

サービス横断データおよびユーザ興味関心データを活用した大規模コンテンツレコメンドエンジンの開発
- #データ/AI活用
明石 航(あかし わたる)
宮木 健一郎(みやき けんいちろう)
相場 邦宏(あいば くにひろ)
前沖 翔(まえおき しょう)
加藤 剛志(かとう たけし)
サービスイノベーション部
あらまし
ドコモでは,多種多様なサービスを抱える上,数多くの加盟店商材を扱っているため,膨大かつ幅広い領域のコンテンツを有している.このような環境下では,ユーザの選択肢が膨大なものとなり,レコメンドにおいてユーザ1人ひとりに最適なコンテンツを効率的に推薦することが課題となる.このため,コンテンツの情報と,複数のサービスのログ,リアルでの行動ログ,契約情報などを活用することでコンテンツやユーザの特徴を適切にとらえ,さらにTwo-Towerモデルや近似最近傍探索技術を活用することで,効率的に推薦することができるレコメンドエンジンを開発した.
01.まえがき
近年,動画などの各種配信サービスや電子書籍などのプラットフォーム,EC(Electronic Commerce)サイト*1の普及により,ユーザは膨大な量のデジタルコンテンツにアクセスできるようになった.映画やドラマ,音楽,書籍,ゲームなど,その選択肢は非常に豊富であり,日々新たなコンテンツがサイトに追加され続けている.このような状況下では,ユーザが自らの好みやニーズに合ったコンテンツを見つけ出すことが困難になってきている.
この課題に対する解決策として,レコメンドエンジンが注目を集め,進化を遂げてきた.レコメンドエンジンとは,ユーザの過去の行動履歴や評価データを基にして,個々の嗜好に適したコンテンツを推薦するエンジンである.機械学習*2技術の発展により,これらの技術はますます高精度化し,ユーザ体験の向上に寄与している.
レコメンドエンジンには,あるユーザに対して,同様の傾向をもつユーザのクリック/購買履歴を基にしたコンテンツを推薦する,協調フィルタリング*3といったユーザ起点のアプローチや,ユーザが過去に閲覧したコンテンツと画像やカテゴリなどの特徴が類似するコンテンツを推薦する,コンテンツ起点のアプローチなどがある.近年では,深層学習*4を用いた予測モデルにより,これらのアプローチを統合したハイブリッド型といった手法も提案されている.デジタルコンテンツを扱うサービスでは,これらの技術を活用し,ユーザに適切かつ多様なコンテンツを推薦することで,ユーザの満足度を高めてきた.
しかし,高度なレコメンドエンジンを構築・運用する上での課題も存在する.ドコモでは,複数の動画配信サービスや電子書籍サービス,ECサイトなど幅広い分野のサービスを運営していることに加え,1億人を超えるdアカウントユーザが存在する[1].このように,コンテンツとユーザが非常に数多く存在する中で,個々のユーザに対して適切にパーソナライズされた推薦結果を提供するのは容易ではない.
高度なレコメンドエンジンの構築・運用の課題として,例えば,コンテンツの推薦に向けて適切な学習を行うためには,各コンテンツに均等な量の履歴データが必要であるが,大量のデータがあっても実際には人気な商品や動画などに履歴が集中しており,それ以外のコンテンツでは履歴がまばらであるため,適切に学習を行うことができないということがある.
また,Web上などで即時に推薦結果を提示するためには,数億件のコンテンツの中から各ユーザに対して何を推薦するかを高速に推定する必要がある.
さらには,推薦結果の質を保つために,日々更新される大量のデータを常に学習し更新できる仕組みも必要である.
これらを踏まえ,ドコモでは以下3つの課題に対してアプローチを検討した.
