

データ分析業務効率化のためのマルチAIエージェントシステムの開発
- #データ/AI活用
- #LLM
何 朗平(か ろうへい)
川口 貴子(かわぐち たかこ)
住吉 毅(すみよし つよし)
稲子 明里(いなご あかり)
阿部 竜弥(あべ たつや)
サービスイノベーション部
あらまし
近年,非専門家でも高度なデータ分析を行えることが求められている状況において,大規模組織では人事異動による分析ノウハウの断絶や,既存BIツールの操作負荷・品質のばらつきが課題となっていた.営業データなどの企業内データの分析は,従来,一部の高スキル者や熟練者に依存してきた.しかし,生成AIの普及に伴い,低スキル者やデータ分析の経験がない初学者でもデータ分析が可能となりつつある.
ドコモでは,ユーザの分析要望に応じて過去の分析履歴を参照し,最適なワークフローを数秒で自動選択し,分析プラン決定・データ探索・考察を担うマルチAIエージェントを開発した.これにより,分析プロセスを効率化し,分析の均質性を確保するとともに,工数削減と多分野への展開を可能にした.
01.まえがき
市場動向を把握する上でデータ分析は非常に有効な手法である.例えば,ある販売店で売上げが減少したとき,前月や過去の販売データを今月の販売データと比較し,その期間に実施された販促施策や市場全体の動向のデータと合わせ総合的に分析・比較することで,売上げ減少の具体的な要因を深く知ることができる.また,減少した要因が分かれば来月の販売戦略を考えることが可能となる.
しかし,従来の分析業務は個人のスキルに依存するところが大きく,経験の浅い担当者は分析ノウハウが少ない.また,BI(Business Intelligence)ツール*1の操作に不慣れであることなどから,目的の分析を実施するまでに多くの時間と労力を費やしている.加えて,大規模なデータベースから,必要なデータを抽出して分析に用いるにはSQL(Structured Query Language)*2の作成が必要であるが,SQL構文およびデータベース構造に関する専門的な知識が求められるため,特定の担当者に業務が属人化しやすいという課題がある.これにより,担当者の不在時に作業が停滞する,離職時にノウハウが失われ後任者の育成に時間がかかるなど,作業時間が増加するリスクが考えられる.
ドコモは,これらの問題解決を目的として,AIエージェント*3を複数用いた「データ分析エージェントシステム」を開発した.本システムはマルチエージェントシステムを採用しており,司令塔となるエージェントがユーザからの自然言語*4による指示を解釈し,その指示に基づき,「データ取得」「可視化・考察」といった各タスクに特化した複数の専門エージェントと自律的に連携し,一連の分析プロセスを実行して分析結果を得る.これにより,ユーザは分析業務にかかる時間的・労力的な負担を大幅に軽減できるだけでなく,専門的なスキルをもつ担当者に依存しがちであった業務の属人化を解消し,組織全体の分析能力向上にも貢献することができる.
本稿では,データ分析エージェントのシステム概要とそれを構成する各AIエージェントの動作,それらと連携する機能群サーバについて解説し,また,本システムを評価した結果について報告する.
- BIツール:企業内外に存在する多様なデータを収集・統合し,集計・可視化・分析を行うためのソフトウェア.
- SQL:データベースの定義や操作を行うための代表的な言語.データの抽出・追加・更新などに用いられる.
- AIエージェント:与えられた目的を達成するため,自ら状況を判断し,一連のタスクを自律的に実行するAI.
- 自然言語:人々が日常的に会話や文章で使う言語のこと.
