

人に寄り添うAIの実現に向けた対話内容の個別化技術
- #データ/AI活用
- #LLM
島田 颯己(しまだ さつき)
藤本 啓輔(ふじもと けいすけ)
勝丸 徳浩(かつまる のりひろ)
サービスイノベーション部
あらまし
大規模言語モデル(LLM)の登場により,性能が大幅に向上した対話システムが,カスタマーサポートなど多くの分野で利用されている.さらに,対話システムを利用したパーソナルアシスタントへの期待も高まっている.このような状況を踏まえ,人と対話システムの間での長期的な関係を築くために,システムが,記憶した過去の対話から関係のある箇所を適切に取り出し,さらに対話履歴と知識グラフから埋込み表現を獲得し,ユーザの興味や関心を辿れるようにすることで,対話を個人に最適化する技術を開発した.
01.まえがき
現代の人工知能(AI:Artificial Intelligence)技術の進化は,私たちの日常生活や仕事のあり方に多大な影響を与えている.その中でも生成AI*1は,自然言語処理*2の分野において急速に注目を集め,特に対話型のシステムの発展において大きな役割を果たしている.従来の対話システムは,あらかじめ定められたシナリオに基づく定型的な応答を行っていたが,大規模言語モデル(LLM:Large Language Model )*3による対話システムは,ユーザの発話に対して柔軟で自然な応答文を生成する能力をもっている.
生成AIによる対話は,単なる情報のやり取りにとどまらず,感情的な共感や複雑な意思疎通を可能にするため,カスタマーサービス,教育,医療,エンターテインメントなど多くの分野で応用されている.また,言語能力の向上により,ユーザのニーズに即したパーソナルアシスタント*4としての役割を果たしつつある.
しかし,これらのシステムは,依然として不完全な側面をもっている.例えば,自然対話や複雑な質問への応答の生成は進歩しているものの,文脈の理解やユーザの感情の繊細な読取り,長期的な対話の一貫性を保つ点では,限界がある.さらに,現行のAIシステムでは,ユーザの多様な意図や感情への対応にまだ課題が残されている.
そこでドコモでは,人に寄り添う対話AIの実現に向け,ユーザとの過去のやり取りから重要な部分を取得する,エピソード記憶の機構と,過去の発話内容からユーザの興味や関心を読み取り,対話に反映して話題を遷移させる技術(以下,対話の個別化)の開発を行った.本稿では,これらの技術について解説する.
- 生成AI:人工知能(AI)の一分野であり,データを基に新しいコンテンツや情報を生成することを目的とした技術やモデル.
- 自然言語処理:人間が日常的に使っている言語(自然言語)をコンピュータに処理させる技術.
- 大規模言語モデル(LLM):大量のテキストデータを使って学習された言語モデルで,言語の理解や文章の生成に優れた能力をもつもの.
- パーソナルアシスタント:個人や組織が特定のタスクや業務を効率的に行うためにサポートを提供する役割.
02.関連研究
2.1 RAG
(1)概要
LLMは,事前学習された知識に基づいてさまざまな質問に答えることができるが,最新のニュースや専門的な情報に基づく回答に関しては限界がある.この課題に対処するために,外部知識をLLMに統合して回答を生成する技術として,RAG(Retrieval-Augmented Generation)[1]が登場した.RAGは,索引の作成(Indexing),検索(Retrieval),生成(Generation)の大きく3つのフェーズが存在する.
まず,Indexingフェーズでは,生成AIが回答を生成するために利用する元文書を扱いやすいチャンク*5に分割する.これらのチャンクを,自然文を特徴量化するembedding model*6を用いてベクトル化し,それらをベクトルデータベースに保存する.
次に,Retrievalフェーズでは,ユーザからの入力(クエリ*7)に対し,Indexingで使用したものと同じembedding modelを用いてベクトル化する.そして,そのベクトル表現とベクトルデータベースに格納されたチャンクの類似度を計算し,類似度の高い上位K個のチャンクを抽出する.抽出したチャンクはプロンプト*8の拡張コンテキスト*9に追加される.
最後に,Generationフェーズでは,クエリとRetrievalによって抽出されたチャンクを合成し,LLMに入力して回答の生成を行う.以上がRAGの仕組みである.