- 学習に利用可能なデータのスパース性*5に関する課題
- 大規模なユーザ数とコンテンツ数の計算速度に関する課題
- 日々更新される大量のデータに対する追従性に関する課題
ドコモでは,自社のもつ多様なデータやTwo-Towerモデルと呼ばれる深層学習モデルや近似最近傍探索技術を組み合わせることで,これらの課題を解決できるレコメンドエンジンを開発した.本稿では,この課題についてより詳しく紹介するとともに,それらに対するレコメンドエンジンの各要素におけるアプローチ,そして,履歴データを用いた実サービスでの精度検証結果について解説する.
- ECサイト:商品やサービスを販売するWebサイト.
- 機械学習:コンピュータがデータを使用して自動的にパターンを学習し,その学習を基に予測や意思決定を行う技術.
- 協調フィルタリング:多数のユーザについて,購買履歴などの嗜好情報をあらかじめ蓄積しておき,目的のユーザと嗜好の類似した他のユーザの情報を用いて,そのユーザに対する予測や推薦を行う手法.
- 深層学習:多くの層をもつ学習システムを使って,データの特徴を自動で学ぶ機械学習手法の一種.
- スパース性:データや表現の中で,非ゼロの要素が少ない状態.
02.レコメンドにおける課題とアプローチ
2.1 学習に利用可能なデータのスパース性に関する課題
通常レコメンドエンジンを実現するにあたっては,どのユーザがどのコンテンツをクリック/購買したかという行動履歴データを用いて推薦結果の最適化を実施するが,こうした場合,推薦すべきコンテンツの種類に対して,各ユーザがクリック/購買した商品数が非常に少ない(スパースである)という問題が発生する.このため,推薦の精度が低下する可能性がある.
このような課題に対して本開発では,類似した複数のサービス横断データが特徴量*6として組み込まれたTwo-Towerモデルを用いることでアプローチしている.これは,Two-Towerモデルがさまざまな特徴量を統合することが容易な性質だからである.
2.2 大規模なユーザ数とコンテンツ数の計算速度に関する課題
従来のレコメンドエンジンでは,ユーザとコンテンツの特徴量を用いて,推薦すべきコンテンツの組合せを事前に計算し,その結果をユーザに提供することが一般的であった.しかし,従来の方式では,ユーザ数やコンテンツ数が増大するにつれて,その積である組合せ数が増大し,計算リソースや時間が膨大になるという問題がある.単純化すると,計算時間は組合せの数に比例すると仮定できるので,ユーザ数やコンテンツ数が増大すると計算時間も飛躍的に増大する.
数百万人のユーザに対し,数万件のコンテンツを推薦する従来の問題設定と,今回想定する1億人以上のユーザに対し数億件のコンテンツを推薦する必要がある問題設定では,ユーザ数が約100倍,コンテンツ数が約10,000倍に増加するということになる.これはすなわち,単純計算で計算リソースや時間が約1,000,000倍に増加するということであり,全く現実的ではない.
この課題に対して,本開発ではTwo-Towerモデルと近似最近傍探索技術を活用して計算の高速化を図っている.
具体的には,コンテンツを表現するベクトル(以下,コンテンツベクトル)およびユーザを表現するベクトル(以下,ユーザベクトル)を同空間上にマッピングし,推薦結果を取得する方式とした.これにより,一度特徴量抽出を実施すればその特徴量を使い回すことができるので,逐一特徴量抽出を行う必要がなくなり,特徴量抽出部分の計算コストを削減できる.また,Two-Towerモデルにおいては,コンテンツベクトルとユーザベクトルのマッチングを行い,その結果をランキングすることで推薦結果を取得するが,そのマッチング処理においても近似最近傍探索技術を活用することで高速化を実現し,現実的な時間での推薦結果取得を可能とした.
2.3 日々更新される大量のデータに対する追従性に関する課題
従来のアプローチでは,各ユーザと推薦するコンテンツの組合せを事前に計算し,その結果をデータとして保持しておく必要があった.しかし,このアプローチは,前述のとおり新コンテンツや新トレンドの学習に現実的ではない計算時間がかかるため,迅速に対応することが困難であった.