02. システム詳細
2.1 エージェントの概要
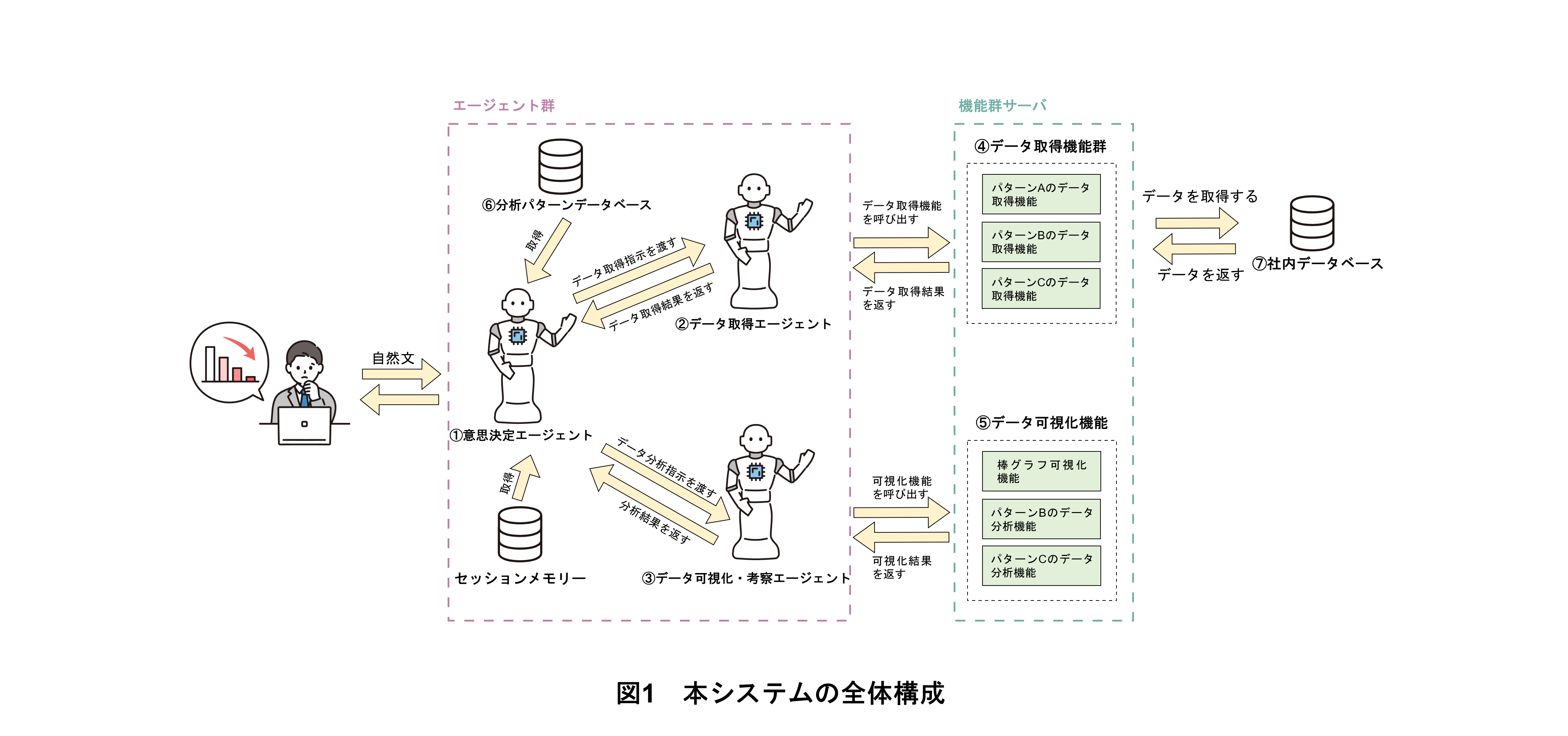
本システムの全体構成を図1に示す.それぞれ異なる役割を担うマルチAIエージェント*5が協調的に動作し,機能群サーバを自律的に利用するため,ユーザは自然文*6で分析要望を入力するだけで,一連のデータ取得・可視化・考察を効率的に実行できる.
本システムは以下の7つの要素から構成される.