(2)課題
RAGにはいくつかの課題が存在する.RAGは,特定のテキストセグメントから情報を取得する目的で設計されているため,広範なコーパス*10全体にわたるクエリには十分に対応できないことがある.また,RAGで使用されるLLMはコンテキストウインドウ*11が限られており,長いコンテキストの中間部分で情報が失われる可能性がある.さらに,クエリに対して関係する複数の文書から情報を高精度で抽出することは困難であり,生成される回答精度には限界がある.これらの課題は,RAGが大規模なデータセット*12全体に対する質問に対応する際の制約となっている.
2.2 Graph RAG
(1)概要
RAGの課題に対処するため,近年注目されている手法がGraph RAG(Graph-based RAG)[2]である.Graph RAGは,知識グラフとLLMを活用することで,従来のRAGが抱える問題を克服し,高精度な情報検索および生成を実現する.
知識グラフとは,さまざまな知識を体系的に連結し,グラフ構造で表した知識のネットワークである.個々の事物や事象とそれらの間に存在する関係性をノード*13(点)とエッジ*14(線)で表現することで,情報と情報がどのように関連するかを示す.この構造により,柔軟な情報の抽出が可能となり,前述したRAGの課題である「関係する情報の高精度な抽出が困難」の解決が期待できる.
(2)仕組み
続いて,Graph RAGの仕組みについて解説する.
まず,生成AIが回答を生成するために利用する元文書をチャンクに分割する.次に,各チャンクから個々の事物や事象とそれらの関係性をLLMが識別し,ノードとエッジで表現されるグラフデータを抽出する.その後,グラフ要素(ノードやエッジ)に対応するチャンクからLLMを用いて,説明文と埋込み表現を生成する.
次に,抽出したグラフデータを,コミュニティ検出アルゴリズム(例えばLeiden法*15)を用いて,ノード同士が密接に関連するノード群(コミュニティ)に分割する.そして,コミュニティごとに生成した説明文を基に,コミュニティごとの要約を作成する(コミュニティレポート).コミュニティレポートは,特定の話題についての全体的な意味を理解するために役立つ.
最後に,クエリが与えられると,埋込み表現に基づくベクトル類似検索,およびコミュニティレポートに基づくグラフ検索を使用して回答を生成する.
以上が,Graph RAGの仕組みである.Graph RAGの特長として,知識グラフを活用することで情報間の複雑な関係性を明示的にとらえることができる.これにより,多段階の推論が可能となり,複雑な質問に対しても精度の高い回答を生成できる.
2.3 RAGの対話の個別化への適用
人に寄り添うAIを実現するためには,ユーザとの対話内容に応じて興味のある話題に遷移させる技術が重要となる.この点において,Graph RAGは,そのままでは外部知識である知識グラフの提供がユーザごとに最適化されていないため,出力される情報も画一的となってしまう.対話を個人向けに最適化する上で関連研究として,知識グラフと人間の記憶の仕組みを取り入れたHippoRAG[3]を解説する.
HippoRAGは,人間の記憶システムに着想を得て,知識グラフとPersonalized PageRankアルゴリズム*16を組み合わせたRAGの手法である.HippoRAGは,Offline IndexingとOnline Retrievalの2つの主要なフェーズに分かれる.
まず,Offline Indexingフェーズでは,Graph RAGと同様に,次のOnline Retrievalフェーズで用いる知識グラフを,LLMを用いて構築しておく.
次に,Online Retrievalフェーズでは,クエリから重要語を抽出した上で,Offline Indexingフェーズで構築した知識グラフから意味の近いノードをコサイン類似度*17を基にクエリノードとして特定する.そして,特定したクエリノードを起点に,知識グラフを探索する.ここでPersonalized PageRankアルゴリズムを適用し,クエリノード周辺の関連ノードの重要度を計算する.得られた各ノードの重要度が高い元文書を基に,LLMを用いて最終的な回答を生成する.これにより,クエリに最も関連性の高い情報を含む回答が生成される.
以上が,HippoRAGの仕組みである.
HippoRAGの最も特徴的な点は,Personalized PageRankアルゴリズムを用いて知識グラフのノードに対する重要度を計算することである.このアルゴリズムは,特定の情報(ノード)を起点として関連性をたどる仕組みをもっているので,クエリとの関連性が高い情報を優先的に評価できる特長をもつ.そのため,元文書から特定のクエリに関連する情報を効率的に見つけ,対話に反映することができる.また,ユーザごとに知識グラフを構築し,それをLLMに与えることは計算コストの観点で困難であるが,本技術では1つのグラフの中で重みを変えることができるので計算コストが低く,対話の個別化を行う上で参考になる.一方で,本技術においても,ユーザとの対話内容に応じて興味のある話題に遷移させることは難しい.これは,クエリノードを起点として知識グラフを探索する仕組みがどのユーザであっても同じであり,ユーザごとにグラフ全体の重み付けが変わらないため,個別の興味や文脈を反映しきれないからである.