加えて,各ユーザと推薦するコンテンツの組合せのデータ保持に膨大なリソースを要するため,多くのコストがかかることになる.
これらの課題に対しても,Two-Towerモデルと近似最近傍探索技術によってアプローチした.
これにより計算時間が削減され,学習によるモデルの頻繁な更新が可能となり,新コンテンツや新トレンドといったデータの更新に迅速に対応する.
さらに,各ユーザと推薦するコンテンツの組合せを事前に計算・保存しておく必要がなくなり,データ保持コストも削減される.具体的には,保持するデータが各ユーザと推薦コンテンツの組合せすべてではなく,コンテンツベクトルとユーザベクトルに限定される.そして,各ユーザに対する推薦コンテンツの生成を,近似最近傍探索技術を用いることで高速に行い,その都度計算結果が推薦コンテンツとして提供されるので,膨大なデータを保持し続ける必要がなく,ストレージや計算リソースのコストを大幅に削減できる.
- 特徴量:機械学習モデルがデータのパターンを学習するために用いる,データの具体的な属性や情報.
03.提案手法
ドコモでは,以下のようなアプローチを組み合わせることで,大規模なユーザ数かつコンテンツ数という環境下でもユーザへの適切な推薦を実現できるレコメンドエンジンを開発した.
上記により,コンテンツやユーザの特徴を正確に把握した上でモデル学習を行い,高速に推薦結果を返却することが可能となった.また,サービス横断のデータを活用することで推薦対象以外のサービスにおけるユーザ行動もとらえ,より正確なユーザ特徴の把握をめざした.例えば,サービスAのWebサイトでユーザへコンテンツの推薦を行う場合,サービスAのデータのみでなく他サービスBのデータも用いるといった方法である.
以降で,それぞれのアプローチについて詳細を解説する.
3.1 特徴量生成
膨大かつ幅広い領域のコンテンツの中からユーザの嗜好に合うコンテンツを推薦するには,コンテンツおよびユーザの特徴把握が重要となる.
コンテンツにおいては,メタ情報に対して自然言語処理*10技術を活用することで,コンテンツの概念的な特徴やコンテンツ間の関連性まで反映した特徴量生成を可能とした.また,ユーザにおいては,属性情報や契約情報,オフライン行動*11ログを活用することで,より正確な特徴量生成を可能とした.以上により,幅広い領域のコンテンツとユーザの興味関心の親和性をより高い精度で予測することが可能となった.
(1)コンテンツ情報のベクトル化
コンテンツ情報として,コンテンツ名,コンテンツ詳細,カテゴリを用いた.例えば,映像作品であればそれぞれ作品タイトル,あらすじ,作品カテゴリが該当する.これらの情報に自然言語処理技術を適用して1コンテンツ当り1つのベクトルを生成した.
具体的には,コンテンツ名,コンテンツ詳細に形態素解析*12を活用して出力した単語に対して分散表現*13(単語ベクトル)を獲得し,品詞ごとの単語ベクトル(名詞ベクトル,形容詞ベクトルなど)の数値を平均化した.カテゴリ情報に関しては,形態素解析を行わずに分散表現を獲得した.これらのベクトルを連結することでコンテンツを表現するベクトル(以下,コンテンツ情報ベクトル)とした.
(2)ユーザ情報のベクトル化
ユーザ情報として,推定性別,推定年代,推定居住地,docomo Sense[2]興味関心スコアおよび直近履歴のコンテンツ情報ベクトルをユーザごとに用いた.なお,docomo Sense興味関心スコアとは,オフライン行動ログや契約者情報などから生成された,一般的なカテゴリ(「家具」「ファッション」「本」など)ごとの興味関心度をスコア化したものである.
