

次世代機械翻訳体験を推進するtsuzumiを中心としたLLM利活用技術
- #データ/AI活用
- #LLM
岩月 憲一(いわつき けんいち)
北川 浩太郎(きたがわ こうたろう)
鳥居 大祐(とりい だいすけ)
株式会社みらい翻訳 エンジニアリング部
あらまし
本稿では,大規模言語モデル(LLM)を用いた次世代機械翻訳体験について解説する.まず,NTTが開発したLLM「tsuzumi」は,自然で流暢な日本語を出力し,段落構造の保持も実現するという特性があることを示す.次に,翻訳前後の文書修正,要約,およびスタイル変換など,翻訳にかかわる業務フロー全体を支援する機能を紹介する.
01.まえがき
これまで,機械翻訳*1の研究開発においては,いかに原文の意味を正確に保ったまま他言語に翻訳するかが重要であった.しかし,機械翻訳サービスを業務で利用する場合,翻訳は業務フローの一部に過ぎない.機械翻訳サービスがその前後の業務フローまで巻き取れば,より一層の業務改革とそれに伴う生産性向上に資することができる.
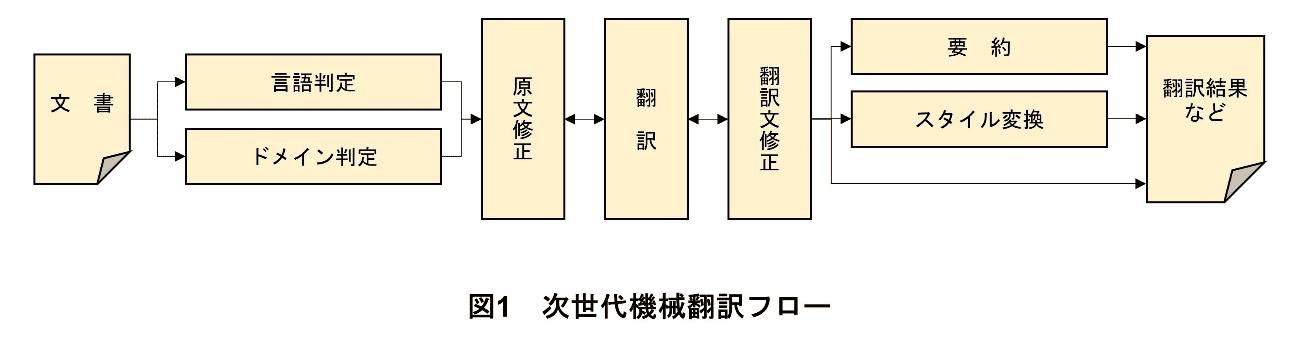
自然言語処理において,従来,分類系のタスクは比較的高精度で解くことができていたが,生成系のタスクは必ずしも実用的な水準ではなかった.しかし,大規模言語モデル(LLM:Large Language Model)*2によって,生成系のタスクであっても十分な結果を得ることができるようになってきた.これにより,翻訳前の文書の修正,翻訳後の文書の修正,要約,スタイル変換など,次世代の機械翻訳体験を実現できる素地が整いつつある(図1).
LLMは,英語を中心としたデータを用いて学習されたモデルが複数公開されている.翻訳サービスにおいては,英語や日本語など多言語を扱うため,必ずしもそれらのLLMが翻訳に適しているわけではない.他方,NTT研究所が開発したLLM「tsuzumi」は大量の日本語の文書を用いて学習されており,日本語文書への適用が期待される.
また,LLMはパラメータサイズ*3が大きくなるほど性能が向上する反面,運用コストが増大することが一般的である.しかし,tsuzumiは比較的軽量なモデルであるにもかかわらず,次世代翻訳体験の多くに対応できることが分かっている.
本稿では,まずtsuzumiを用いた翻訳の特長について述べる.そして,より大規模なものも含め,LLMを用いて次世代機械翻訳体験を実現するための取組みについて解説する.
- 機械翻訳:ある言語の文章を,別の言語の文章に,コンピュータを用いて自動的に翻訳するタスク.
- 大規模言語モデル(LLM):大量のテキストデータを用いて構築された自然言語処理のモデル.従来の言語モデルよりも高度な自然言語処理タスクに利用可能である.
- パラメータサイズ:ニューラルネットワークを構成するすべての行列成分の総数.