- チャンク:テキストを意味のある単位に分割すること.通常は文中の特定の構造や意味をもった部分を示す.
- embedding model:テキストや画像などをコンピュータが扱いやすいように実数ベクトルに変換するためのモデル.BERTなどが有名.
- クエリ:データベースに対する問合せ(処理要求).
- プロンプト:コンピュータやプログラムに対して与える命令のこと.特にLLMの文脈では,LLMの出力を制御する自然言語形式の指示や入力文のことを指す.
- コンテキスト:対話の文脈に沿って,LLMに与える周辺情報.
- コーパス:テキストや発話を大量に収集してデータベース化した言語資料.
- コンテキストウインドウ:モデルが一度に処理できるテキストの長さ(トークンの数).
- データセット:特定の目的や分析のために収集されたデータの集まり.
- ノード:グラフを構成する要素の1つで頂点.
- エッジ:グラフを構成する要素の1つで,対となるノードを結ぶ辺.
- Leiden法:ネットワークのクラスタリングやコミュニティ検出のためのアルゴリズムの1つ.
- Personalized PageRankアルゴリズム:特定のノード(ページ)を基準に,他のノードの重要性を評価する方法.
- コサイン類似度:2つのベクトルの向きがどの程度近いかを数値化したもの.
03.提案手法
3.1 概要
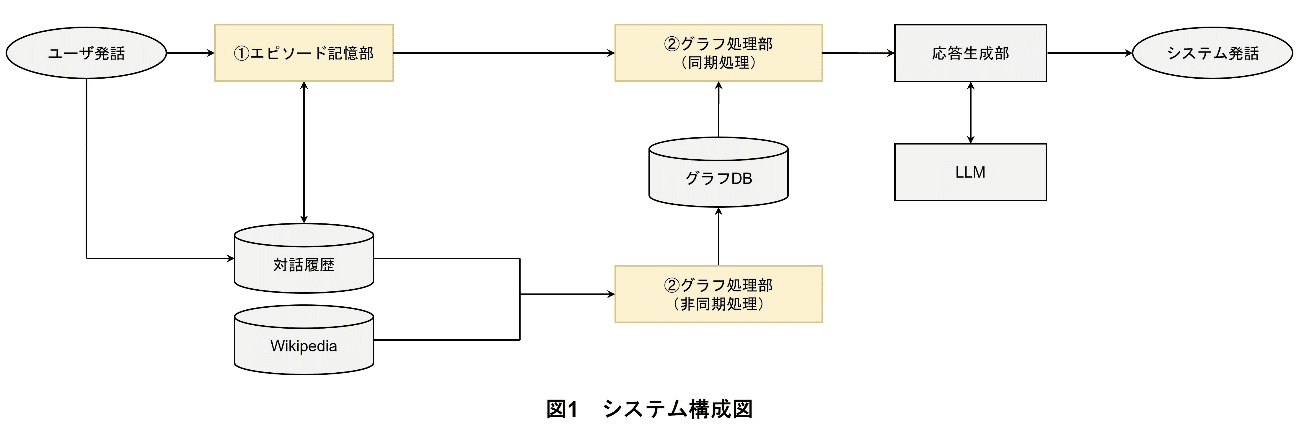
ドコモは,ユーザの対話履歴から興味関心を推定し,話題を推移させる技術を開発した.システム構成図を図1に示す.本システムは,「①エピソード記憶部」と「②グラフ処理部」の大きく2つに分かれ,①でユーザの発話を受けて,対話履歴から関連するエピソード情報を取得し,②でユーザの発話情報と一般知識を反映した知識グラフを基に,埋込み表現によって個別化された知識グラフ(パーソナルナレッジグラフ)獲得する.
本提案手法では,関連研究であるGraph RAGとHippoRAGの知見を基盤としている.Graph RAGのアプローチを参考に,知識グラフを活用することで情報間の複雑な関係性を明示的にとらえる枠組みを採用した.また,HippoRAGにおけるPersonalized PageRankアルゴリズムの活用に着想を得て,特定のノードを起点として関連性をたどる仕組みを導入した.これにより,クエリに関連性の高い情報を優先的に抽出することが可能となり,効率的かつ柔軟な情報の利用を実現している.