推定性別,推定年代,推定居住地については,カテゴリ変数*14として埋込み表現*15を獲得し,docomo Sense興味関心スコアについてはそのまま用いた.これらの埋込み表現,docomo Sense興味関心スコアおよび直近履歴のコンテンツ情報ベクトルを連結することでユーザを表現するベクトル(以下,ユーザ情報ベクトル)とした.
3.2 Two-Towerモデル
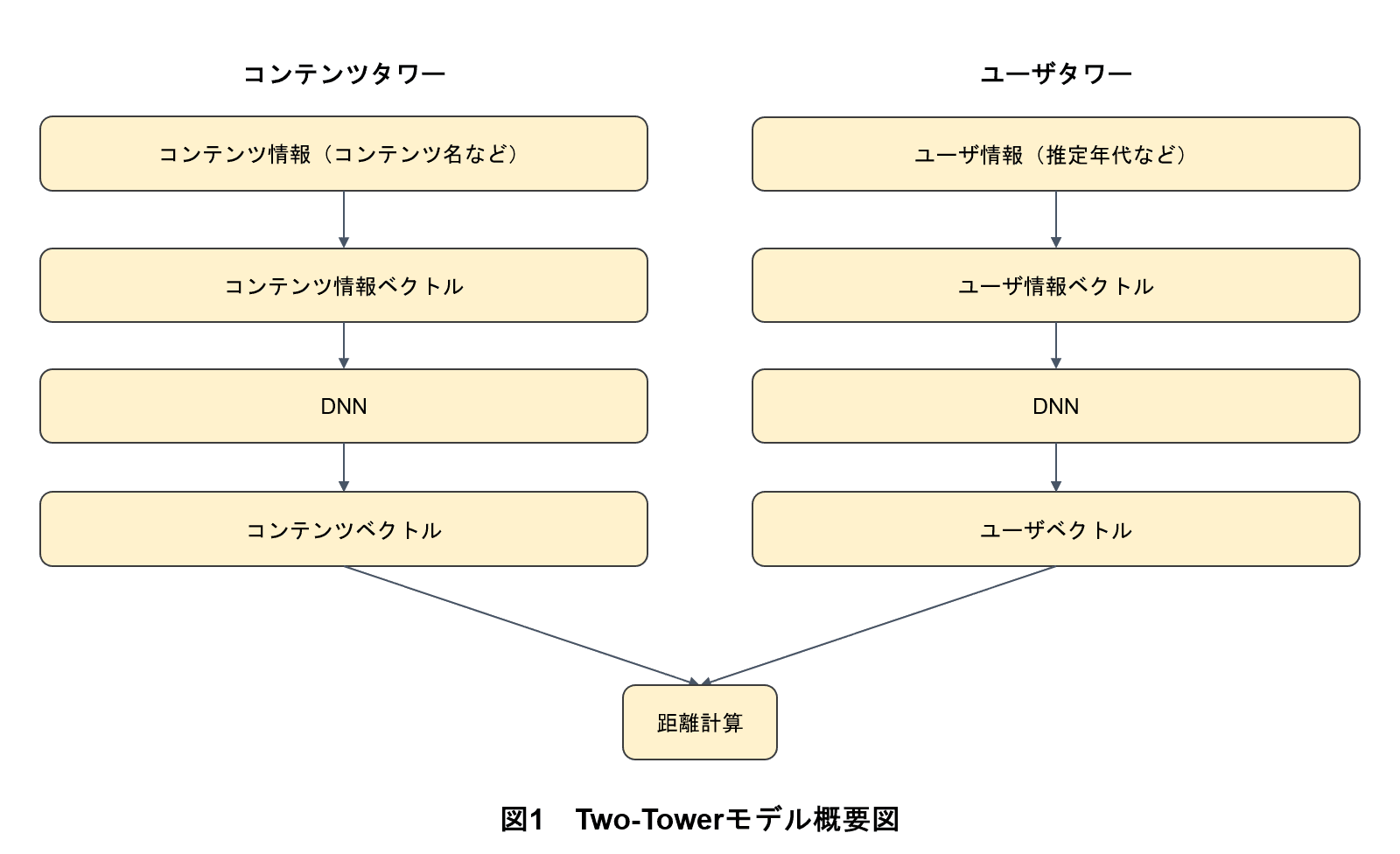
Two-Towerモデルとは,主にレコメンドエンジンや情報検索の分野で用いられる深層学習モデルの一種である.コンテンツとユーザをそれぞれ独立してベクトル化し,両者の相互作用を学習するためのアプローチである.事前にコンテンツおよびユーザの特徴をベクトル化できる点,特徴量の追加によるモデル改善がしやすい点から採用した.Two-Towerモデルは,以下2つの要素で構成されている(図1).
