

AIエージェントの実現を支えるマルチモーダルDX基盤
- #データ/AI活用
- #LLM
加藤 拓(かとう たく)
斉藤 優樹(さいとう ゆうき)
山縣 将貴(やまがた まさき)
鳥羽 真仁(とば まさひと)
サービスイノベーション部
あらまし
大規模言語モデル(LLM)の進化により,AIエージェントの実現が現実的になっている.しかし,会議や接客といった音声コミュニケーションの現場でAIエージェントが適切に行動するには,音声だけでなく,映像やテキストなども対象とした多角的な情報分析も不可欠である.ドコモではこれまで,音声データ分析を担う「音声DX基盤」を開発してきたが,このたびマルチモーダル分析の強化のため,「音声DX基盤」から「マルチモーダルDX基盤」への拡張を進めている.本基盤を活用し,音声コミュニケーションにおける会話内容から場の雰囲気まで的確に把握できる,次世代AIエージェントの実現をめざす.
01. まえがき
近年,大規模言語モデル(LLM:Large Language Model)*1は急速に進化を遂げ,その応用範囲は日々拡大している.この進化はAIエージェント*2の実現を可能にし,多くの企業で業務プロセスの改善や顧客体験の向上を目的としたAIエージェントの開発や導入の検討が進められている.特に,会議や接客,営業などの音声コミュニケーションの場におけるAIエージェントの活用は,デジタルトランスフォーメーション(DX:Digital Transformation)*3の推進や,顧客との対話を通じた体験価値の向上に繋がるものとして,大きな期待が寄せられている.
AIエージェントが音声コミュニケーションの場で適切に判断・行動するためには,コミュニケーションの内容を正確に把握することが不可欠である.しかしながら,音声から得られる情報だけでは,内容の完全な把握ができない可能性がある.一方,人間は音声だけでなく,投影されている資料や,関連する手元の資料,相手の表情など,複数のモーダル*4から得た情報を総合的に把握した上で,コミュニケーションをとることが多い.AIエージェントが人間らしく振る舞うためには,音声に加えて映像やテキストといった多様な情報を活用することが重要であると考えられる.