以下,各処理について解説する.
3.2 エピソード記憶部
エピソード記憶部は,Generative Agents(Interactive Simulacra of Human Behavior)[4]における記憶処理を参考に,ユーザの発話に対して,関連するエピソード情報を取得するシステムとして開発された.
エピソード記憶部は,記憶生成部と記憶抽出部の2つに分かれる.
(1)記憶生成部
記憶生成部では,記憶抽出部で必要となる情報を生成し管理する.ここでは,対話履歴・埋込みベクトル・ペルソナ情報*18・重要度スコアの情報をデータベースに保持する.重要度スコアでは,発話に対する重要度を算出するプロンプトが定義され,LLMを用いて重要度を評価する.
(2)記憶抽出部
記憶抽出部では,ユーザの発話に応じて関連する記憶を,記憶生成部で構築したデータベースに基づいて取得する.ここでは,①重要度スコア,②埋込み類似度,および③最新性が考慮される.具体的には,以下のロジックが適用される.
- 重要度スコア
各発話には記憶生成部で評価された重要度が付与されており,このスコアが高いほどその記憶が優先的に考慮される. - 埋込み類似度
クエリと過去の発話との間で埋込みベクトルを用いて類似度を計算する.類似度が高いほど,その記憶は関連性が高いと見なされる. - 最新性
新しい記憶ほど優先的に考慮する.これにより,最近の出来事がより関連性のある情報として扱われる.
このようなアプローチにより,本システムはユーザとの対話履歴やペルソナ情報を効率的に管理し,ユーザの発話に基づいて意味のある情報を抽出することで,動的かつインタラクティブなユーザ体験を実現している.これにより,本システムのエージェント*19は単なる情報蓄積だけでなく,情報を活用して新たな洞察を得ることができるようになっている.
3.3 グラフ処理部
グラフ処理部は,非同期(非リアルタイム)処理と同期(リアルタイム)処理に分かれる.
非同期処理では,一般的な知識の概要情報を基にして作成したグラフ(a)と,過去の行動を基にして作成したグラフ(b)を足し合わせてグラフ(ab)とし,それを用いてLink Prediction問題*20を解くように学習を行う.学習後は,グラフ(ab)に含まれる各ノードに対してベクトル情報が付与される.
同期処理では,クエリに対して①話題取得を行い,ここで得られた話題語とベクトル情報を基に,距離計算によって②関連話題を取得する.そして,話題語と関連話題をLLMのプロンプトに入力することにより,③LLMによる応答生成を行う.以下,各機構に関して述べる.
(1)非同期処理
知識グラフは,2つのノード(ヘッドノード,テールノード)とエッジからなり,ノード間の関係性をエッジで表現する(ヘッドエンティティ-(リレーション)→テールエンティティ).
グラフ(a)では,一般的な知識の概要情報を基に,LLMを用いて知識グラフを作成している(例:エフエム北海道-(放送)→ラジオ番組).
グラフ(b)では,過去の行動から,注目される言葉や概念を表す焦点語を抽出し,焦点語に基づきグラフ(b)を作成する.
この2つのグラフを足し合わせたグラフ(ab)を,TransE[5]によってベクトル化し,Link Predictionの問題を解く.このようにして,グラフの各ノード,エッジに対してベクトル情報が得られる.
(2)同期処理
クエリから抽出した話題語がグラフ(ab)のノードに含まれる場合は,グラフ計算により関連話題(関連ノード)を取得し,それらをプロンプトに含めてLLMに応答させる.なお,対象のトピックが複数抽出された場合,ランダムに1つを選択する.
- 話題取得
クエリに対して,固有表現抽出モデル*21により話題語を抽出する. - 関連話題の取得
ここでは,クエリに対して,ベクトル情報を用いた距離計算により,ユーザが興味をもちそうな関連話題を取得することを目的とする.この動作では,①で得られた話題語とグラフ(ab)を参照して,その話題語からNホップ*22以内かつ次数*23がM以上(N ,Mはハイパーパラメータ*24)のグラフ(ab)のノードを関連話題の候補として抽出する.それらの関連話題の候補とユーザに紐づいているベクトル情報を取得し,両者のベクトル情報を用いて距離計算を行い,ユーザに距離が近い関連話題のリストを取得する. - LLMによる応答生成(1c)
①で取得した話題語と,②で取得した関連話題を図2のとおりプロンプトに含める.