- コンテンツタワー(Content Tower):コンテンツに関する情報を入力し,コンテンツの特徴をベクトル化する
- ユーザタワー(User Tower):ユーザに関する情報を入力し,ユーザの特徴をベクトル化する
ドコモでは,本アプローチを用いてモデル学習を行った.コンテンツタワーおよびユーザタワーにはそれぞれ前述にて特徴量化されたコンテンツ情報ベクトル,ユーザ情報ベクトルを入力した.その後DNN(Deep Neural Network)*16と呼ばれる層を通った後に履歴上のクリックの有無に応じて学習した.具体的には,クリックされているコンテンツに対してはそのユーザが近くなるように,クリックされていないコンテンツに対してはそのユーザが遠くなるように学習した.
推薦結果を各ユーザに返却する準備として,学習済みのTwo-Towerモデルに各コンテンツのコンテンツ情報ベクトル,各ユーザのユーザ情報ベクトルを入力することで,学習結果を反映したコンテンツベクトルおよびユーザベクトルを推論した.そうすることで,履歴情報も考慮した上でユーザ・コンテンツ間,ユーザ間,コンテンツ間それぞれの関連性を反映することができる.
3.3 近似最近傍探索技術
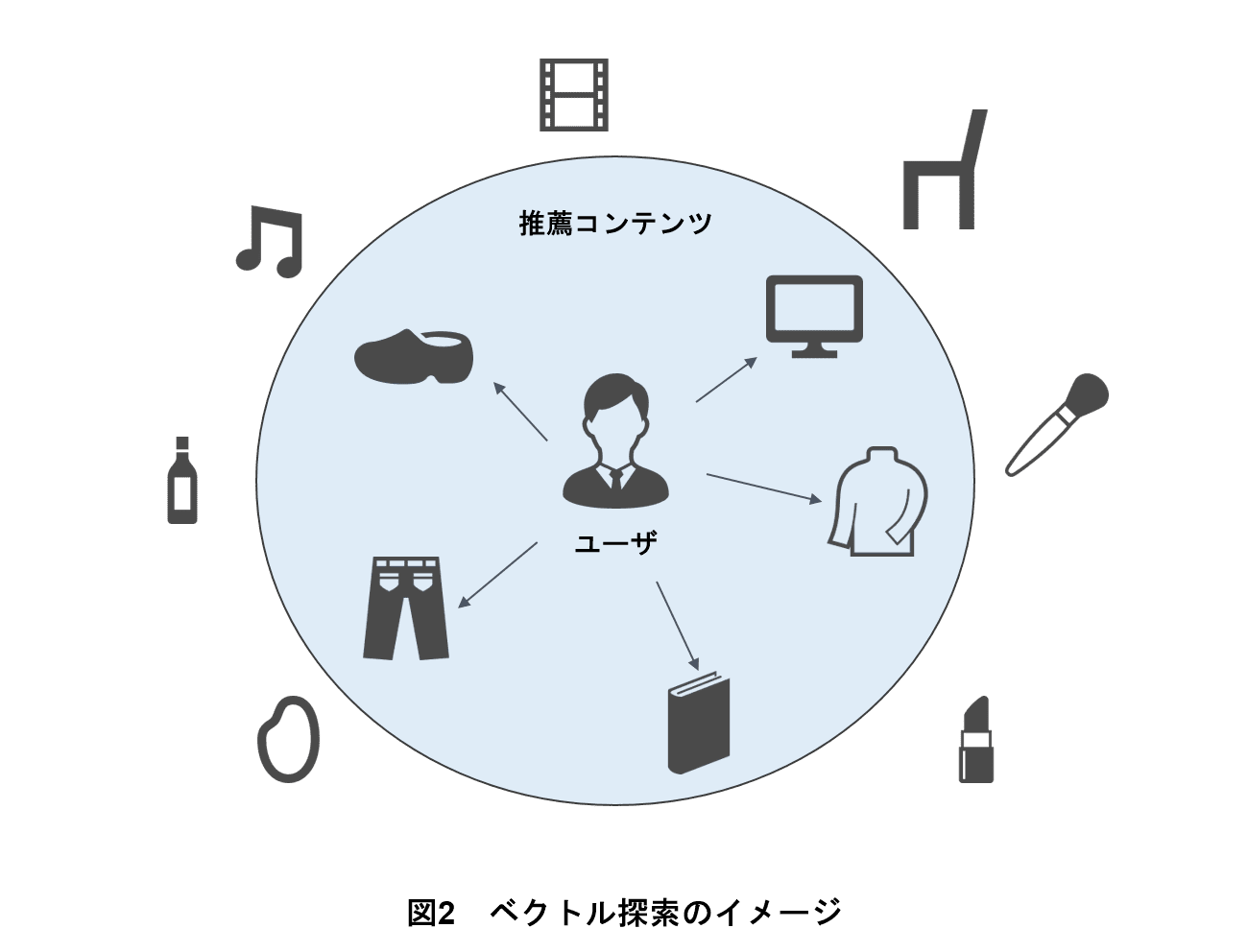
このステップでは,実際にユーザへ推薦結果を返却する際にどのコンテンツを推薦するかを決定する.そのために,図2のように結果返却対象ユーザのユーザベクトルに近い(類似度の高い)コンテンツベクトルを探索する.総当りで探索する方法もあるが,推薦結果返却時に毎回その処理を行うと時間がかかってしまいユーザ体験を損ねてしまう.そこでドコモでは近似最近傍探索技術を採用した.
