.63,No.2,pp.58-63,2019.
- [11] 紀伊 真昇,市川 篤紀,千田 浩司,濱田 浩気:“差分プライベートな秘密計算のための暗号化された離散乱数を生成する非対話型二者間プロトコル,” 情報処理学会研究報告,Vol.2021-CSEC-92,No.5,Mar. 2021.
- [12] 紀伊 真昇:“小さいテーブルを用いる差分プライバシーのためのセキュアサンプリング,” CSS2022,pp.137-144,Oct. 2022.
- [13] 牛山 翔二郎,髙橋 翼,工藤 雅士,井上 紘太朗,鈴木 拓也,山名 早人:“完全準同型暗号下での差分プライバシ適用―レンジクエリを対象として―,” DEIM Forum 2021 G25-4z,2021.