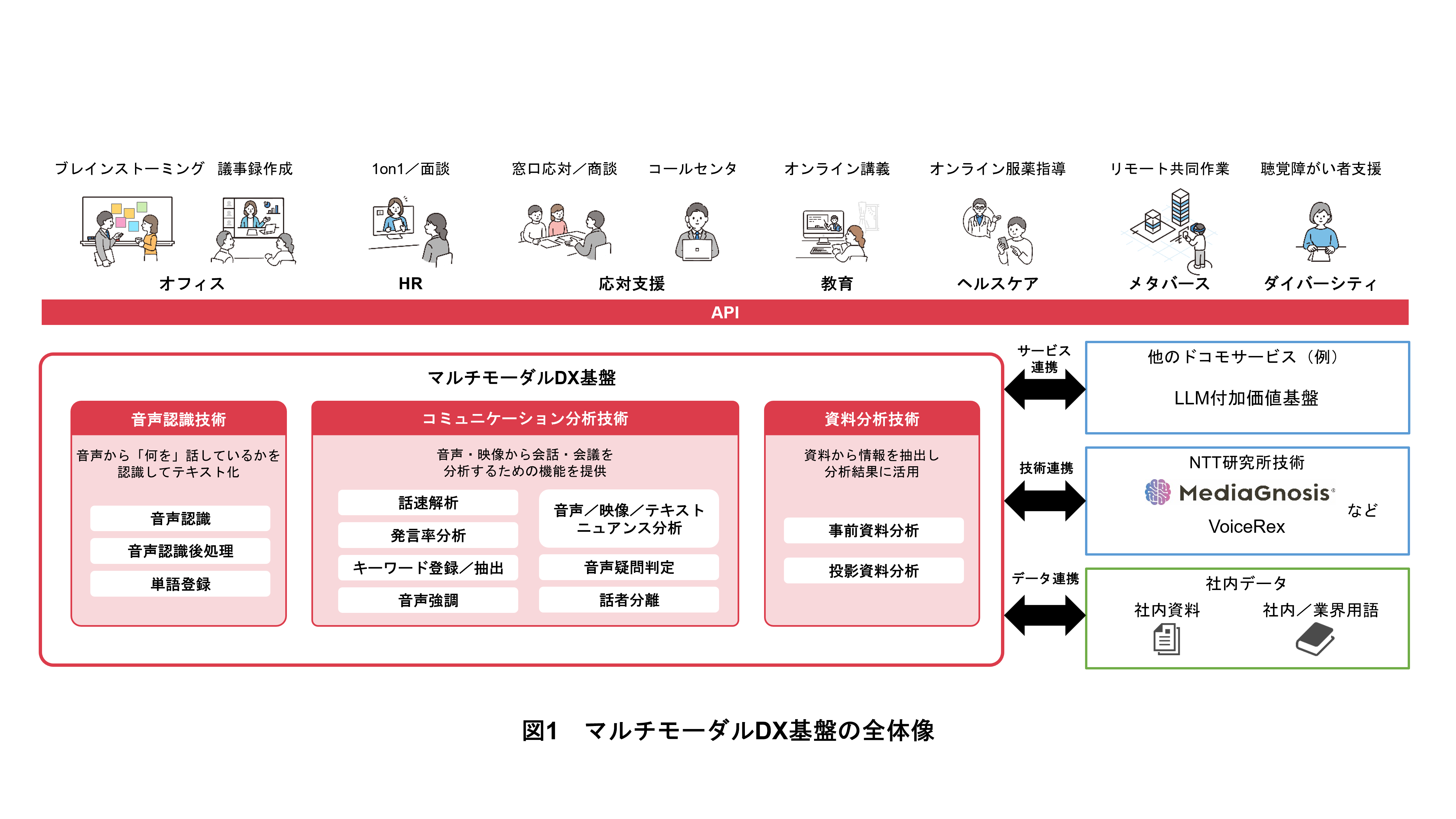
ドコモではこれまで,音声データからテキスト,ニュアンス,話し方の特徴などを多角的に分析する「音声DX基盤」[1]の開発に取り組んできたが,AIエージェントの実現に向けては,音声分析を中心としたアセット*5を集約した音声DX基盤から,映像やテキストなどのマルチモーダル*6分析を強化した「マルチモーダルDX基盤」への拡張を進めている(図1).
本基盤では,音声DX基盤がもっていた「分析AIアセットの集約によるインタフェースの共通化」という特長を踏襲しつつ,「豊富な分析AIアセットのラインナップ」という特長が強化されている.これにより,さらに多くのマルチモーダルな分析アセットを,共通のインタフェースで手軽に利用可能となった.また,マルチモーダル分析技術への拡張により,社内資料などとの連携も可能になったことで,各企業の独自の社内データと掛け合わせた分析も実現できる.以上の特長を備えるマルチモーダルDX基盤の活用により,会話内容や様子を正確に理解したAIエージェントの構築が可能となる.
本稿では,マルチモーダルDX基盤の概要および,搭載されている技術,そしてその具体的な活用例について解説する.
- 大規模言語モデル(LLM):大量のテキストデータで学習させた,高度な文書生成や言語理解が可能な自然言語処理のモデルのこと.
- AIエージェント:ユーザの指示や状況を理解し,自律的に複雑なタスクを実行できる人工知能のこと.
- デジタルトランスフォーメーション(DX):IT技術を活用してサービスやビジネスモデルを変革し,事業を促進するとともに人々の生活をあらゆる面で良い方向に変化させること.
- モーダル:音声,テキスト,画像,映像といった,情報の種類や形式.
- アセット:技術資産のこと.
- マルチモーダル:複数の種類の情報を掛け合わせること.ここでは,音声データや画像データなどの複数のメディアデータを入力情報として扱うことを指す.