近似最近傍探索技術とは,あるデータに近いデータを素早く探す方法である.例えば,大量の画像やデータの中から,「この画像に似た画像をすぐに見つけたい」といった場合に有用である.すべてのデータを1つ1つ確認するのは時間がかかるため,本技術ではクラスタリングなどを用いて近くにあると定めておいたデータを対象のデータと比較することで,検索を素早く行う.これにより,膨大なデータの中から効率的に関連する情報を見つけ出すことができる.
本技術を用いることで,総当りと比較して約10倍の速度で,ユーザベクトルに近いコンテンツベクトルを探索することが可能となった.
- コンテンツ情報:作品や情報の詳細を示すデータ.例として,タイトルや著者,ジャンルなどが含まれる.
- ユーザ情報:ユーザに関する情報で,年齢や性別,趣味など,ユーザを特徴づけるデータ.
- 推論:モデルが新しいデータに基づいて予測や分類を行うプロセス.
- 自然言語処理:コンピュータが人間の言語を理解したり,使ったりする技術.
- オフライン行動:インターネットに接続していないときのユーザの行動.例えば,実店舗での買い物など.
- 形態素解析:言葉を意味のある最小の部分に分けて,その構造を理解すること.
- 分散表現:単語やアイテムを数値の組合せで表現し,類似性を保つ方法.
- カテゴリ変数:特定のカテゴリに分類されるデータのこと.例として,性別や興味があるテーマなど.
- 埋込み表現:データを数値のベクトルに変換する方法.意味的な関係を保つために使われる.
