

LLM付加価値基盤を支える技術的取組み
- #データ/AI活用
- #LLM
白水 優太朗(しらみず ゆうたろう)
辰巳 守祐(たつみ しゅうすけ)
中村 一成(なかむら いっせい)
竹谷 謙吾(たけたに けんご)
黄 祺佳(こう きか)
郭 心語(かく しんご)
サービスイノベーション部
あらまし
ChatGPTの登場以降,大規模言語モデル(LLM)が世界的に注目されており,ビジネスシーンにおける活用も急速に進んでいる.ドコモにおいても,LLMを安全かつ便利に活用するための「LLM付加価値基盤」を開発し,ドコモグループ内へ提供している.本稿ではLLM付加価値基盤について概観するとともに,LLM付加価値基盤の性能改善や利用状況分析に向けた取組みとして,RAGの精度向上,UI/UXの改善,ダッシュボードの構築について解説する.
01.まえがき
生成AI*1が世界的な注目を集めている.特に,人間が行うようなテキスト生成や自然な対話を実現する技術である大規模言語モデル(LLM:Large Language Model)*2は,その性能の高さや幅広い業界・分野での利用可能性から,多くの企業で急速に導入が進んでいる.ドコモにおいても,業務効率化や新規事業創出を目的とした,LLM活用のための基盤「LLM付加価値基盤」を開発しており,ドコモグループ内に向けて提供中である[1][2].
企業内でLLMを有効に活用したりその活用シーンを拡大させたりするためには,LLMの単なる提供だけでなく,現場の需要を汲み取ったLLM利用のためのアプリケーションやツールの開発,利用促進をめざした使いやすいUI(User Interface)*3の設計・提供,社内ユースケースの発掘と水平展開など,基盤そのものや基盤周辺機能,基盤運用プロセスの継続的な改善が肝要である.
ドコモでは,ビジネスニーズが特に高いLLM関連技術の1つであるRAG(Retrieval-Augmented Generation)に,検索精度向上と社内運用効率化の両側面から取り組んでいる.RAGは,LLMによるテキスト生成を情報検索システムに活用することで検索・回答精度を高める技術であり,コンタクトセンタのオペレーション高度化やバックオフィスの業務効率化への貢献が大きく期待されている.LLM付加価値基盤では,社内ドキュメントの検索に対応したRAGを「オンライン文書検索」としてユーザへ提供しており,基盤を通じて,正確かつ有用な情報検索を可能としている.
また,LLM付加価値基盤の利便性向上に繋がる取組みとしては,現場へのインタビューや行動観察を通して得られた知見に基づく,独自UIの開発が挙げられる.LLM付加価値基盤の利用画面を,ユースケースに合わせた使い勝手の良いデザインとすることで,ユーザの定着や業務プロセスのさらなる効率化を狙っている.
さらに,ノウハウやナレッジ*4の蓄積,LLM活用方法の新規創出,組織ごとの利用状況把握,ならびにそれらの社内展開によるLLM付加価値基盤の活用拡大をめざし,LLM付加価値基盤のユーザ利用ログ収集パイプライン*5および可視化システム(ダッシュボード*6)を構築して社内ユーザ向けに公開している.
本稿では,ドコモが推進しているLLM付加価値基盤を支える技術的取組みについて,RAG,UI/UX(User Experience)*7,ダッシュボードの3つの観点から解説する.
- 生成AI:文章,画像,音楽,コードなどの新しいコンテンツを自動的に生成する能力をもつ人工知能技術.
- 大規模言語モデル(LLM):大量のテキストデータに基づいて機械学習により訓練された大規模な人工知能モデルのこと.ここでは特に,文脈を理解して人間らしい自然な文章を生成する能力をもつモデルを指す.
- UI:ユーザが操作する画面のデザイン,ボタン,アイコン,入力フィールドなどの要素のこと.
- ナレッジ:有用な知見や情報のこと.
- パイプライン:一連の手順に従ってデータを順次処理する仕組みのこと.
- ダッシュボード:グラフや統計データなどを使って,特定の指標やデータを一目で把握できるように視覚的に表示するインタフェースのこと.
- UX:ユーザがサービスを利用する際に感じる,使いやすさ,満足度,印象などを含む体験のこと.