①意思決定エージェント:ユーザ要望を認識し,処理フロー全体を制御する
②データ取得エージェント:社内データベースから必要なデータを取得する
③データ可視化・考察エージェント:取得データを可視化し,考察を行う
④データ取得機能群サーバ:データ取得のための機能群を提供する
⑤データ可視化機能群サーバ:グラフ生成機能を提供する
⑥分析パターンデータベース:過去の分析要望と適用した分析手法のセットを保存する
⑦社内データベース:分析対象となるデータを保存する
各要素の詳細な動作については以下で述べる.
2.2 意思決定エージェント
(1)機 能
意思決定エージェントの役割は,ユーザが自然文で入力するデータ分析要望を適切に認識し,以降の2つのサブエージェント*7であるデータ取得エージェントとデータ可視化・考察エージェントを呼び出すためのフローを制御することである.具体的な機能としては,①分析フローの制御と②分析パターン判定,③分析パラメータの抽出の3つがある.意思決定エージェントは,データ取得,可視化・考察を行うと判断した際に各サブエージェントを機能の代わりに呼び出す.
①分析フローの制御とは,入力された自然文から,ユーザが新たに社内データを取得して可視化・考察を実施するのか,エージェントとすでに実施したやり取りで取得したデータに対して再考察だけ実施するのかを判断・実行する機能である.
②分析パターン判定とは,頻繁に使う分析要望と手法をセットで事前に分析担当者からヒアリングし,パターン化できたものを分析パターンデータベースに保持しておき,データ取得・考察要望が分析パターンデータベース中のどのパターンに当てはまるのかを判定する機能である.この機能により,過去の分析事例から適切な分析手法を状況に応じて選択することができ,正当な分析が可能となる.さらに,分析パターンが決定されると,選択可能なデータテーブルや可視化した際のグラフの軸などのパラメータ一覧を取得することができる.
③分析パラメータの抽出とは,データ取得や可視化する際に必要となる,取得したいデータのフィルタリング条件などを,入力された自然文から抽出する機能である.分析パターン判定により取得できた選択可能なパラメータ一覧の中から,入力文に応じて具体的な値を決定する.さらに,ユーザが要望として具体的なデータの条件を指定していない場合には,事前に定めておいたデフォルト値を代入する.