- DNN:多くの層で構成された学習システムのこと.複雑なデータから特徴を自動で学ぶことができる.本稿では,次元数や表現の粒度が異なるコンテンツ情報ベクトルやユーザ情報ベクトルを,学習過程で同じベクトル空間にマッピングできるよう数値を調整する役割をもつ.
04.レコメンドエンジンの検証
4.1 目的
新たなアプローチを適用したレコメンドエンジンの性能を評価するため,実サービス環境においてオンライン検証を実施した.
4.2 検証環境
本検証を,ドコモが運営する動画配信サービス上で実施した.本サービスは多数のユーザに利用されており,レコメンドエンジンの性能が視聴体験に大きく影響することが予想される.そのため,ユーザへの影響を最小限に抑えるよう配慮し,検証期間を1週間に区切り,旧レコメンドエンジン(以下,従来手法)と新レコメンドエンジン(以下,本手法)をそれぞれ適用する形で検証を行った.なお,従来手法については,ユーザのセッションデータのみを入力としたリカレントニューラルネットワーク(RNN:Recurrent Neural Network)*17を採用している.
4.3 評価指標
本検証では,評価指標として推薦コンテンツの視聴有無に着目し,コンバージョン率(CVR:Conversion Rate)*18を採用した.CVRは,推薦されたコンテンツが実際に視聴された割合を示し,以下の式で算出される.
CVR=(視聴されたコンテンツ総数/推薦されたコンテンツ総数)×100
本指標は,動画配信サービス上におけるレコメンドエンジンがユーザの興味をどれだけ正確にとらえているかを測定する上で重要であり,本検証の目的に適合していることから採用された.
4.4 検証結果
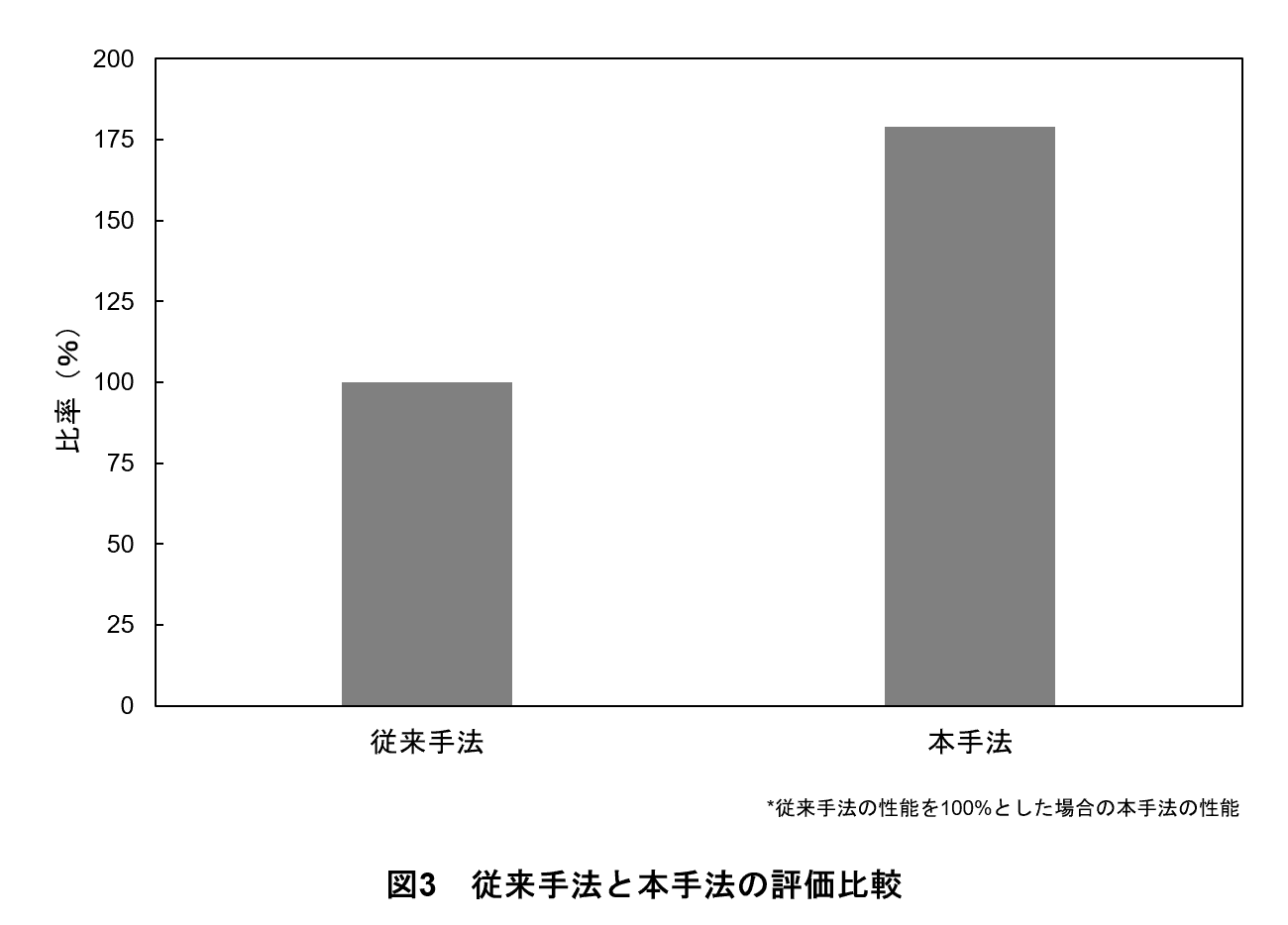
検証の結果,図3のとおり本手法のCVRは,従来手法から約1.79倍向上した.これは,本手法がユーザの嗜好を的確にとらえ,より関連性の高いコンテンツを推薦できることを示している.