02.RAG
2.1 検索精度向上に向けての取組み
(1)RAGアーキテクチャ*8
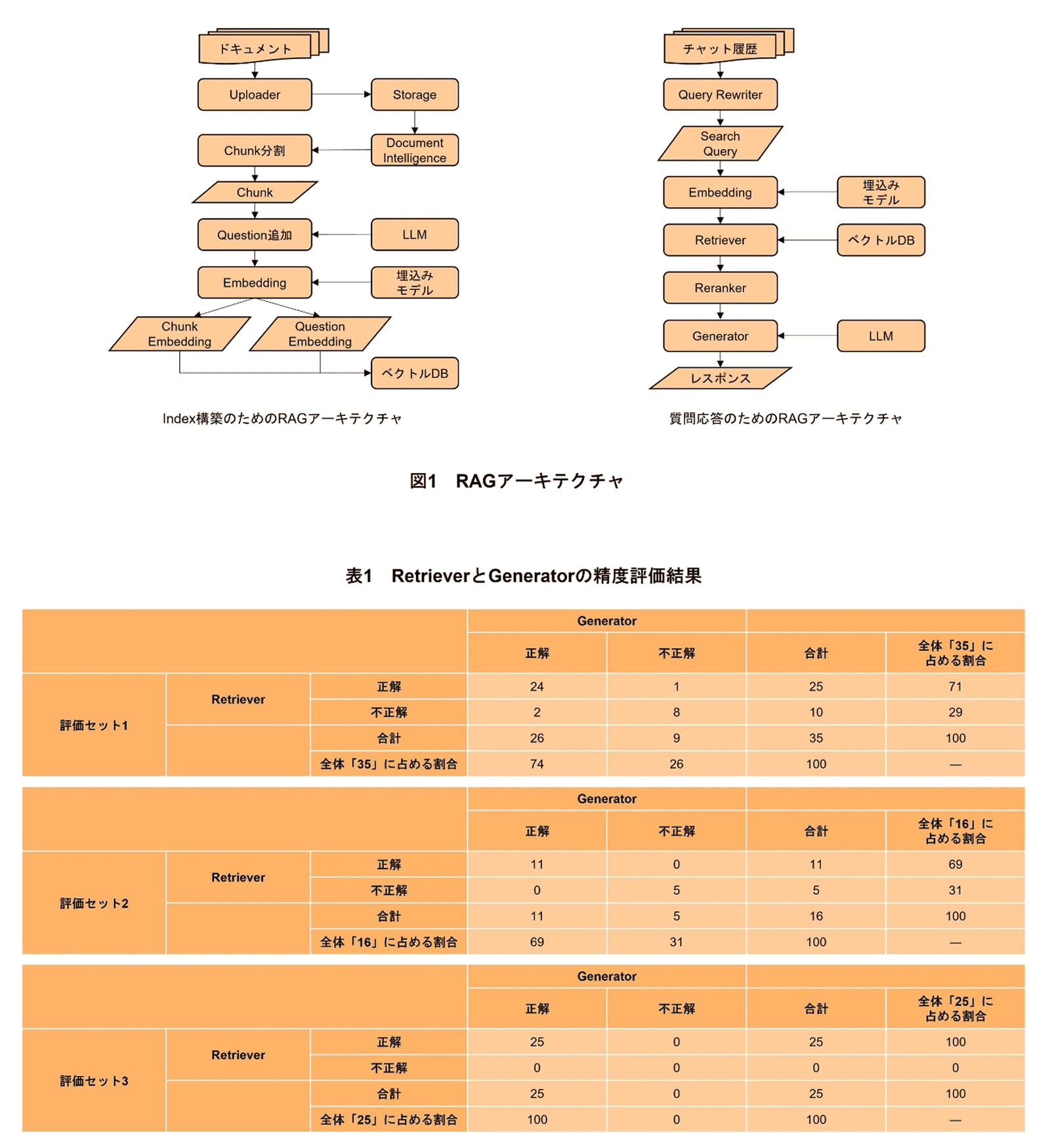
LLM付加価値基盤のRAGアーキテクチャは,ドキュメントを効率的に検索できるデータストアであるIndexの構築のためのアーキテクチャと質問応答のためのアーキテクチャの2つに大別できる(図1).
Index構築のためのアーキテクチャは,取込みを行うドキュメントをアップロードするUploader機能,ドキュメントから想定され得る質問を生成し,ドキュメントと紐づけてIndexに格納しておくことでRetriever(後述)の検索精度を向上させるQuestion追加機能,そして,ベクトル検索のために,チャンク*9や追加した質問をベクトル化してベクトルDB*10に保存するChunk/Question Embedding機能の3つで構成されている.
他方,質問応答のためのアーキテクチャは,検索精度を上げるためクエリ*11を拡張するQuery Rewriter機能,回答生成時に参照するドキュメントを検索するRetriever機能,Retrieverの出力結果を調整するReranker機能,そして,質問者に提示する回答を生成するGenerator機能の4つで構成されている.
(2)精度評価
(a)概要
RAGは,社内ドキュメントの検索やユーザ質問への回答といったビジネスユースを想定しているため,精度の高さが重要である.そこで,RAGの精度向上の取組みとして,質問応答にかかわる要素技術の精度評価を行った.
RAGは大きく分けて,関連ドキュメントを検索するRetrieverと,Retrieverの結果を受けて回答を生成するGeneratorの2つの要素技術で構成されている.これらの技術は直列処理になっており,先行するRetrieverの結果が不正解の場合,論理的には,後続するGeneratorの結果も不正解になる.そのため,最終出力であるGeneratorの結果を評価し,加えて精度低下の原因となり得る中間処理のRetrieverの結果も評価した.評価については,「おおむね正解」か「明らかに不正解」かの2段階で行い,マトリクスにまとめた.
(b)評価データセット
性能評価に向けて,社内業務マニュアルを基に3種類の評価データセットを作成した.評価データセット1および2は,1ドキュメント当り100ページ程度の複数のPDFドキュメントで構成されている.評価データセット3は,Microsoft Word,Microsoft PowerPoint,Microsoft Excel形式の十数個のドキュメントで構成されている.いずれの評価データセットも,参照ドキュメントと評価用Q&Aから構成されており,RAGの精度評価作業に際しては参照ドキュメントをRAGのIndexに登録することで評価用Q&Aとして評価を行った.
(c)評価結果
① RetrieverとGeneratorの精度評価結果
RetrieverとGeneratorの精度評価結果を表1に示す.
Retrieverの検索精度については,評価データセット1で71%,評価データセット2で69%,評価データセット3で100%であった.Generatorの生成精度については,評価データセット1で74%,評価データセット2で69%,評価データセット3で100%であった.また,評価データセットすべてを通して,Retrieverが正解していて,Generatorが不正解になっている事例は1件のみであった.この結果から,Retrieverが正解していれば,Generatorはおおむね正しい回答を生成できており,RAGのボトルネックはRetrieverにあることが分かった.これらの結果を踏まえ,ドコモではRetrieverの精度向上に注力している.