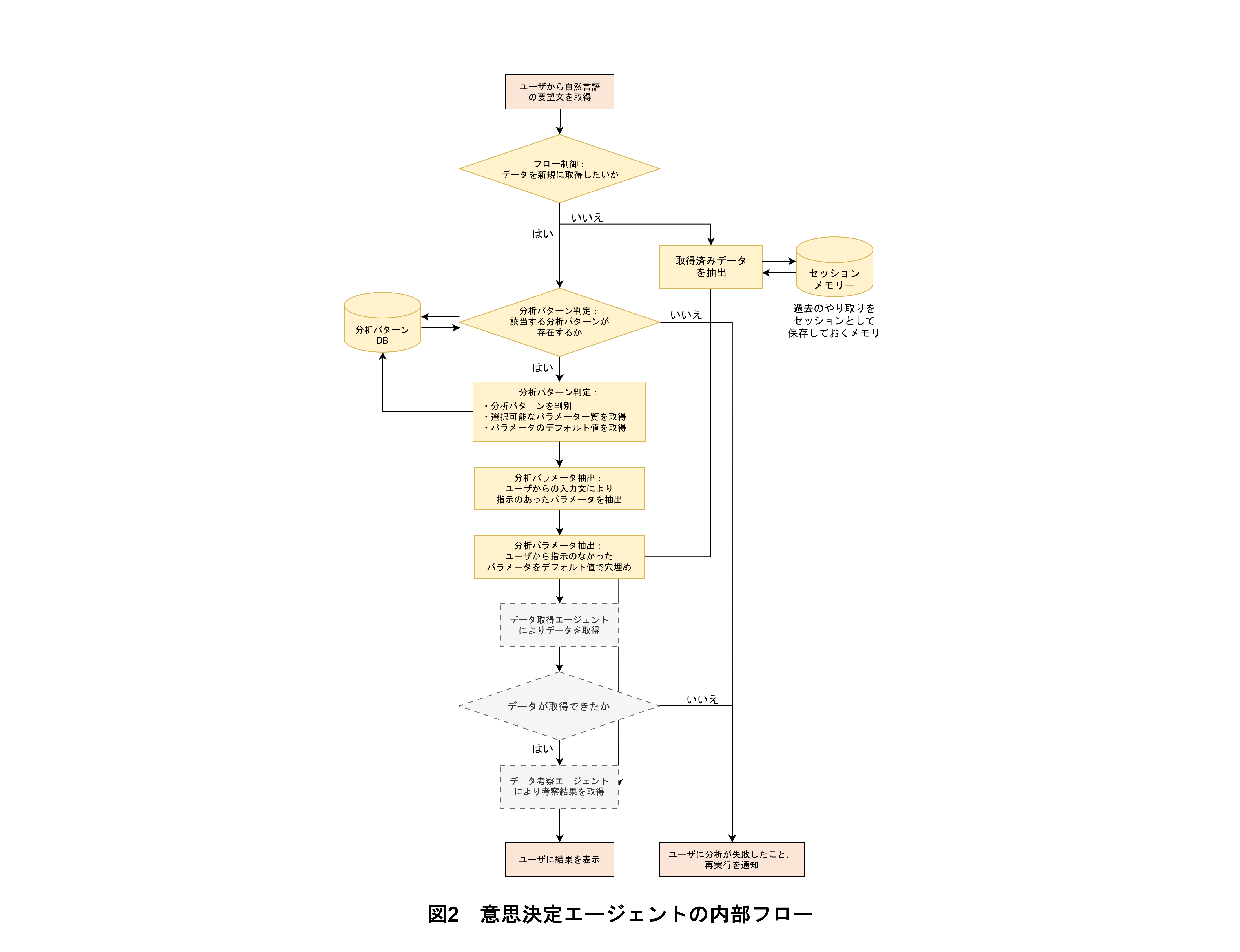
(2)分析の流れ
図2に意思決定エージェントの内部フローを示す.意思決定エージェントは,まずユーザからの自然文入力に基づき,既存のデータから再考察のみを行うのか,新たなデータ取得を行うのかを判定する.判定方法として,すでにデータ取得してある過去の入力文を鍵括弧で囲った自然文で入力された場合は再考察と判定して,対応する入力文で取得したデータに対し再考察のみを行う.それ以外の場合はデータ取得と判定してそれを一から実行する.
実際の入力文の例を以下に示す.
①選択されるフロー:既存データに対して再考察のみを行う
入力文の例:「過去3年間の行動データからよく3月にライブに行く人の傾向を知りたい」について,モバイルキャンペーンの観点から再考察をしてください.
②選択されるフロー:データ取得から行う
入力文の例:過去3年間の行動データからよく3月にライブに行く人の傾向を知りたい.
選択される各フローでの動作は以下のようになっている.
(a)既存データに対して再考察のみを行う場合のフロー
既存データに対して再考察のみを行う場合では,では,まずセッションメモリーと呼ばれる過去のやり取りを保存するデータベースから取得済みのデータを取り出し,そのデータと現在の再考察の要望文をデータ可視化・考察エージェントに入力することで再考察結果を取得する.次に,再考察結果をユーザに提示して動作を終了する.ここでセッションメモリーに保存されている取得済みのデータとは,データ取得エージェントから得られた出力をそのまま格納したものである.
(b)データ取得から行う場合のフロー
データ取得から行う場合では,まずユーザの入力文からデータ分析パターンの判定を行う.分析パターンデータベースには,分析パターンごとに自然言語からなる要望例と分析テーマ,選択可能な分析パラメータ一覧とそれぞれのパラメータに対するデフォルト値が格納されている.