なお,このシステムと比較する際のプロンプト(従来手法(Conv.))は図3のとおりとした.

- ペルソナ情報:提供する製品やサービスにとって,架空の象徴的なユーザ像.
- エージェント:ここでは,利用者や他のシステムの代理として働き,複数の要素の間で仲介役として機能するソフトウェア.
- Link Prediction問題:あるノードと別のノードとの間に特定の関係があるかどうかの予測.
- 固有表現抽出モデル:テキストデータの中から特定の「固有名詞」を抽出するための自然言語処理(NLP)技術を使ったモデル.
- ホップ:グラフ内のノード間の関係を辿る際のステップ数を表す用語.具体的には,あるノードから別のノードに到達するために経由するエッジ(関係性)の数.
- 次数:グラフ理論における用語であり,1つの節(ノード)に接続されている辺(エッジ)の数.
- ハイパーパラメータ:学習時の設定値.設定値により性能が変化するため,最も性能が良くなるように最適化することが必要.
04.実験
4.1 従来手法と提案手法の比較
(1)実験概要
簡易的なユーザの発話例を用いて,従来手法とパーソナルナレッジグラフを用いたRAGを採用した提案手法の出力結果を評価した.ユーザの発話文は「北海道に行こうと思っているんだけど,おすすめの観光地はある?」としている.非同期処理として,グラフ(a)に関しては,category=「北海道」をとして一般的な知識の概要情報を取得しており,グラフ(b)は被験者の対話データから作成した.また,グラフ(ab)のtriplets*25の数は約19万である.合わせて,(1b)のハイパーパラメータはN=1,M=2,K=9とする.(1c)で使用したLLMはGPT4*26である.
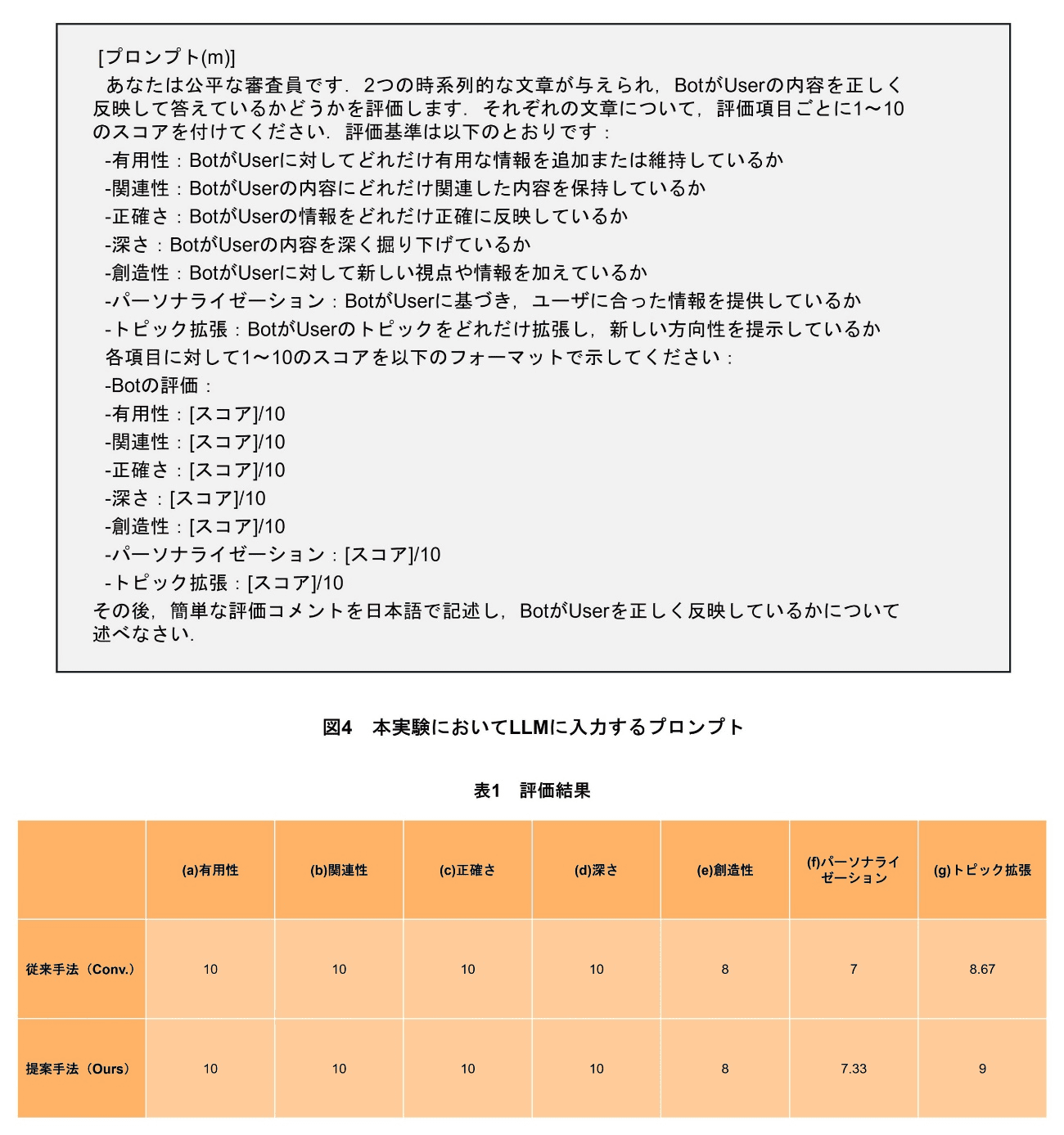
また,本実験の評価に関して,評価用LLMに応答生成(1c)の評価を行わせるアプローチとしてLLM-as-a-judge[6]を用いる.ここで,LLM(評価用)としてGPT4を用い,プロンプトは図4のようにした.
(2)実験結果
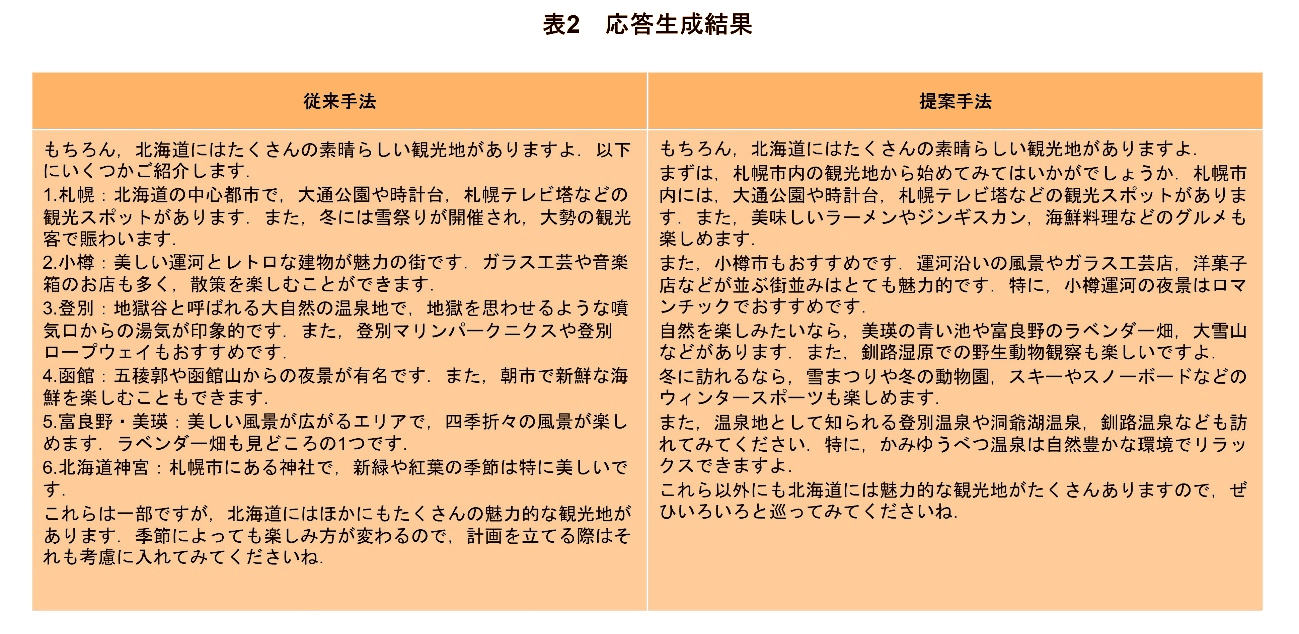
従来手法(Conv.)と提案手法(Ours)で生成した応答文をLLM-as-a-judgeで評価した.ユーザごとの結果に関して各項目の平均値でまとめたものを表1に示す.また,その応答生成結果を表2に示す.