一方,Retrieverが不正解であったにもかかわらずGeneratorが正解した事例が評価データセット1内に2件見られた.このような事象は,GeneratorがRetrieverの出力内容ではなく,LLMの事前知識に基づいて回答した際に発生すると考えられる.そこで,この仮説が正しいことを確認するため,同じ評価データセットを使って,Generator単体の回答生成精度を評価したところ,評価データセット1では正答率57%,評価データセット2では6%,評価データセット3では42%となり,評価データセット1および3においては,Generator単体でも回答できるQ&Aが半分程度あることが分かった.実際,評価データセット1と評価データセット3については,一般常識やインターネットに公開されている情報も含まれており,実験結果との整合性がある.
② Query Rewriter,Reranker,Question追加の要素技術別評価
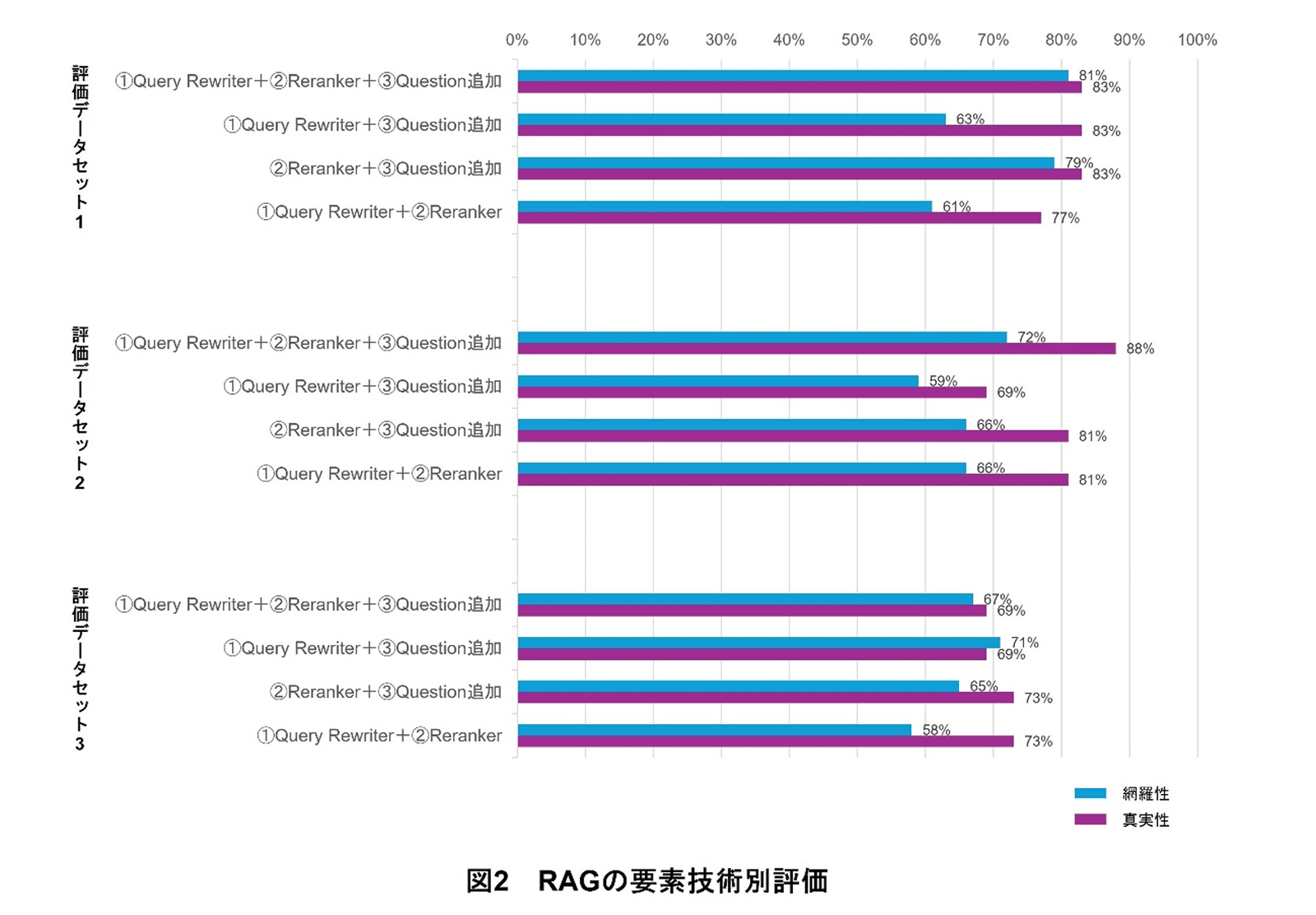
次に,Retrieverの精度向上のために実装した,Query Rewriter機能,Reranker機能,Question追加機能がどの程度精度向上に寄与しているのかを評価した.具体的には,3つすべての機能があるケース,いずれかが欠落しているケースの合計4ケースの精度を網羅性(必要な情報が網羅されている回答の割合)と真実性(ハルシネーション*12が無い回答の割合)の2つの評価を行い,結果を比較した(図2).
評価データセットによって,各要素技術の効果に差が見られた.具体的には,評価データセット1および2に対してはすべての機能があるケースにおいて精度が最も高く,いずれの要素技術も精度向上に寄与していることが分かるが,評価データセット3に対しては,全体的に精度の低下が見られた.このことから,ドキュメント形式ごとに適性の高い要素技術と低い要素技術があると考えられる.今後は,各要素技術が得意とするドキュメント形式の傾向を分析していくとともに,ドキュメント形式の種類に応じて,要素技術を柔軟に組み合わせて利用できるようなアーキテクチャの設計を検討していく.