02. マルチモーダルDX基盤の概要
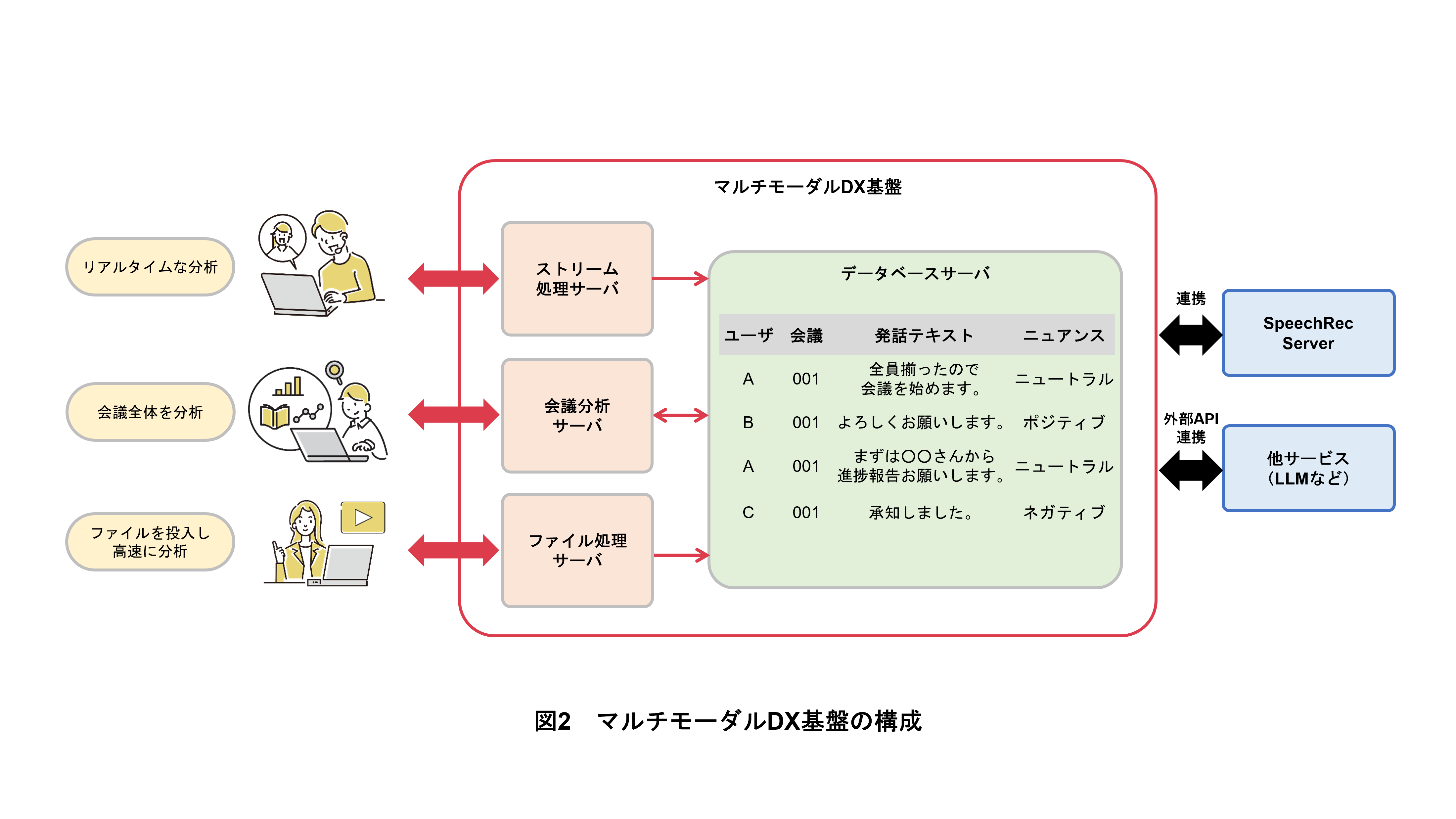
マルチモーダルDX基盤の構成概要を図2に示す.本基盤は,本誌過去記事[1]で解説した,リアルタイム分析を行う「ストリーム処理サーバ」と,複数発話をまとめて分析する「会議分析サーバ」に,今回新たに高速なファイル処理を実現する「ファイル処理サーバ」を追加したものである.
また,従来の音声中心の分析からマルチモーダル分析への拡張のため,NTT研究所が開発した「次世代メディア処理AI『MediaGnosis®』」[2]~[7]の技術を搭載したサーバである「SpeechRec Server」[8]とも接続できるようにした.従来の音声DX基盤では,MediaGnosisの新機能を利用する際には,基盤内の追加開発が必要であった.SpeechRec Serverとの接続により,本基盤内の開発を最低限に抑えながら, MediaGnosisがもつ多様なマルチモーダル分析技術が本基盤から利用可能となった.
さらに,本基盤は外部API(Application Programming Interface)連携*7が柔軟に行えるため,基盤内の各アセットと各種APIとを掛け合わせた分析も可能となった.例えば,LLMと接続することで,本基盤による音声分析の結果に対する追加分析も実現できる.また,マルチモーダルLLM*8と接続することで,動画像データに対する分析能力をさらに強化できる.MediaGnosisの高精度な特化型と汎用性の高いマルチモーダルLLMを組み合わせることで,さらに多角的かつ高精度な分析を実現できる.