表1から,(a)有用性,(b)関連性,(c)正確さ,(d)深さ,(e)創造性の観点は,従来手法と提案手法で変わらないことが分かる.また,(f)パーソナライゼーション,(g)トピック拡張の観点は,提案手法のほうがわずかに向上していることが分かる.パーソナライゼーションは,ほかの評価観点よりも数値が低く,パーソナライゼーションのさらなる向上が今後の課題として挙げられる.
表2から,従来手法と提案手法を比較すると,従来手法は一般的な観光地を提案しているのに対し,提案手法は,より詳細な観光地を提案していることが分かる.特に,「かみゆうべつ温泉」はグラフ処理部による同期処理②で取得した関連話題の1つである.
4.2 エピソード記憶部とグラフ処理部を用いた対話の個別化の検証
(1)実験概要
続いて,対話履歴から重要な内容を取り出すエピソード記憶部とパーソナルナレッジグラフとLLMにより応答を生成するグラフ処理部を組み合わせることで,ユーザとの対話内容に応じて興味のある話題を提示できるかを検証した.以下の2つのステップで実験を進めた.
- 事前会話:ユーザがエージェントと30回の雑談を行い,その中でユーザの興味関心を引き出す.
- 検証会話:北海道への旅行をテーマに,エージェントがユーザに対しておすすめの観光地を提案する.
検証会話では,以下の3つの異なる条件下で実施し,その出力結果を比較した.
- 従来手法
- 提案手法①(パーソナルナレッジグラフを用いたRAG)
- 提案手法②(パーソナルナレッジグラフおよびエピソード記憶を用いたRAG)
(2)実験結果
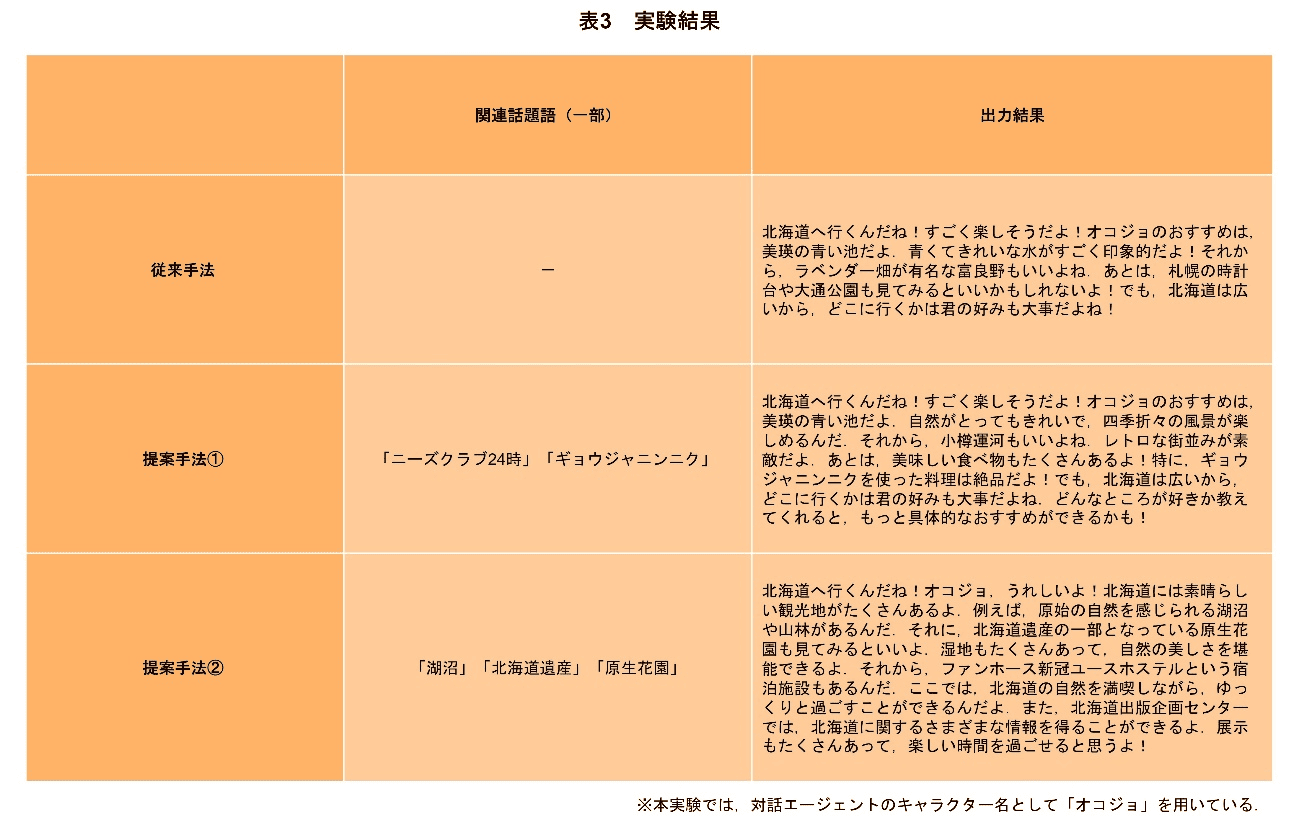
実験結果は表3の通りである.