2.2 社内運用の利便性向上
(1)適性度チェックシートの展開
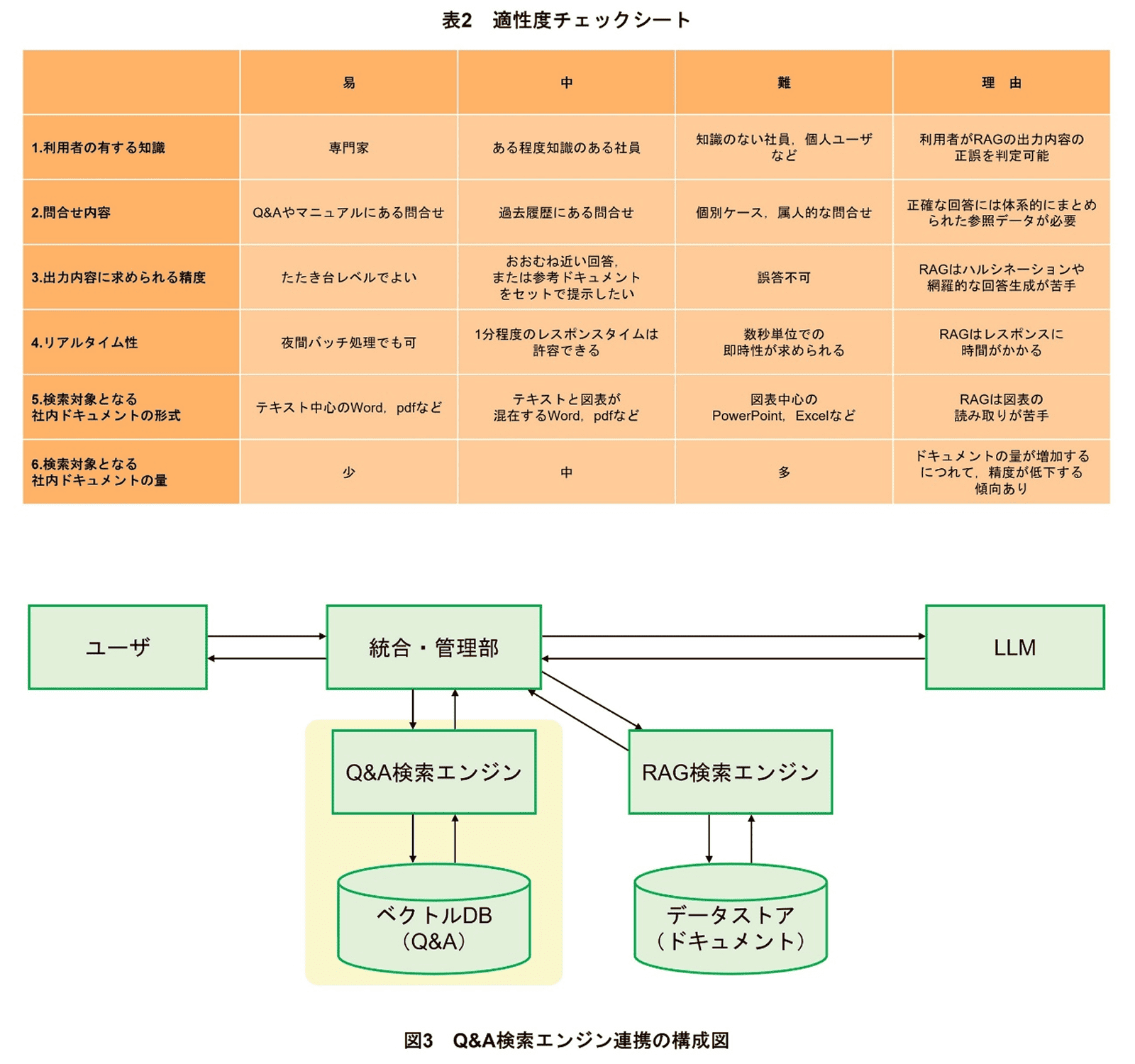
RAGは,LLMの活用における有用な技術として,特に現場に近い実務担当者から大きな期待を集めている一方,実際のビジネスの現場ではドキュメントが集まりづらかったり回答精度が上がりづらかったりして適用が難しい事例も少なくない.そこで,RAGの導入を検討している組織が自律的にRAGの導入是非の判断や導入対象業務の選定を行えるよう,「適性度チェックシート」を独自に作成して社内で配布している.
適性度チェックシートは表2に示すように,6つのチェック項目と易・中・難の3段階の導入難易度からなる適性度のマトリクスで構成されており,利用者は,自身の想定するユースケースをマトリクスの該当セルに当てはめていくことで,当該業務に対するRAGの適性度を確認できる.
(2)Q&A検索エンジンとの連携
十分な量のQ&Aデータを準備できるのであれば,基本的な情報や問合せ回数の多い質問に対しては,RAGでドキュメントやマニュアルを検索するよりもQ&Aデータを直接参照して回答するほうが正確かつ低コストな場合が多い.そこで,社内外向けの問合せ窓口を設けているなどにより大量のQ&Aデータを保有している部署との取組みにおいては,システム全体の精度向上を目的に,RAGアーキテクチャとQ&A検索エンジンとの連携を検討中である(図3).当初,RAGの参照ドキュメントとしてQ&Aを格納する方法も検証したが,精度が十分に上がらなかったため,Q&Aに最適化した方法でQ&Aを格納したベクトルDBと,これらを検索するためのQ&A検索エンジンを導入し,これらをRAGと連携させた運用を検討している.
Q&A検索エンジンとの連携の一環として,RAGの検索結果と同時にQ&A検索エンジンの結果を提示するGUI(Graphical User Interface)*13の作成も検討している.GUIイメージを図4に示す.Web検索のように,Q&A検索エンジンでヒットした類似質問とそれに紐づく回答を,関連する項目として提示する予定である.

- アーキテクチャ:システムの構成要素として何があるか,各構成要素がどのような機能・役割を与えられ,相互にどのように連絡をして全体として1つのシステムとして機能するか,に関する記述や取決めのこと.
- チャンク:名詞句や動詞句などの文節のように,テキストを意味のある小さな単位やかたまりに分割したもの.