- リカレントニューラルネットワーク(RNN):データの順序や時間的な関係を扱うための深層学習モデルで,過去の情報を記憶し,それを基に次の出力を予測する.
- コンバージョン率(CVR):ユーザが特定の目標行動(視聴,購入など)を実行した割合を示す指標.
05.あとがき
本稿では,ドコモの多様なデータを活用し,大規模なユーザ数とコンテンツ数に対応可能なレコメンドエンジンの概要と検証結果を解説した.現代のデジタルプラットフォームでは,ユーザごとにパーソナライズされた体験を提供することが求められており,その実現には高精度かつ効率的なレコメンドエンジンが不可欠である.今回は,Two-Towerモデルや近似最近傍探索技術といった最新技術を組み合わせることで,これまでのレコメンドの課題を克服する高性能なレコメンドエンジンを構築した.また,実サービス環境における検証の結果,本手法のCVRは従来手法から約1.79倍向上した.これは,本手法がユーザの嗜好に的確に対応し,より関連性の高いコンテンツを推薦できることを示している.
本レコメンドエンジンは,ドコモの多様なサービスにおけるユーザ体験の向上だけでなく,収益性やエンゲージメント*19の強化にも貢献する.このため今後は,CVRのさらなる向上をめざし,Two-Towerモデルへの入力データであるコンテンツ情報ベクトルおよびユーザ情報ベクトルの品質向上やモデルの解釈性強化といった課題に取り組み,ドコモサービス上におけるより良い顧客体験の実現に向けてレコメンドエンジン開発を行っていく.
- エンゲージメント:特定の対象(顧客,ユーザ,従業員など)との関係性や関与度.
文献
-
[1] NTTドコモ:“dポイント | ドコモのスマートライフ事業 | NTTドコモキャリア採用.”https://information.nttdocomo-fresh.jp/career/smart_life/service_list/dpoint/

-
[2] NTTドコモ:“顧客理解エンジン「docomo Sense」.”https://ssw.web.docomo.ne.jp/marketing/strengths/sense/