マルチモーダルDX基盤では多くの機能が利用できるが,サービスごとに求められる機能は異なる.本基盤では,利用する機能のみをサーバの設定により選択できるため,サービスごとに必要最低限のリソースで運用できる.加えて,クライアントの設定においても,サーバ側で稼働している機能の中から取得したい結果を任意で選択できる.本基盤はユーザの用途に合わせて必要な結果のみを返却するため,例えば「音声認識結果を取得したいユーザ」と,「音声認識結果に加えて音声ニュアンス分析の結果も取得したいユーザ」に対し,単一の基盤でサービス展開が可能である.
- 外部API連携:あらかじめ定義したインタフェースを介し,別システムや別サービスの異なるプログラムやソフトウェアが連携すること.
- マルチモーダルLLM:音声や動画など複数のメディアデータの入出力に対応した大規模言語モデルのこと.
03. マルチモーダル分析アセット
3.1 分析アセットの概要
マルチモーダルDX基盤に搭載されている分析アセットは,NTT研究所の最新技術[2]~[7][9]をベースに,ドコモ独自の技術を組み合わせて実現されている(図1).
・音声分析アセットとして,発話内容をテキスト化する「音声認識」,声のトーンからニュアンスなどの非言語情報*9を推定する「音声ニュアンス分析」,疑問調の話し方かを推定する「音声疑問判定」,話す速度を判定する「話速解析」,複数人の会話で話者を分離する「話者分離」,人の発話箇所を強調する「音声強調」などを利用できる.
・テキスト分析アセットとして,あらかじめ登録した単語の発話を検出する「キーワード抽出」や,テキスト内容に対するポジティブ/ネガティブ/ニュートラルを判定する「テキストニュアンス分析」を利用できる.
・動画像分析アセットとして,音声と表情からニュアンスを推定する「映像ニュアンス分析」や,資料からさまざまな情報を抽出する「資料分析」を利用できる.
また,上記以外にもSpeechRec Serverで利用可能なMediaGnosisの機能があり[2][3],これらも本基盤経由で順次利用できるように開発を進めている.
これらのアセットはストリーム処理サーバとファイル処理サーバで利用できる.一方,会議分析サーバでは,ユーザIDや会議IDを管理することで,ユーザ別,会議別の分析を可能とする.具体的には,ストリーム処理サーバやファイル処理サーバで実行された各アセットの分析結果の取得に加えて,会議におけるユーザごとの発言比率を計算する「発言率分析」や,キーワード抽出に対する「キーワード登録」,音声認識に対する「単語登録」も提供している.この単語登録機能を活用することで,企業や業界特有の用語,人物名などに対する音声認識精度が向上する.
ここでは本基盤で新規に追加された「音声強調」と「資料分析」について詳述する.音声DX基盤で利用していた従来の技術の詳細は,文献[1]を参照されたい.
3.2 音声強調
「音声強調」は,入力音の中から人の発話部分を強調する技術であり,NTT研究所の音声認識技術[9]を用いて実現している.この技術で強調した音声を,他の音声分析アセットに入力することで,雑音環境下などにおいても各分析技術がより頑健に動作することが期待できる.
3.3 資料分析
「資料分析」は,LLMを用いて社内資料からさまざまな情報を抽出するための技術である.本技術の活用により,資料情報を参照した音声認識の誤り訂正や,資料内容を含む詳細な要約文の作成が期待できる.また,複数の資料から社内用語・専門用語を横断的に抽出し,その説明文を作成することで,社内ナレッジデータベース構築の自動化にも活用できる.
資料情報の参照方法には大きく2パターン存在する(図3).第1は,PDFをはじめとした資料ファイルを直接読み取って分析する「事前資料分析」である.第2は,会議中の投影画面を読み取って分析する「投影資料分析」である.これらの手法によって,さまざまな状況下で資料を活用できる.
「事前資料分析」とは,資料ファイルから直接テキスト・図表情報を抽出し,LLMを用いて分析を行う技術である.単一ファイルのみならず,複数ファイルを横断して分析することで,資料間の関連性を考慮して知識資産を有効活用することができる.
「投影資料分析」とは,動画像入力に対応したマルチモーダルLLMを用いて,会議中に投影された画面上の資料を分析する技術である.会議の動画ファイルや進行中の会議の画面を入力とした資料分析を行うため,資料ファイルの事前投入が不要となる.さらに,他機能との連携により音声認識結果の修正や資料内の用語解説などを,会議参加者へリアルタイムで提供できるという利点がある.