- ベクトルDB:テキスト,画像,音声などのデータをベクトル化して扱う際に利用されるデータベースのこと.類似性検索や異常検知などのタスクにおいて,大量のデータに対しても高速かつ安定した動作を行うことが特長.
- クエリ:ユーザが検索エンジンやデータベースに対して入力する質問や問合せのこと.
- ハルシネーション:AIが,事実と異なる情報,あるいは実際には存在しない情報を生成する現象のこと.
- GUI:アイコンやボタンなど視覚的な要素を使って操作するインタフェースのこと.
03.UI/UX
3.1 カスタマージャーニー分析
ドコモでは,LLM付加価値基盤のユーザ定着や業務効率化,利便性向上を実現するためのUI/UXの改善の一環として,社内の多様な利用シーンを想定したGUIデザインを独自に作成し,提供中である(図5).
今回,これらの汎用的なGUIの提供に加え,特定のユースケースにマッチした専用GUIの新規作成と作成に向けたカスタマージャーニー分析*14を実施した.専用GUIを作成するユースケースとして,LLMによる大きな業務効率化が期待される「オンライン文書検索を用いた社内の事務処理に関する問合せ回答」を選定し,ユーザ(LLMを活用して,問合せに対する回答を検索・作成する作業者)の協力を得ながら次のような調査を行った.
まず,ユーザに対してアンケートを実施し,業務内容や作業頻度,ドキュメント検索を行う中で不便に感じている点,LLMを頼ることができそうな工程・LLMには任せられない工程などの確認を行った.次に,ユーザが実際に行っている業務の観察を行い,どのような流れでどのような動きをしているか,どのような工程に時間がかかっているかの確認を行った.最後に,ユーザインタビューを行い,ユーザが不満を感じており効率化したいと感じるポイントや,GUIとして必要な機能などの確認を行った.
これらの調査を通じて,「ユーザの問合せに回答する業務の習熟度により作業時間や作業プロセスが異なっており,特に習熟度の低いユーザにとってはLLMをうまく活用することで大きな業務効率化が見込めること」が明らかになった.また,LLMで往々にしてハルシネーションが発生することは,LLMをビジネスシーンで利用する上での課題の1つとしてよく知られているが,問合せに回答する業務での活用においては,ハルシネーションに起因する誤案内の防止が特に重要であるという示唆が得られた.
これらの結果から,ユーザのニーズに応え,業務効率化の実現やユーザの定着を図るためには,LLMを利用して回答するだけのシンプルな設計ではなく高度なUI設計が必要であると分かった.
3.2 分析に基づくデザイン作成
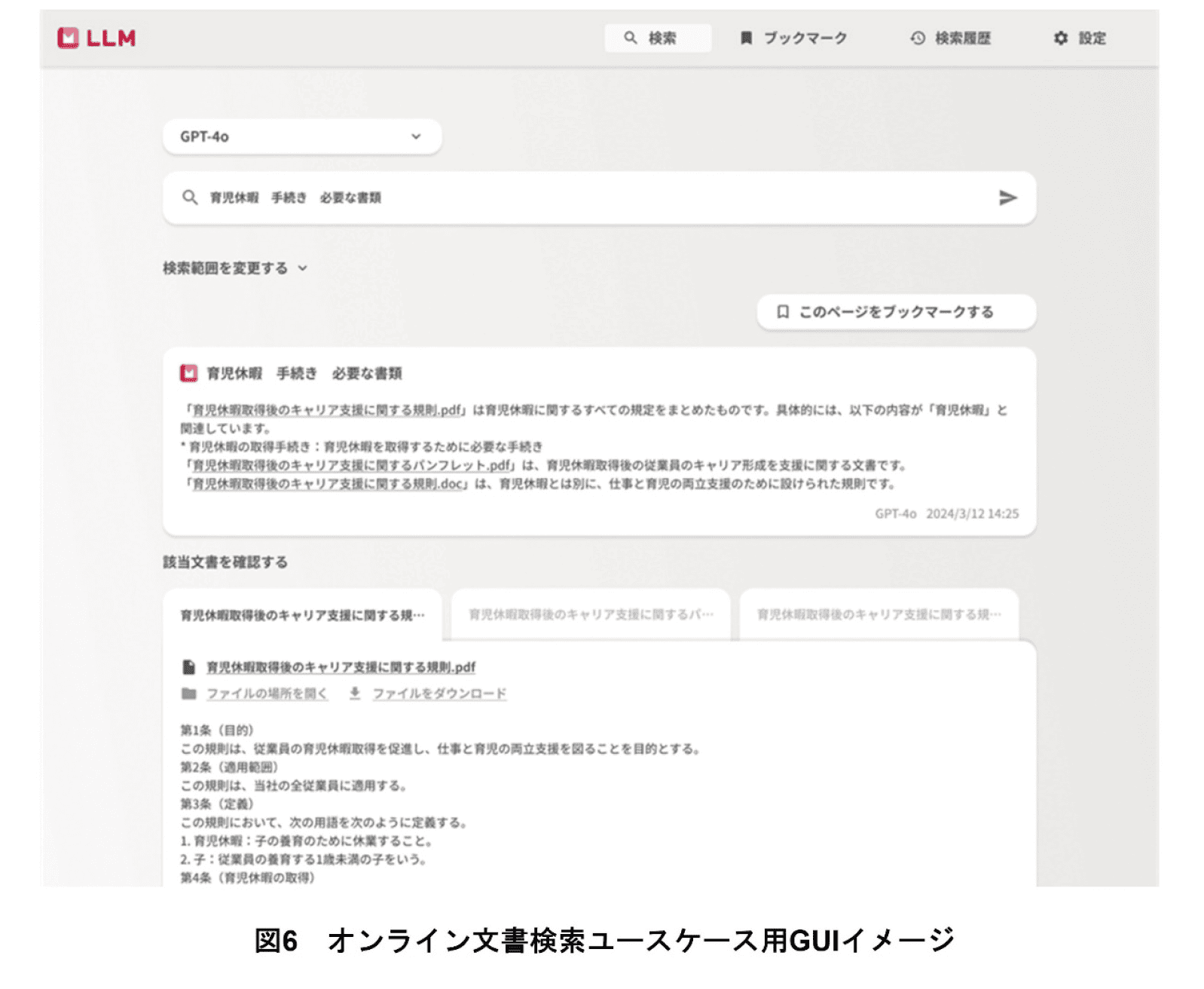
カスタマージャーニー分析から得られた知見を基に独自に開発したオンライン文書検索ユースケース用GUIを図6に示す.ユーザは,本専用GUIを通じて検索を実施し,マニュアルなどの文書を基にしたLLMの回答およびヒットした文書自体を確認することができる.