この工程ではLLM(Large Language Model)*8を用いた自動判定を行っており,分析パターンごとに用意された分析テーマ名・分析要望文例と入力文を比較することで最も類似度の高い分析パターンを判定する.一方,ユーザの要望がどの分析パターンにも当てはまらない場合は,判定不可としてユーザに分析が失敗したことを通知する.
分析パターンが決定すると,次にそこに紐づく分析パラメータ一覧を基にLLMを用いて,ユーザが入力した自然文から分析に必要なパラメータ値を自動抽出する.抽出できなかったパラメータはデフォルト値から埋め込む.
パラメータ値が決定すると,データを取得するためにデータ取得エージェントを呼び出し,抽出したパラメータ値とユーザからの自然文を入力し結果を受け取る.
データ取得エージェントの結果とユーザからの自然文をデータ可視化・考察エージェントに入力することで可視化・考察結果を受け取り,それらをユーザに提示することで一連のデータ分析が完了する.
各ステップおいて,前述のように分析パターンの振分けがされない(ユーザの要望がどの分析パターンにも当てはまらない)場合やデータ取得エージェントで対象のデータがなく取得時にエラーが発生する場合などは,分析失敗としてユーザに提示し分析要望を再入力するよう依頼する.
2.3 データ取得エージェント
データ取得エージェントは,意思決定エージェントから与えられた指示に含まれるパラメータ値とユーザの自然文入力に基づき,社内データベースから必要なデータを取得し,その結果を意思決定エージェントに返却する役割を担う.データを取得する範囲は分析パターンに応じた範囲に限定される.そのため分析パターンに該当しない要望については意思決定エージェントの段階で除外されデータ取得までは至らない.以下ではその処理の流れを示す.
(1)データ取得用プロンプト*9の作成
意思決定エージェントから渡されたパラメータ値とユーザからの自然文を基に,図3に示すデータ取得用プロンプトの該当箇所に適切な値を挿入し,プロンプトを作成する.
(2)データ取得機能の呼出しとデータの出力
作成したプロンプトをLLMに入力すると,LLMは「ユーザ入力」に基づいて対応するデータ取得機能を呼び出して必要なデータを取得する.この際,プロンプト中の「パラメータ値」から当該データ取得機能に必要な値を抽出し,機能呼出しに利用する.最後に,取得したデータを意思決定エージェントに返す.

2.4 データ可視化・考察エージェント
データ可視化・考察エージェントは,意思決定エージェントを介してデータ取得エージェントから渡されたデータとユーザの自然文入力に基づき,可視化を行うとともに,考察および次にとるべき戦略案を生成する役割を担う.
(1)考察観点の抽出
ユーザの分析要望に基づいて正しく考察を行うためには,まず適切な考察観点を抽出することが重要である.本処理では専用のプロンプトを用いる.図4にプロンプト例を示す.なお,図中の「データ分析専門者」は特定の役割を意味し,「ユーザ入力」は意思決定エージェントから渡されたユーザの自然文入力を指す.このように特定の役割を設定することで,ドメイン知識*10や視点を反映した観点抽出が可能となり,ユーザ要望に即した考察観点の提示を実現できる.
(2)考察用のプロンプトの作成と考察実行
「データ可視化→データ提示→考察観点に基づく考察・次にとるべき戦略案の出力」という流れを実現するために,図5に示す考察用プロンプトを作成する.具体的には,意思決定エージェントから渡されたデータ可視化用の情報およびデータ情報,ユーザの自然文入力,さらにユーザの自然文入力から抽出した考察観点を図5の該当箇所に挿入し,プロンプトを構築する.このように段階的に定義することで,一貫性と再現性の高い出力が可能となる.


2.5 機能群サーバ
本システムでは,バックエンド*11で機能している機能群サーバに,データ取得機能,データ可視化機能を実装した.