- 非言語情報:声色や表情といった言語以外のコミュニケーションにおける相手への伝達情報のこと.
04. マルチモーダルDX基盤の活用例
4.1 議事録作成支援ツール
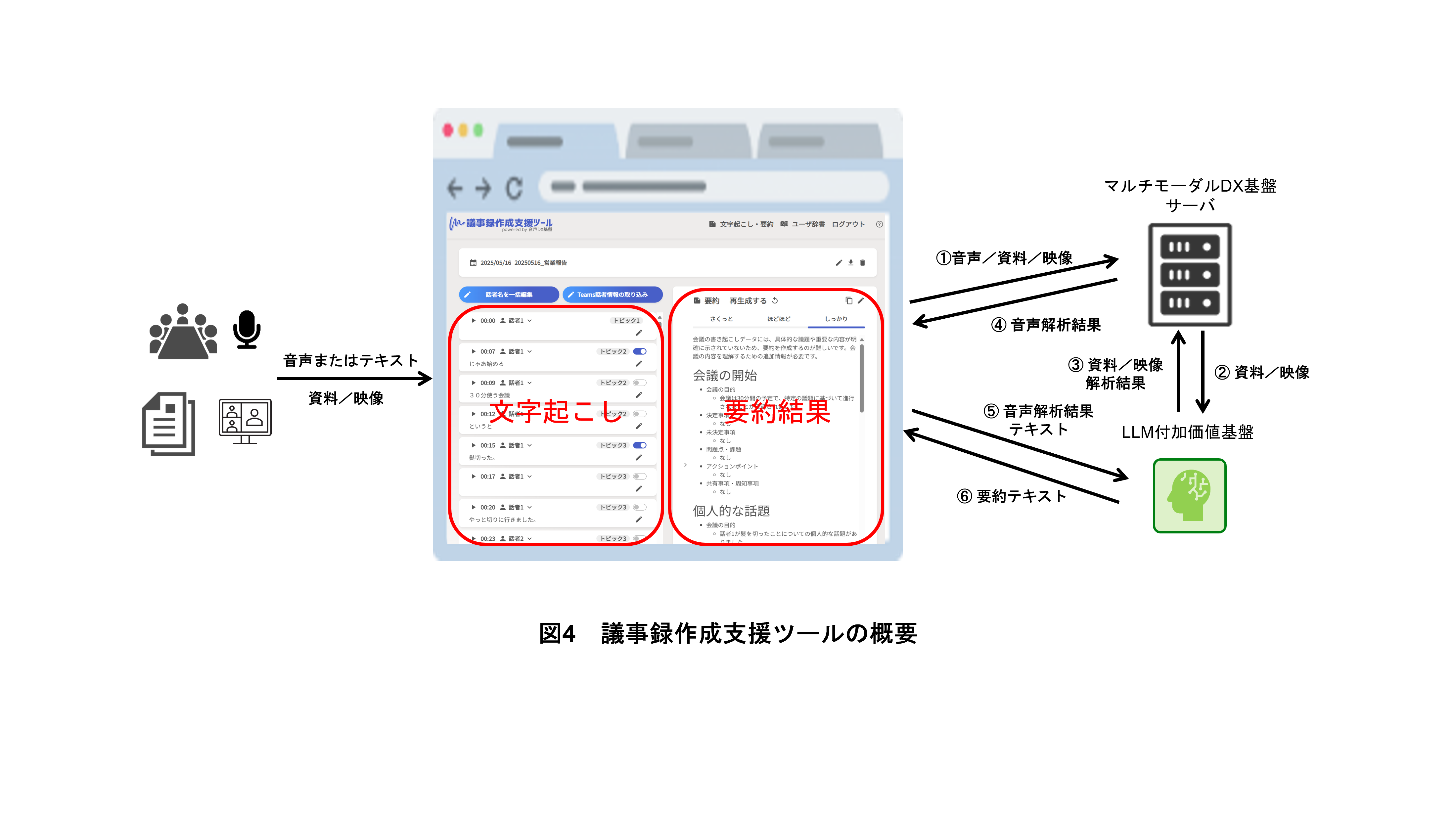
ドコモでは,会議の効率化を支援する「議事録作成支援ツール」を展開している(図4).本ツールでは,マルチモーダルDX基盤が担う音声認識や話者分離と,LLM付加価値基盤[10]が担う要約処理が連携することで,会議内容の自動テキスト化・要約を,会議の進行に合わせリアルタイムに実現できる.さらに,今回拡張された「資料分析」技術を用いることで,音声だけでなく資料や映像など多様な情報を統合的に解析し,より高精度な音声認識結果(文字起こし)と質の高い要約を提示できる.