ユーザがLLMの回答の正しさを確認できるようにするため,オンライン文書検索ユースケース用GUIでは,LLMの生成した回答に加え,オンライン文書検索でヒットした文書が上位3件まで表示される,文書の一部だけでなく文書全体が表示される,ヒットした文書のダウンロードや元ファイルの場所を確認できる,ブックマークや検索履歴機能により別の検索条件の結果との比較を実施しやすくするなどの特長を備えている.
このように,特定のユースケースを想定した専用GUIを,通常のLLM利用の汎用GUIとは別に提供することで,ユーザのさらなる定着や業務プロセスの効率化をめざす.
- カスタマージャーニー分析:より良いユーザ体験の提供やユーザ満足度の向上を目的とし,ユーザが商品やサービスを知ってから使用するまでの一連のプロセスを詳細に解析する手法.
04.ダッシュボード
4.1 構築の背景
LLM付加価値基盤の利用状況をモニタリングすることは,基盤開発者によるサービスの継続的な改善や入力内容の監査,LLM活用推進担当者による施策の効果測定,LLMを活用した有用なユースケースのユーザ向け展開を行う上で重要である.LLM付加価値基盤のリリース当初は,定期的に手動で組織ごとのユーザ数やリクエスト数などの統計情報やLLMの主な活用事例のレポートを作成していたが,利用量の増加に伴いログが膨大になり,手作業での分析が非効率となった.このため,統計情報や,LLMで分析したユーザ活用事例などを自動的に可視化するダッシュボードを構築し,LLM付加価値基盤のユーザ向けに公開している.
4.2 可視化の概要
(1)ダッシュボードの構成
本稿執筆時点でのLLM付加価値基盤ダッシュボードは,「全期間統計情報」「週間利用傾向ランキング」「週間活用事例一覧」「週間ユーザプロンプト*15詳細」の4つのページから構成されている.なお,ダッシュボードはDatabricks[3]とMicrosoft社が提供するPower BI[4]を利用して構築している.
(2)全期間統計情報ページ
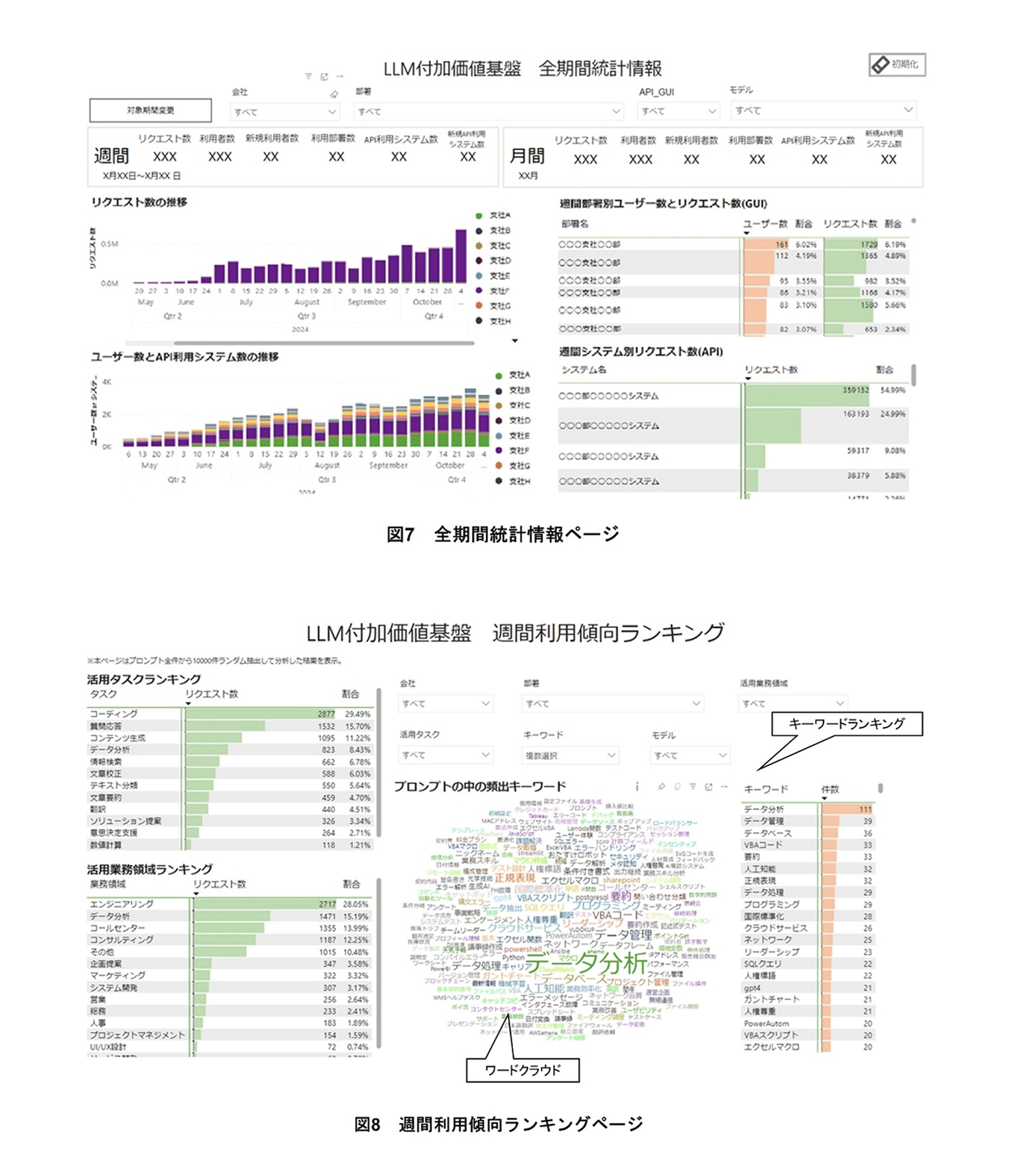
全期間統計情報ページは,利用会社部署ごとのユーザ数・リクエスト数などの統計情報をまとめたページである(図7).本ページを活用することで,LLM活用推進施策の実施や新機能のリリースなどの効果測定,経営層などのステークホルダーへの利用状況の迅速な報告などが可能である.加えて,リクエスト数の多い部署を把握して効果的な活用推進施策をインタビューしたり,ユーザ数の少ない部署を特定してLLM付加価値基盤の利用方法に関するハンズオン*16を実施したりといった,LLM付加価値基盤の活用推進にも役立てることができる.