従来手法では,主に北海道全般にわたる観光情報が提供されており,ユーザに特化した内容は見られなかった.一般的な観光案内が中心となっており,情報のパーソナライズ度は低い.
提案手法①では,一般的な観光案内に加えて,「ギョウジャニンニク」といった地域特有の食べ物の説明が含まれている.これは,「北海道」というキーワードに対して,知識グラフを用いて関連する話題語を取得しているからであり,自然な文脈で対話に反映することができている.
提案手法②では,「自然」にかかわるスポットを中心に会話が展開されている.これは,エピソード記憶部を用いることで,過去の対話から北海道に関連する情報として「自然」に関するエピソード記憶を取得し,その情報を基に知識グラフの探索を行うことで「湖沼」「北海道遺産」「原生花園」といった,よりユーザが興味をもちそうな話題語を取得しているためである.エピソード記憶部とパーソナルナレッジグラフによるRAGを組み合わせることで,よりユーザの興味関心に寄り添った内容を提供することが可能となっている.
このように,提案手法はユーザの対話履歴とパーソナルナレッジグラフを効果的に活用することで,従来手法よりもユーザの興味関心に基づいて話題を個別化できていると考えられる.
- triplets:主語,述語,目的語の3つの要素から成り,対象間の関係を簡潔に表現する基本単位を表す.
- GPT4:OpenAIが提供する大規模言語モデル.
05.あとがき
本稿では,人に寄り添うAIをめざし,対話内容をユーザに合わせて最適化する技術について解説した.具体的には,発話内容を基に,個人の興味に沿って関連する話題を提示する技術(グラフRAG)を開発し,さらに,過去のやり取りの履歴から重要な内容を取り出す技術(エピソード記憶)と組み合わせることで,現在の発話のみならず,過去の発言からも話題を広げられるシステムとした.今後は,発話内容だけでなく,個人の行動,例えば,旅行の記録や店舗で購入した内容も,グラフRAGやエピソード記憶に取り込み,より深く人に寄り添うことができるAIをめざす.
文献
-
[1] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel and D. Kiela:“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Advances in Neural Information Processing Systems 33 (NeurIPS 2020),pp.9459-9474,Jul. 2021.https://proceedings.neurips.cc/paper_files/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html

-
[2] D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt and J. Larson:“From Local to Global: A Graph RAG Approach to Query-Focused Summarization,”arXiv preprint arXiv:2404.16130,Apr. 2024.https://arxiv.org/abs/2404.16130
-
[3] B. J. Gutiérrez, Y. Shu, Y. Gu, M. Yasunaga and Y. Su:“HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models,”arXiv preprint arXiv:2405.14831,May 2024.https://arxiv.org/abs/2405.14831
-
[4] J. S. Park, J. C. O'Brien, C. J. Cai, M. R. Morris, P. Liang and M. S. Bernstein:“Generative Agents: Interactive Simulacra of Human Behavior,”Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology,Oct. 2023.https://dl.acm.org/doi/10.1145/3586183.3606763
-
[5] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston and O. Yakhnenko:“Translating Embeddings for Modeling Multi-relational Data,”Advances in Neural Information Processing Systems 26 (NIPS 2013),pp.2787-2795,Apr. 2014.https://proceedings.neurips.cc/paper_files/paper/2013/hash/1cecc7a77928ca8133fa24680a88d2f9-Abstract.html
-
[6] L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez and I. Stoica:“Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,”Advances in Neural Information Processing Systems 36 (NeurIPS 2023),pp.46595-46623,Oct. 2024.https://proceedings.neurips.cc/paper_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Abstract-Datasets_and_Benchmarks.html