4.2 会議支援エージェント
マルチモーダルDX基盤を活用したAIエージェントの例として,ドコモでは「会議支援エージェント」の構築に取り組んでいる.これは,人間と協調しながら円滑な会議進行に貢献するAIエージェントであり,会議のDXをより一層促進するものである.例えば,会議内容に基づいた最適なアドバイスや,自律的に収集した社内情報の会議参加者への提示,上司を代理するAIエージェントとの壁打ちなどが挙げられる.会議支援エージェントは,マルチモーダルDX基盤を用いて,各話者の会話内容をリアルタイムに把握することできるため,会議参加者へのリアルタイムな支援が可能となっている.
この取組みについては,本特集別記事にて詳細を紹介する[11].
05. あとがき
本稿では,ドコモが開発を進めるマルチモーダル分析AIアセットを集約した「マルチモーダルDX基盤」について,その特長と活用例を解説した.本基盤は,多彩なマルチモーダル分析アセットを共通のインタフェースで利用でき,さらに社内データを組み合わせた分析も可能なため,音声コミュニケーションの場において社内の情報を理解した振舞いが可能なAIエージェントを実現することができる.
今後は,分析アセットをさらに多様なものへと拡張するとともに,各機能を組み合わせることで,より高度な分析を実現し,AIエージェントによる音声コミュニケーションの場でのDXや,顧客体験価値の向上に貢献していく.
文献
- [1] 千葉,ほか:“音声DX基盤が拓く音声データの活用,”本誌,Vol.32,No.1,Apr. 2024.https://www.docomo.ne.jp/corporate/technology/rd/technical_journal/bn/vol32_1/003.html
- [2] NTT:“次世代メディア処理AI「MediaGnosis®」によるマルチモーダルWebアプリケーションを一般公開開始, ”Nov. 2022.https://group.ntt/jp/topics/2022/11/16/rd_mediagnosis_demo.html

- [3] NTT研究開発:“MediaGnosis®次世代メディア処理AI. ”https://www.rd.ntt/mediagnosis/
- [4] N. Makishima, K. Suzuki, S. Suzuki, A. Ando and R. Masumura:“Joint Autoregressive Modeling of End-to-End Multi-Talker Overlapped Speech Recognition and Utterance-level Timestamp Prediction,”In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH 2023), pp.2913-2917, Aug. 2023.
- [5] A. Takashima, R. Masumura, A. Ando, Y. Yamazaki, M. Uchida and S. Orihashi:“Interactive Co-Learning with Cross-Modal Transformer for Audio-Visual Emotion Recognition,”In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH 2022), pp.4740-4744, Sep. 2022.
- [6] N. Makishima, N. Kawata, M. Ihori, T. Tanaka, S. Orihashi, A. Ando and R. Masumura:“SOMSRED: Sequential Output Modeling for Joint Multi-talker Overlapped Speech Recognition and Speaker Diarization,”In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH 2024), pp.1660-1664, Sep. 2024.
- [7] R. Masumura, A. Takashima, S. Suzuki and S. Orihashi:“Born-Again Multi-task Self-training for Multi-task Facial Emotion Recognition,”In Proc. International Conference on Pattern Recognition (ICPR), pp.94-108, Dec. 2024.
- [8] NTTテクノクロス:“SpeechRec Server.”https://www.ntt-tx.co.jp/products/speechrec/server/
- [9] YouTube:“スマートウォッチでも常時動作する超軽量リアルタイム音声認識技術,” NTT official channel,Apr. 2023.https://www.youtube.com/watch?v=WkfMblJ4QpI
- [10] 駒田,ほか:“ビジネスの現場に寄り添うLLM基盤技術,”本誌,Vol.32,No.1,Apr. 2024.https://www.docomo.ne.jp/corporate/technology/rd/technical_journal/bn/vol32_1/001.html
- [11] 高島,ほか:“会議コミュニケーションを支援するリアルタイムエージェントシステム,”本誌,Vol.33,No.4,Jan. 2026.https://www.docomo.ne.jp/corporate/technology/rd/technical_journal/bn/vol33_4/005.html