各指標の統計値からは,直近の1週間および1カ月間の利用状況を確認できる(図7上).また,リクエスト数ないしユーザ数の推移グラフから,過去から現在までの状況を確認,また期間ごとに比較することなどができる(図7左下).部署別・システム別の統計情報からは,部署やシステムごとの直近の1週間のユーザ数・リクエスト数をランキング形式で確認できる(図7右下).レポート全体の対象期間は,「対象期間変更」から設定でき,特定期間の統計情報を閲覧することが可能である(図7上).
(3)週間利用傾向ランキングページ
週間利用傾向ランキングページは,ユーザがLLM付加価値基盤をどのようなタスクや業務領域で活用しているかをまとめたページである(図8).本ページを活用することで,部署ごとまたはLLMのモデルごとに,活用されている主なタスクや業務領域を大局的に把握できる.加えて,経営層などの関係者・関係組織に向けてユーザの活用タスクと業務領域を報告したり,各ユーザがほかの社員の活用内容を把握したりすることで,自身の業務へのさらなるLLM活用を推進できる.
グラフからは,ユーザの活用タスクと活用業務領域をランキング形式で把握できる(図8左).データは,各ユーザのプロンプトをLLMで分類した結果に基づいている.LLMに与えるプロンプトは,活用タスクであれば「コーディング」「コンテンツ生成」,業務領域であれば「コールセンター」「コンサルティング」といったように,それぞれあらかじめ定義されたカテゴリへ分類されるよう設計している.
ワードクラウド*17とキーワードランキングからは,ユーザの入力プロンプトから抽出した頻出キーワードを定性的・定量的に把握できる(図8右).このとき,LLMによるプロンプトの分析は費用がかかることから,過去の全プロンプトからランダムに抽出した一部のプロンプトをLLMで分析してダッシュボードに表示している.
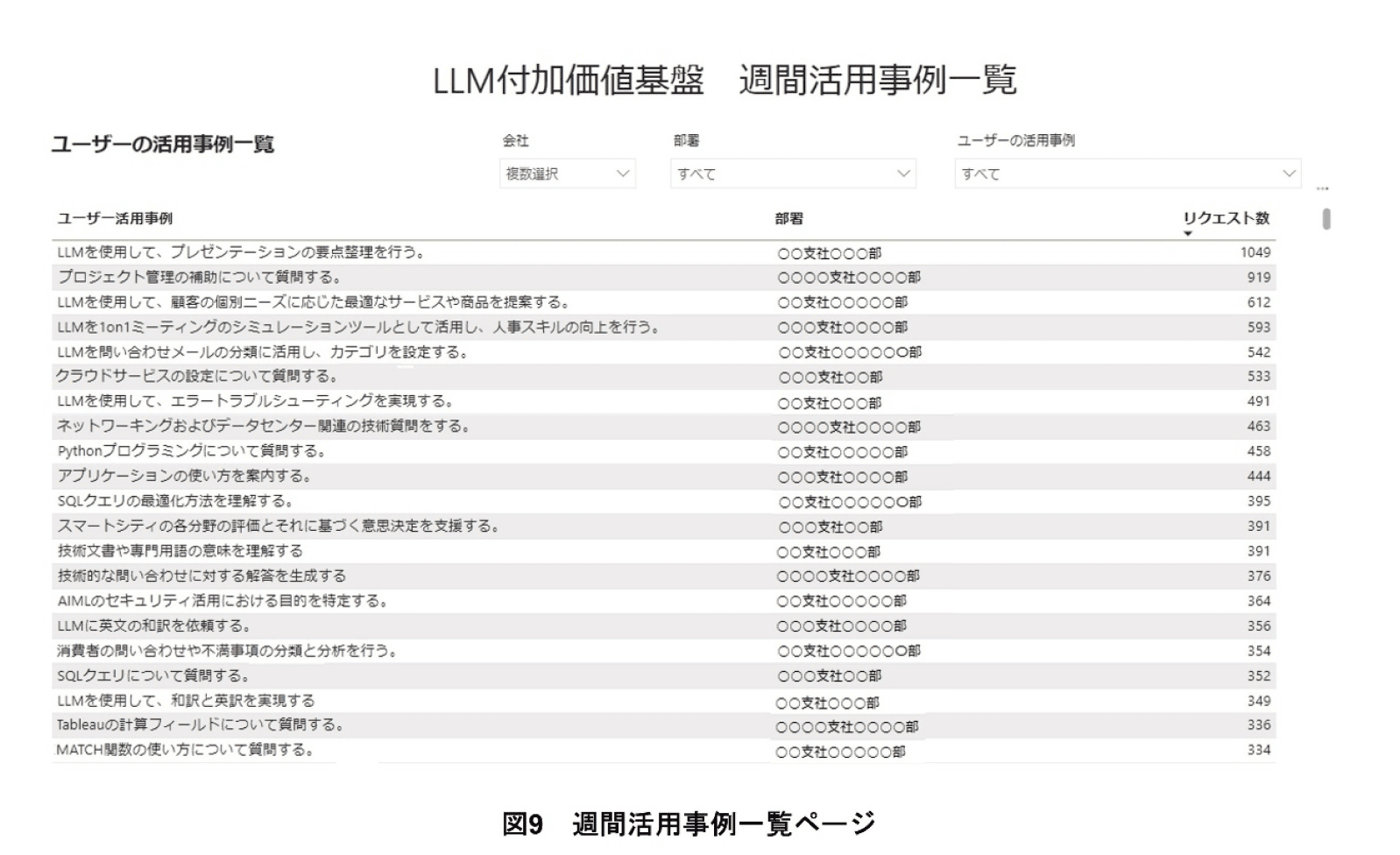
(4)週間活用事例一覧ページ
週間活用事例一覧ページは,LLMの主な活用事例やリクエスト数をユーザごとに可視化したページである(図9).本ページを通じて,ユーザがほかの社員のLLMの活用状況を把握することで,自身の業務へのさらなる活用を推進することができる.
週間活用事例一覧ページは,週間利用傾向ランキングページと同様にLLMを活用し,ユーザ全体の過去のプロンプトから主なLLM活用事例を抽出・要約した結果を表示している.例えば,「タイムスケジュールを作成する」「プログラムを修正する」「問合せへの回答文を作成する」「メールの文体調整を行う」などが実際に要約された結果である.LLMによる要約の際には,各プロンプトの全テキストを入力するのではなく,指示文が書かれることが多い冒頭のテキストのみを用いることで,全テキストを用いるよりも低コストに要約処理を行っている.
(5)週間ユーザプロンプト詳細ページ
週間ユーザプロンプト詳細ページは,ユーザのプロンプト内容を閲覧できるページである.本ページは,LLM付加価値基盤やダッシュボードの開発者のみに限定して公開している.
週間活用事例一覧ページで分析した各ユーザの活用事例は本ページにも表示されており,該当の活用事例を選択することで,実際のプロンプトを閲覧することができる.