02.tsuzumiによる翻訳
2.1 tsuzumiの特長(自然で流暢な日本語)
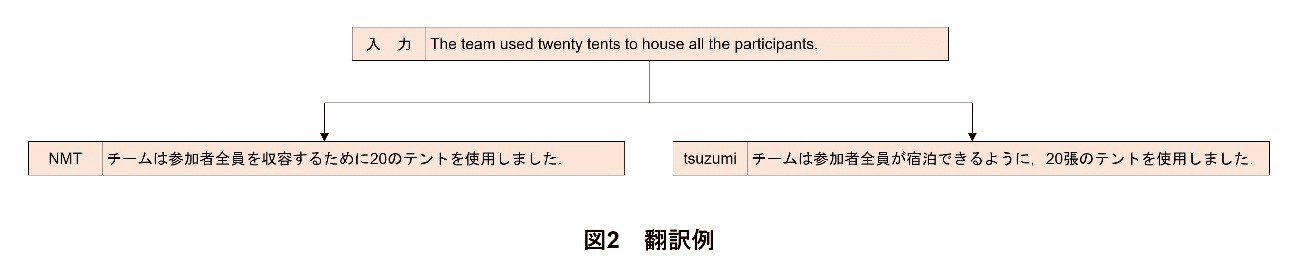
日本語への翻訳において,元の英文などの内容が正確に反映されていることは重要であるが,それに加えて,読みやすく理解しやすい日本語であると,英文などから情報を得る業務に従事するユーザがより早く目的を果たせるという点で生産性を向上させることができる.tsuzumiは,高い日本語処理能力をもっているとされており,翻訳においてもより自然で流暢な和文を出力することが期待される.
その一例を図2に示す.日本語は英語と異なり助数詞が多様であるが,これを正確に訳し分けるのは簡単ではない.図2では,tents「テント」に対して,ニューラル機械翻訳(NMT:Neural Machine Translation)*4は助数詞を付けずに訳しているが,tsuzumiは「張」という助数詞を用いている.このようにtsuzumiは,より日本語らしい日本語を出力することができるのである.
2.2 tsuzumiの改良(段落構造の保持)
ビジネスにおいては,単文を翻訳したい場面よりも,文書を丸ごと翻訳したい場面のほうが圧倒的に多い.従って,単文での翻訳精度をみるだけでは不十分である.LLMは従来のNMTより長い文脈を扱うことができるとされるため,文書全体の翻訳への応用が期待されるところである.しかしながら,LLMを用いた翻訳においては,文書の段落構造が維持されないという問題がある.例えば,10段落からなる文書を翻訳すると,一部要約されて8段落に減ってしまったり,逆に補足説明が付加されて段落数が増えてしまったりする.
この問題に対処するため,段落数を維持するための訓練用データセットを構築し,tsuzumiに対するファインチューニング*5を行った.その結果,段落数の維持率が6割から9割へと向上した.
- ニューラル機械翻訳(NMT):従来の統計的機械翻訳に対し,ニューラルネットワークを用いた機械翻訳を示す表現.LLMもニューラルネットワークがベースであるが,慣例的にLLMとは区別される.
- ファインチューニング:基本となるモデルを1つまたは複数のタスクに特化させるために,そのタスクの入出力の例を与え,学習させること.
03.次世代機械翻訳体験
みらい翻訳では,LLMを利活用した次世代機械翻訳体験を実現する取組みを行っている.ここではその取組みについて述べる.
3.1 文書の性質の判定
(1)言語判定
翻訳する文書がどの言語で書かれているかを判定するタスクが言語判定である.翻訳サービス内部においては,言語別に翻訳モデル*6が用意されている場合もあれば,多言語対応したモデルが用意されている場合もあるが,機械翻訳を行う場合は,いずれにしても翻訳元の言語が判明していたほうが良い.従来はユーザが翻訳元の言語を選択してきたが,1つの文書に1つの言語しか現れないという保証はなく,翻訳モデルの方でより細かい単位での言語判定をすることも必要な場合がある.
言語判定のような分類問題*7を解くためには,分類モデルを用いるのが普通である.この場合,さまざまな言語のデータを事前に用意し,訓練することが求められる.しかし,LLMの場合,訓練が不要なことがある.そこで,tsuzumiの言語判定能力を実験により調べたところ,英語や中国語に加え,カタルーニャ語やエストニア語など,さまざまな言語の判定がzero-shot*8であってもできることが分かった.
(2)ドメイン*9判定
みらい翻訳では,特許専用モデルや法務・財務専用モデルを提供している.このように,分野特有の表現に対応するためには複数のモデルを用意することが効果的であるが,分野数が数百,数千と増えればモデルを選択する手間が無視できない上に,分類器*10を学習させるコストも増大する.しかし,tsuzumiを用いればこの問題を回避できる.実験の結果,tsuzumiを別途訓練することなく,例えばニュースや特許などの文書タイプを判定できることが分かった.
3.2 翻訳前後の修正
入力された文章だけでは,正確な翻訳ができない場合は少なくない.日英翻訳の場合,入力された日本語の文章に主語が不明瞭な箇所や主述のねじれがあり,結果的に正しい英文にならないことがある.また英日翻訳では,多義語の訳出において,提供されている文脈のみからは適切な訳語を判断しかねる場合がある.