(1)データ取得機能
データ取得機能では,データ取得エージェントからのプロントによる指示に基づき,社内データベースから必要な情報を抽出する役割を担う.指示には分析パターン,抽出対象カラム*12,パラメータ値が含まれている.
本機能では,抽出対象カラムの名寄せ*13にLLMを使用している.これは,データ取得エージェントから受け取ったカラム名を,英文で記載されたデータベース上の正式なカラム名に変換する処理である.変換後のカラム名は,テンプレート化されたSQLクエリ*14に埋め込まれ,抽出用SQLクエリとして完成する.
例えば,ユーザが「今月のスマホの営業実績を調査したい」と入力すると,LLMは「スマホの営業実績」を社内データベース内のカラムと認識した後,データベース上の項目名である「phone_sales_amount」に変換し,抽出用SQLクエリのカラム選択部へ代入することで処理を完了する.
(2)データ可視化機能
データ可視化機能では,取得したデータとユーザが希望する可視化手法に基づき4種類のグラフを作成できる.すなわち,出力したいグラフを帯グラフ,積上げ棒グラフ,棒グラフ,箱ひげ図*15の中からユーザが自然言語で指定する.なお,各分析パターンにおいて,縦軸は固定としているが,横軸はユーザが選択肢の中から任意に選択できる.
- マルチAIエージェント:複数のAIエージェントがそれぞれ異なる役割を担い,相互に連携しながらタスクを遂行することを指す.
- 自然文:人間が日常的に使用する自然言語による文章を指す.
- サブエージェント:エージェントから呼出し可能な子エージェントのこと.本稿ではデータ取得エージェントとデータ可視化・考察エージェントが該当.
- LLM:大規模言語モデルのこと.
- プロンプト:LLMに入力される指示文や質問文を指す.
- ドメイン知識:特定の分野や領域(ドメイン)に固有の知識や経験を指す.
- バックエンド:GUIを動作させるためのシステム部分.主にエンジンおよびエンジンとGUIの動作を繋ぐシステム部分のこと.
- カラム:表形式のデータにおける縦方向の「列」のこと.名称や数値など,データの各項目を指す.
- 名寄せ:表記揺れや同義語など,多様な文字列で表現された同一の対象を,システムで一意に処理可能な特定の表記に統一・変換する処理を指す.
- SQLクエリ:データベースを操作するための言語であるSQLを用いて,データの検索や更新などを要求する命令文.
- 箱ひげ図:ばらつきのあるデータを分かりやすく表現するための統計学的グラフ.一般的には最小値,第1四分位点,中央値,第3四分位点および最大値を表現する.その場合,第1四分位点,第2四分位点(中央値),第3四分位点は“箱”で表現され,最小値・最大値は箱の両側に出た“ひげ”で表現される.
03. 評 価
3.1 評価概要
データ分析エージェントシステムについて,社内でデータ分析を担当している5名の社員を評価者として定量評価・定性評価を実施した.
(1)定量評価
本システムをユーザが利用する上で,データに関するドメイン知識やSQL作成スキルがない社員でも自然言語で分析指示ができることが重要である.そこで,各分析パターンについて,何回目の試行で,目的のデータが取得できる指示ができたかを評価した.評価者には,事前に取得可能データやその期間,可視化方法に関する制約条件とエージェントへの入力例を提示した.その上で,試行回数の上限は3回とし,各分析パターンについて実施することを想定して,AIエージェントへの分析指示をテキストで入力するよう評価者に依頼した.
(2)定性評価
本システムの各機能について,実業務で活用する上での使いやすさを主観評価した.
3.2 評価結果
(1)定量評価
評価者が何回目の試行で目的のデータを取得できる指示ができたか,その平均試行回数は分析パターンAで1.4回,分析パターンBで1回,分析パターンCで1.6回であり,すべての評価者がすべての分析パターンにおいて3回以内に目的のデータを取得することができた.この結果から,データ分析を担当している社員が本システムを用いて自然言語で分析要望を入力するとき,3回以内に必要なデータを取得できることが確認できた.