本ページを活用することで,事業推進に資する有用な活用事例をプロンプト集やナレッジとして蓄積,またプロンプトに重大な秘匿情報や入力が禁止されている情報が含まれていないかを監査することなどができる.
- プロンプト:モデルに特定のタスクを実行させるために入力されるテキストのこと.
- ハンズオン:実際に手を動かして行う実習形式の学習やトレーニングのこと.
- ワードクラウド:単語の出現頻度を文字の大きさで表示する可視化手法で,文字が大きいほど出現回数が大きいことを表す.
05.あとがき
本稿では,LLM付加価値基盤を支える技術的取組みとして,(1)業務効率化やプロセス変革を志向したRAGの検索精度向上と運用効率化の取組み,(2)基盤の利便性向上と利用拡大に繋がるUI/UXの実装・提供,(3)ユースケースの新規創出とLLM活用ノウハウ蓄積に向けたダッシュボード構築の3点について解説した.企業内でLLMを活用したりLLM活用のための基盤を展開したりするにあたっては,先進的技術の調査や実装のみならず,利用者にとって安全か,便利か,有用かなど多岐にわたる観点から常に検証と改善が重要である.多種多様な社内データに対応できる堅牢なアーキテクチャの設計や処理フローの検討,現場での利用実態の把握などを通じて,LLM付加価値基盤の活用推進に貢献していく.
今後の展望として,(1)RAGにおいては精度改善と運用効率化の両輪を回し,ユーザ数の拡大と利用継続率の向上を図る,(2)UI/UXにおいてはユーザからの評価や要望を継続して収集し,各種機能を改善するとともに効果的なユースケースに対する専用UIを作成・提供する,(3)ダッシュボードにおいては高度な分析を可能とする可視化機能の追加や,業務改善効果を測定できるアルゴリズムの開発を通じ,有用性の高いユースケースの発掘をめざす.
文献
-
[1] NTTドコモ報道発表資料:“生成AIを活用した業務のDX推進および付加価値サービス提供に向けた実証実験を開始 ~生成AIの安全性と利便性の向上をめざす「LLM付加価値基盤」を開発~,”Aug. 2023.
 https://www.docomo.ne.jp/binary/pdf/corporate/technology/rd/topics/2023/topics_230821_00.pdf(PDF形式:808KB)
https://www.docomo.ne.jp/binary/pdf/corporate/technology/rd/topics/2023/topics_230821_00.pdf(PDF形式:808KB)
-
[2] 駒田,ほか:“ビジネスの現場に寄り添うLLM基盤技術,”本誌,Vol.32,No.1,Apr. 2024.https://www.docomo.ne.jp/corporate/technology/rd/technical_journal/bn/vol32_1/001.html
-
[3] Databricks:“データとAIの企業.”
 https://www.databricks.com/jp
https://www.databricks.com/jp
-
[4] Microsoft:“Power BI.”https://www.microsoft.com/ja-jp/power-platform/products/power-bi