そこで,英訳前の日本語の文章を翻訳に適した形に修正し,また,和訳後の日本語の文章をLLMの知識を用いて修正するタスクに取り組んでいる.翻訳後の修正の例を図3に示す.上から,入力の英文と,NMTによる翻訳結果,そしてGPT-4oを用いて修正した結果である.太字下線部のthe marblesという単語に注目されたい.marbleは「ビー玉」や「大理石」という意味である[2]から,「ビー玉」という翻訳結果をただちに誤訳であると断じるのは難しいように思われる.実際にはこのthe marblesはエルギン・マーブルズというパルテノン神殿の彫刻のことを指しており,それが分かるように訳さなければ文の主旨を見失う.入力文にはエルギン・マーブルズという言葉は出ておらず,パルテノン神殿の彫刻であることも述べられていない.それでもLLMに蓄積された知識によってこうした訳文の修正ができるのである.
![図3 翻訳文修正例(入力文は文献[1]より引用)](/corporate/technology/rd/img/technical_journal/bn/vol32_4/004/image_004_03.png)
3.3 最終出力の調整
(1)要約
実際の翻訳シーンにおいて,2~3文が入力されるようなことはほとんどなく,資料が丸ごと翻訳にかけられることのほうが多い.英語で書かれた大量の資料を短時間で大まかに把握したいという場合,翻訳結果だけでなく,併せて要約も提供されると便利である.
tsuzumi軽量版は,パラメータサイズが70億(7B)であるが,zero-shotでの要約では13BサイズのLLMを超える性能を発揮することが確認されている.さらに,ファインチューニングをすることによって要約の性能が格段に向上する.
要約は,文書のタイプによって含むべき情報が異なるため,汎用の要約モデルではユーザのニーズを必ずしも満たさない.例えば,会議録とIR資料では注目すべき点は異なる.
学術論文の場合,すでに抄録が付与されていることがほとんどであり,それよりも内容を充実させることが求められる.医学系を中心とした一部の分野では,構造化された抄録が主流になっている.これは,MethodsやResultsなどの複数の章からなる抄録のことである.これを踏襲し,本文各章の内容をまとめ,構造化された要約を提供することが考えられる.tsuzumiに要約させる場合,ファインチューニングを行うことでより高い精度で要約できることが確認された.
(2)スタイル変換
同じ内容を伝える場合であっても,表現の仕方はさまざまであり,状況に応じて選択される.例えば,英日翻訳では,常体を用いるか敬体を用いるかは,文書タイプによって異なる.そして,それは原文の英語からは必ずしも判断できない.あるいは日英翻訳においても,より丁寧な表現にしたい場合や,より簡潔に書きたい場合がある.こうしたニーズに応えるのがスタイル変換である.
このスタイル変換は,ある種の翻訳とみなすこともできる.しかし,翻訳と同じ技術の枠組みを適用するためには,相当数の訓練データを用意しなければならない.さらに,あらかじめ決められたスタイルへの変換しかできなくなってしまう.
そこで,LLMを用いたスタイル変換に取り組んでいる.GPT-4oを用いた場合,大量の訓練データは不要であるだけでなく,指示を調節することでさまざまなスタイルへの変換ができる.例えば,「このたびは弊社イベントへ参加していただきありがとうございました.」をNMTで翻訳すると,「Thank you for participating in our event this time.」となるが,GPT-4oを使ってより丁寧な表現にすると,「I would like to extend my most sincere and heartfelt gratitude to you for taking the time out of your undoubtedly busy schedule to graciously participate in and contribute to the success of our event on this particular occasion.」となる.あるいは,SNS向けの短い表現にすると,「Thank you for joining our event!」となる.こうした微調整はLLMの得意とするところであり,目的に合わせて人手で翻訳結果を調整する労力を大幅に削減し得る.
- 翻訳モデル:翻訳前の言語と翻訳後の言語の各文章について,それぞれどの単語同士が意味的に対応するかを計算するために利用される統計モデル.
- 分類問題:あらかじめ用意された複数のカテゴリのいずれか1つまたは複数に,入力された文章を割り振るタスク.
- zero-shot:そのタスクの入出力の例示をLLMに対して一切行わずに当該タスクを解かせる設定.
- ドメイン:機械翻訳の利用シーンに相当するもの.
- 分類器:入力をその特徴量に基づいて,あらかじめ定められた分類先のいずれかに分類する装置.
04.あとがき
本稿では,tsuzumiによる翻訳の特性と,LLMを用いた次世代機械翻訳体験について解説した.tsuzumiによる翻訳については,より日本語らしい日本語を出力することや,段落構造を保持できることを示した.次世代機械翻訳体験については,翻訳にかかわる業務フロー全体を,LLMを用いて支援する枠組みについて,各機能を紹介した.一部機能については,GPT-4oのようなパラメータサイズの極めて大きなモデルによるものであるが,今後は次世代機械翻訳体験をより低コストで実現するため,次期バージョンのtsuzumiを用いた技術開発を進める予定である.
文献
-
[1] C. Mason:“Sunak cancels Greek PM meeting in Parthenon Sculptures row,” BBC,Nov. 2023.https://www.bbc.com/news/uk-politics-67549044

-
[2] 小西 友七, 南出 康世:“ジーニアス英和大辞典,”大修館書店,Apr. 2001.