(2)定性評価
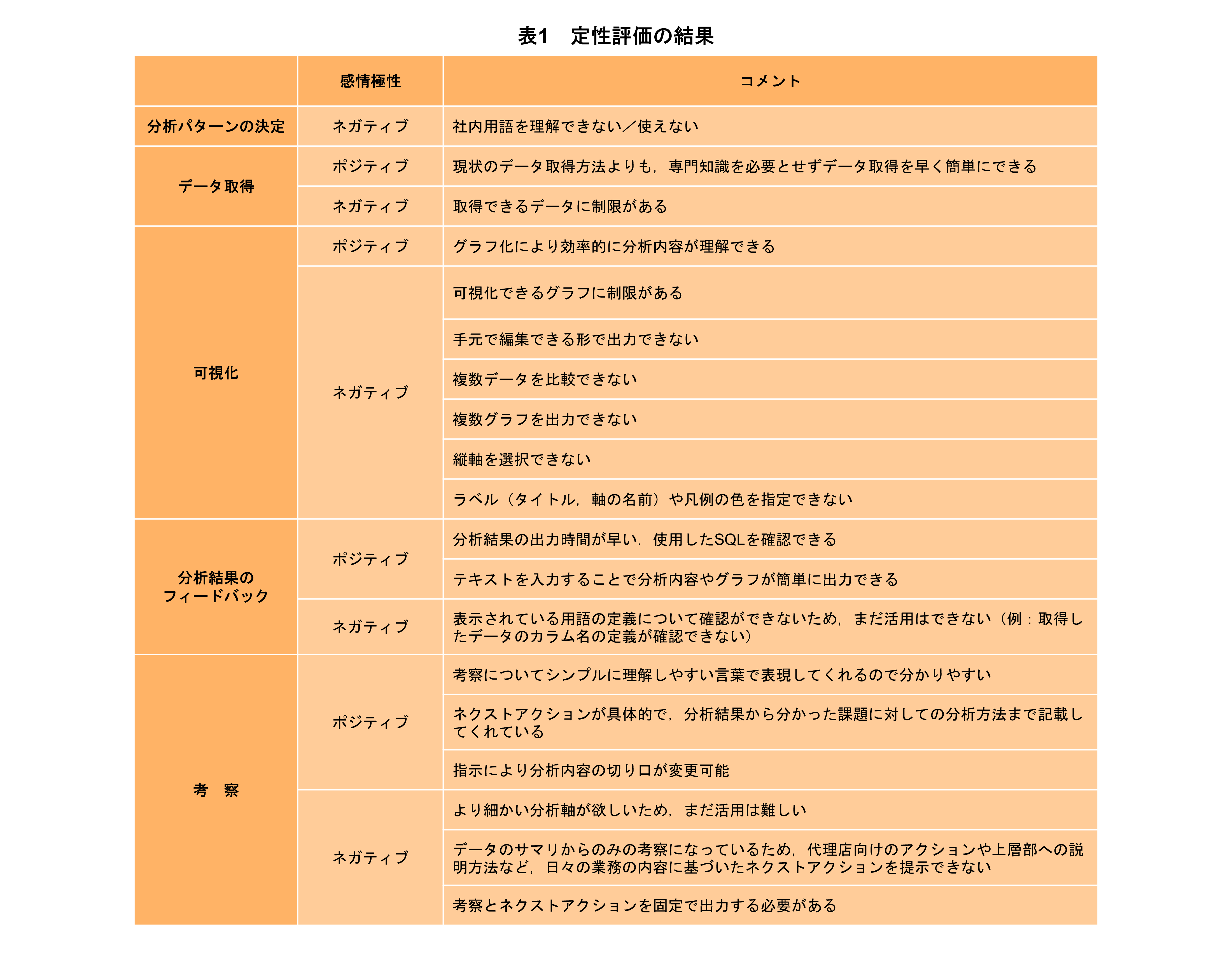
定性評価の結果のまとめを表1に示す.
ポジティブなコメントとしては,専門知識を必要とせず迅速かつ容易にデータ取得ができる点や,グラフによる可視化,また平易な言葉で出力される考察により結果を効率的に理解できる点が挙げられた.また,具体的なネクストアクションが提示される点も好意的に受け止められた.
一方ネガティブなコメントとしては,取得できるデータや可視化できるグラフの種類,軸・ラベルの指定などに制限があり,手元で編集可能な形式で出力できないといったカスタマイズ性の低さが指摘された.さらに,より細かい分析軸による深掘りや,日々の業務内容に即した具体的なネクストアクションの提示が困難であるといった,分析の深度に関する課題も挙げられた.全体として「社内用語を理解できない/使えない」などの機能の制限に関するコメントが多く見られ,まだ実業務への活用は難しいというコメントも見られた.この結果から,本システムはデータ分析の敷居を下げる点では一定の有効性が確認できたものの,実業務を完遂するためには,機能の柔軟性や用語対応などのさらなるチューニングが重要であることが明らかとなった.今後はこれらの知見を基に,実務適用レベルへの引上げを図る.
04. 考 察
前述の定量評価の結果から,人手でSQLクエリを作成してデータを取得する場合と比較して,専門知識をもたない担当者でも本システムを用いることで,実装した分析パターンであれば容易に目的のデータを取得できると考えられる.一方で今回実装した分析パターンは3パターンと種類が限定的であり,今後分析パターンが拡大した場合には,1回の入力だけでは分析パターンの特定が難しい可能性がある.そのため,今後は複数回の対話により取得・分析したいデータの情報を深堀りする機能を実装する予定である.
さらに,定性評価の結果から,分析パターンの決定については社内用語への未対応が課題となっており,社内用語のデータベースを参照する機能の実装を検討する.また,データ取得については取得できるデータの範囲に制限があることが課題となっており,取得範囲の拡充のため,社内で過去に利用された分析パターンとそれに対応したSQLの拡充や,過去に用いたことのあるSQLでは対応できないデータについてNatural Language to SQL技術*16の適用を検討する.可視化についてはカスタマイズ性の低さが課題となっており,複数グラフの出力や軸・ラベルの個別指定を可能にするなど,可視化の表現方法を拡充することを検討する.分析結果のフィードバックについては,表示されている用語の定義について評価者が確認できないことが実業務で活用する上でのネックとなっており,テーブルのカラム情報や社内用語テーブルを参照する機能を実装し,解釈を支援する.さらに考察については分析軸の柔軟性の欠如がネックとなっており,分析の複数手法の選択や必要に応じてデータを対話的に再取得する機能の追加をめざす.
- Natural Language to SQL技術:自然言語によるユーザ入力を解析し,対応するSQL文を自動生成する技術.
05. あとがき
本稿では,データ取得・可視化・考察にAIエージェントを用いた,データ分析エージェントシステムについて解説した.今回実装したデータ分析エージェントシステムの導入効果として,専門知識をもたない担当者でも容易に分析指示を出せることを確認した.これは,分析業務における属人化の課題を解消し,各担当者の分析能力向上に貢献するものである.
一方で,今回の実証実験により,社内用語の認識精度や取得データの範囲など,ユーザの満足度をさらに向上させるために今後取り組むべき具体的な課題が特定された.そのため,今回の検証で得られた課題を踏まえ機能拡充と有効性検証を継続しつつ,今後は前述の考察のとおり本システムを改善することにより,社内の多様な業務に対応できるデータ分析エージェントシステムを構築し,全社的な業務効率化へのさらなる貢献をめざす.


